论文解读(SentiX)《SentiX: A Sentiment-Aware Pre-Trained Model for Cross-Domain Sentiment Analysis》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文信息
论文标题:SentiX: A Sentiment-Aware Pre-Trained Model for Cross-Domain Sentiment Analysis
论文作者:Jie Zhou, Junfeng Tian, Rui Wang, Yuanbin Wu, Wenming Xiao, Liang He
论文来源:2020 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
出发点:预先训练好的语言模型已被广泛应用于跨领域的 NLP 任务,如情绪分析,实现了最先进的性能。然而,由于用户在不同域的情绪表达的多样性,在源域上对预先训练好的模型进行微调往往会过拟合,导致在目标域上的结果较差;
思路:通过大规模评论数据集的域不变情绪知识对 SENTIX 进行预训练,并将其用于跨领域情绪分析任务,而无需进行微调。具体:本文提出基于标记和句子级别的词汇和注释的预训练任务,如表情符号、情感词汇和评价得分,而不受人为干扰;
预训练模型在跨域情感分析上存在的问题:
-
- 现有的预训练模型侧重于通过自监督策略学习语义内容,而忽略了预训练短语的情绪特定知识;
- 在微调阶段,预训练好的模型可能会通过学习过多的特定领域的情绪知识而过拟合源域,从而导致目标域的性能下降;
贡献:
-
- 提出了 SENTIX 用于跨域情绪分类,以在大规模未标记的多域数据中学习丰富的域不变情绪知识;
- 在 Token 水平和句子水平上设计了几个预训练目标,通过掩蔽和预测来学习这种域不变情绪知识;
- 实验表明,SENTIX 获得了最先进的跨领域情绪分析的性能,并且比 BERT 需要更少的注释数据才能达到等效的性能;
2 方法
2.1 模型框架
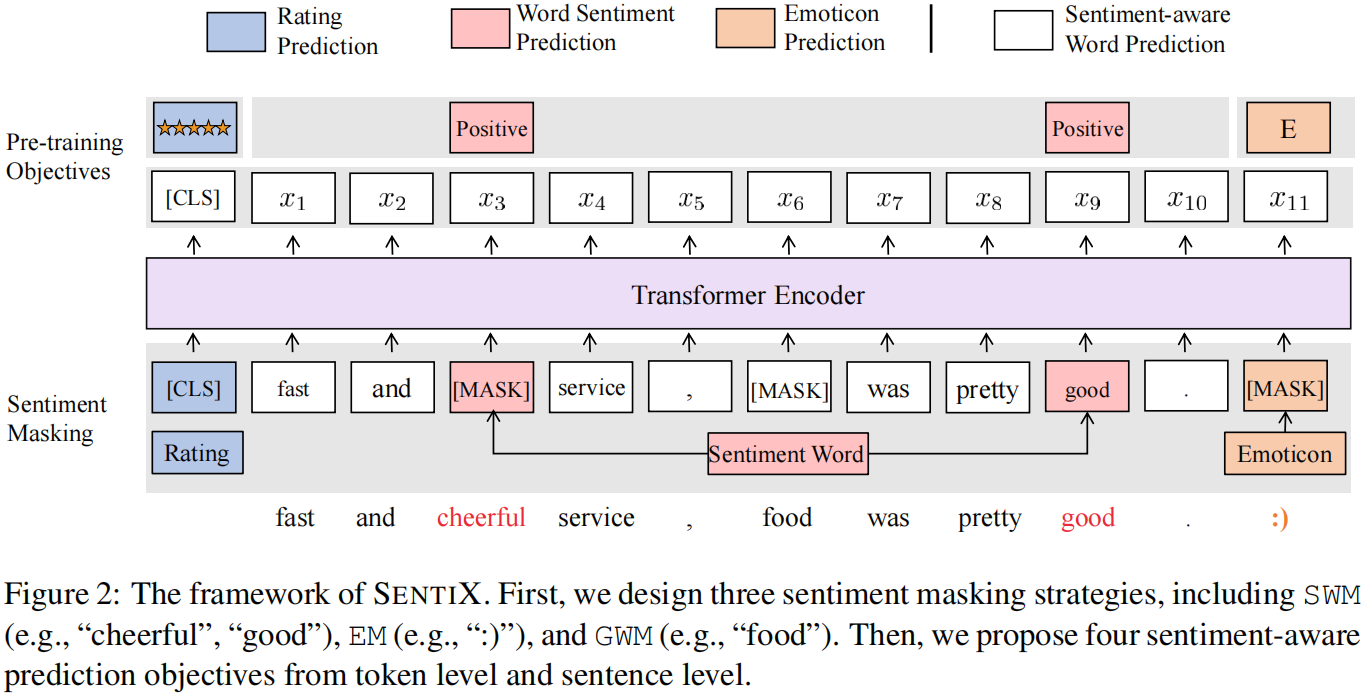
2.2 Sentiment Masking
评论包含情绪信号,如 情绪词汇、表情符号 和 评级,而大规模的评论数据可以从在线评论网站上获得。
-
- 情绪词汇(Sentiment Words):积极(P),消极(N),其他(0);
- 情感符(Emoticons):用于表示用户情感符号,如(")"、"("、":"、"D"),本文选择语料库中经常出现的 100 个特殊符号作为情感符,并将其标记为 “E”,其他为 “0”;
- 评分(Rating):情绪评分分为 5 个等级;
策略:
- Sentiment Word Masking (SWM):为丰富情绪信息,用 30% 的比率掩盖情绪词;
- Emoticon Masking (EM):由于句子中的情感符号数量相对较少,并且删除情感符号不会影响句子的语义信息,所以为每个句子屏蔽了 50% 的情感符号;
- General Word Masking (GWM):如果只关注情感词和表情符号,模型可能会失去其他单词的一般语义信息。因此,使用 [MASK] 并用 15% 的比率替换句子中的一般单词来学习语义信息;
2.3 Pre-training Objectives
Sentiment-aware Word Prediction (SWP)
$P\left(x_{i} \mid \hat{x}_{i}\right)=\operatorname{Softmax}\left(W_{w} \cdot h_{i}+b_{w}\right)$
$\mathcal{L}_{w}=-\frac{1}{|\hat{\mathcal{X}}|} \sum_{\hat{x} \in \hat{\mathcal{X}}} \frac{1}{|\hat{x}|} \sum_{i=1}^{|\hat{x}|} \log \left(P\left(\left|x_{i}\right| \hat{x}_{i}\right)\right)$
Word Sentiment Prediction (WSP)
单词 $w_{i}$ 情绪极性 $s_{i}$ 预测(P、N、0),单词情绪极性:
$P\left(s_{i} \mid \hat{x_{i}}\right)= \operatorname{Softmax}\left(W_{s} \cdot h_{i}+b_{s}\right) $
单词情绪极性训练目标:
$\mathcal{L}_{s}=-\frac{1}{|\hat{\mathcal{X}}|} \sum_{\hat{x} \in \hat{\mathcal{X}}} \frac{1}{|\hat{x}|} \sum_{i=1}^{|\hat{x}|} \log \left(P\left(s_{i} \mid \hat{x}_{i}\right)\right)$
Rating Prediction (RP)
使用句子表示 $h_{[\mathrm{CLS}]}$ 预测评级得分:
$P(r \mid \hat{x})=\operatorname{Softmax}\left(W_{r} \cdot h_{[C L S]}+b_{r}\right)$
评级得分训练目标:
$\mathcal{L}_{r}=-\frac{1}{|\hat{\mathcal{X}}|} \sum_{\hat{x} \in \hat{\mathcal{X}}} \log (P(r \mid \hat{x}))$
2.4 Joint Training
$\mathcal{L}=\mathcal{L}_{T}+\mathcal{L}_{S}$
其中:
$\mathcal{L}_{T}=\mathcal{L}_{w}+\mathcal{L}_{s}+\mathcal{L}_{e} $
$\mathcal{L}_{S}=\mathcal{L}_{r}$
3 实验

因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17629248.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号