论文解读(KD-UDA)《Joint Progressive Knowledge Distillation and Unsupervised Domain Adaptation》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文信息
论文标题:Joint Progressive Knowledge Distillation and Unsupervised Domain Adaptation
论文作者:Yanping Fu, Yun Liu
论文来源:2021 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
动机:知识蒸馏+DA
2 方法
模型框架
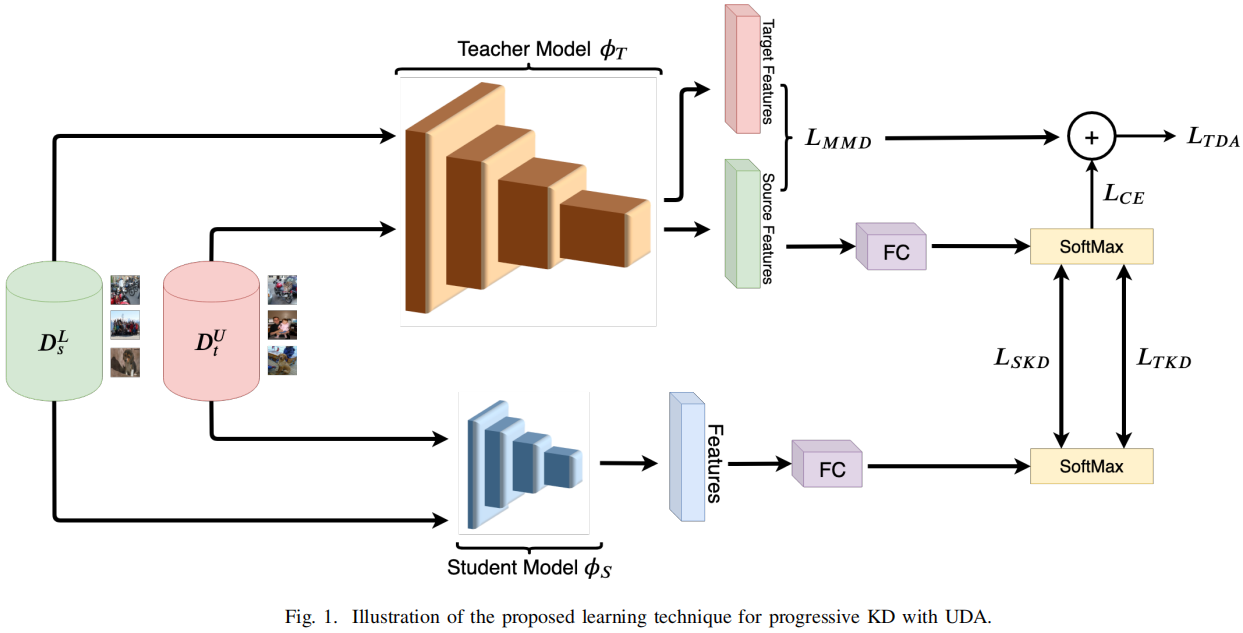
2.1 域适应
教师网络DA:
$\mathcal{L}_{T D A}=\mathcal{L}_{M M D}+\gamma \mathcal{L}_{C E}\left(T\left(D_{s}^{L}, 1\right), y_{s}\right)$
$\mathcal{L}_{M M D}=\left\|\frac{1}{N_{s}} \sum_{x_{i} \in D_{s}^{L}} \phi_{T}\left(x_{i}\right)-\frac{1}{N_{t}} \sum_{x_{j} \in D_{t}^{U}} \phi_{T}\left(x_{j}\right)\right\|_{\mathcal{H}}^{2}$
其中,$\phi_{T}$ 是教师网络特征提取器;
2.2 知识蒸馏
训练目标:
$\mathcal{L}_{T K D}=\mathcal{L}_{\text {distill }}\left(S\left(D_{t}^{U}, \tau\right), T\left(D_{t}^{U}, \tau\right)\right)$
$\mathcal{L}_{S K D}=\mathcal{L}_{\text {distill }}\left(S\left(D_{s}^{L}, \tau\right), T\left(D_{s}^{L}, \tau\right)\right)+\alpha \mathcal{L}_{C E}\left(S\left(D_{s}^{L}, 1\right), y_{s}\right)$
2.3 优化目标
一开始,老师仍然在向 $\text{DA}$ 学习,意味着除了可以从 $\text{KD}$ 损失中学习的源表示之外,学生模型没有什么需要学习的东西。鉴于此,建议在一开始给予 $\text{UDA}$ 更重要的重要性,并逐渐将重要性转移到 $\text{KD}$。
总体训练目标:
$\mathcal{L}=(1-\beta) \mathcal{L}_{T D A}+\beta\left(\mathcal{L}_{T K D}+\mathcal{L}_{S K D}\right)$
其中:
$\beta_{t}=b * e^{g t}$
$g=\frac{\log \left(\frac{f}{b}\right)}{\text { epochs }}$
Note:$t$ 代表当前 $\text{epoch}$,$\text{b}$ 为起始值,$\text{f}$ 为结束值;
算法:

3 实验
检测 UDA 和 DK:
-
- 1) DA, and then KD:先在源、目标域做 UDA,然后再在目标域做 知识蒸馏;[ 猜测:一个特征提取器+2个分类器 ]
- 2) KD, and then UDA:教师学生模型先进行 KD,然后在学生模型进行 UDA;
- 3) UDA directly on compact model:训练一个学生模型只使用 UDA ;
UDA 分类

因上求缘,果上努力~~~~ 作者:图神经网络,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17646952.html

