论文解读(BSFDA)《Black-box Source-free Domain Adaptation via Two-stage Knowledge Distillation》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文信息
论文标题:Black-box Source-free Domain Adaptation via Two-stage Knowledge Distillation
论文作者:Shuai Wang, Daoan Zhang, Zipei Yan, Shitong Shao, Rui Li
论文来源:2023 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
动机:无源域自适应的目标是仅使用预先训练过的源模型和目标数据来适应深度神经网络。然而,访问源模型仍然存在泄漏源数据的潜在问题。在本文中,研究了一个具有挑战性但实际的问题:黑盒无源域自适应,其中只有源模型和目标数据的输出可用;
方法简介:提出了一种简单而有效的两阶段知识蒸馏方法。在第一阶段,用源模型以知识蒸馏的方式对源模型生成的软伪标签从头开始训练目标模型。在第二阶段,初始化另一个模型作为新的学生模型,以避免噪声伪标记引起的误差积累;
2 相关
SFDA 存在的问题:
-
- 可以使用生成模型[10,11]来恢复源数据,可能会引发潜在的数据安全问题;
- 通常会调整源模型的参数,所以目标模型必须使用和源模型相同的方法网络架构作为模型,这对于低源目标用户,即一些社区医院是不现实的;
3 方法
模型框架
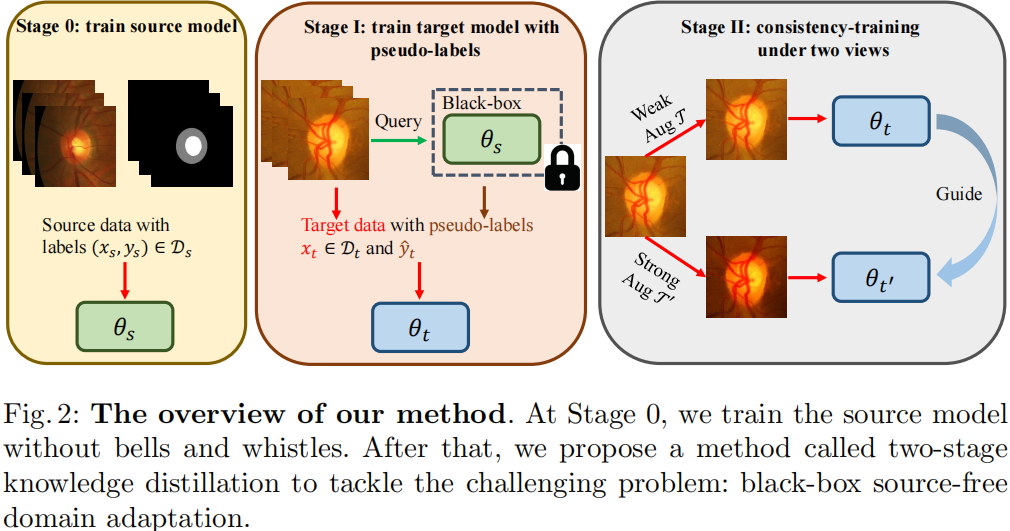
对比:
-
- UDA: 源数据(√)、源模型(√)
- SFDA: 源数据(×)、源模型(√)
- BSFDA:源数据(×)、源模型(×)
注意:BSFDA 是通过源域数据预训练好源模型,然后可以通过 API 的形式输入数据到云端源模型(Black-box)得到输出;
3.1 源模型训练
源域数据训练源模型,交叉熵损失:
$\mathcal{L}_{s}=-\mathbb{E}_{\left(x_{s}, y_{s}\right) \in \mathcal{D}_{s}} y_{s} \log f_{s}\left(x_{s}\right)$
注意:在此之后,就无法访问源模型和源数据,只能利用源模型的输出;
3.2 两阶段知识蒸馏
对于目标域数据 $x_t$,可以使用带有开放 API 的黑盒源模型 $f_s$ 得到软伪标签 $\hat{y}_{t}=f_{s}\left(x_{t}\right)$。
训练目标模型的一个简单策略是使用具有交叉熵损失的伪标签 $\hat{y}_{t}$ 的自训练,但是使用这种伪标签存在的问题:
-
- 由于源域和目标域之间的分布位移,伪标签不可避免地成为噪声;
- 伪标签被冻结,因为在源训练后无法更新源模型;
在第一阶段,使用软伪标签而不是硬标签从头开始训练目标模型 $f_t$ ,目的是从源域获取更多的帮助知识;
在第二阶段,另一个模型被随机初始化,以避免错误积累。然后,使用弱数据增强下的伪标签来指导强增强图像的学习;
第一阶段
在这个阶段,使用知识蒸馏[12]从源模型中精确提取知识:
$\mathcal{L}_{1}=D_{\mathrm{KL}}\left(\hat{y}_{t} \| f_{t}\left(x_{t}\right)\right)$
使用软标签的好处:
-
- 软标签可以提供来自源模型的知识[12];
- 对于域外数据,软伪标签比硬伪标签工作得更好;
方法具有一定的效果,但模型 $f_t$ 是在有噪声和固定标签 $f_t$ 的目标域上进行训练的,这对目标域是次优的。因此,利用第二阶段来增强训练的模型 $f_t$ 依赖于知识蒸馏之间的两个图像。
使用预训练模型初始化另外一个模型 $f_{t^{\prime}}$,对目标域数据分别进行 弱、强数据增广 $\mathcal{T}\left(x_{t}\right)$、$\mathcal{T}^{\prime}\left(x_{t}\right)$。将弱增强图像 $\mathcal{T}\left(x_{t}\right)$ 输入 $f_{t}$,得到伪标签 $\hat{y}_{t}^{\prime}=f_{t}\left(\mathcal{T}\left(x_{t}\right)\right)$。之后,使用 $\hat{y}_{t}^{\prime}$ 来指导输入强增广数据 $\mathcal{T}^{\prime}\left(x_{t}\right)$ 的模型 $f_{t^{\prime}}$ ,因为弱增广数据通常会产生更可靠的伪标签。
$\mathcal{L}_{2}=D_{\mathrm{KL}}\left(\hat{y}_{t}^{\prime} \| f_{t^{\prime}}\left(\mathcal{T}^{\prime}\left(x_{t}\right)\right)\right)$
最后,得到了用于评估的目标模型 $f_{t^{\prime}}$。
3 实验
分类结果
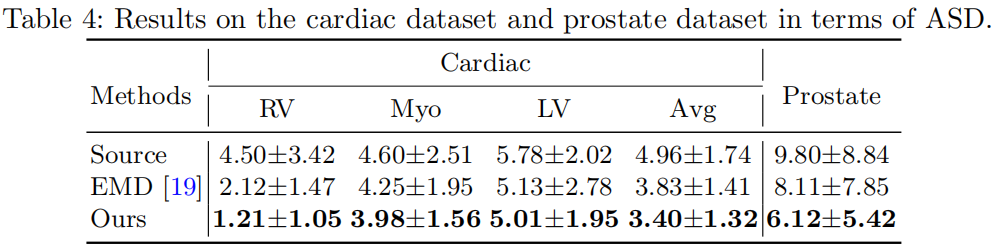
数据集太小了,baseline太少,不做评价;
因上求缘,果上努力~~~~ 作者:图神经网络,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17647340.html

