论文解读(MCADA)《Multicomponent Adversarial Domain Adaptation: A General Framework》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文信息
论文标题:Multicomponent Adversarial Domain Adaptation: A General Framework
论文作者:Chang’an Yi, Haotian Chen, Yonghui Xu, Huanhuan Chen, Yong Liu, Haishu Tan, Yuguang Yan, Han Yu
论文来源:2023 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
出发点:现有的域对抗训练方法主要考虑对齐域级的数据分布,而忽略了不同域中的组件之间的差异。因此,不会过滤掉与目标域无关的组件,这可能造成负迁移;
贡献:
-
- 提供了一个两阶段的框架,可同时考虑全局数据分布和特征的内在关系。即:首先学习域级模型,然后在组件级对模型进行微调来增强正迁移;
- 构造了一个二部图来匹配来自不同域的分量。二部图可以为目标域的每个分量找到最相关的源分量,由于两个匹配分量的数据分布比不同域之间的数据分布更相似,可以通过匹配组件来增强正传递;
- 实验结果表明,所提出的框架始终优于 11 种最先进的DA方法;
组件(component)的概念:
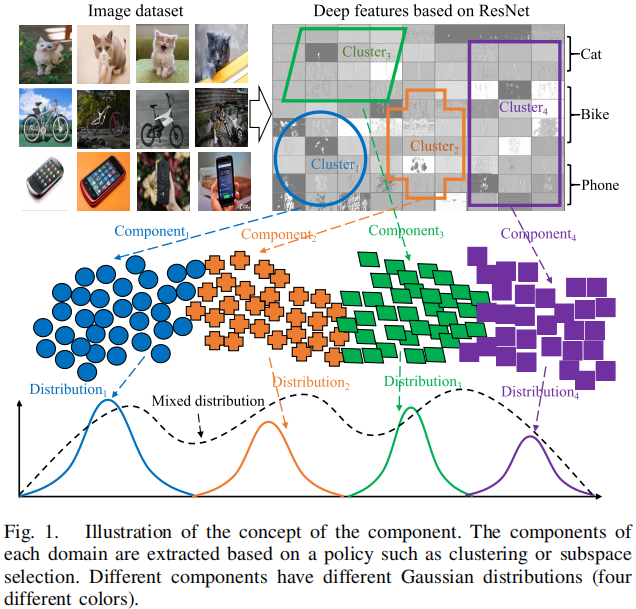
Note:半监督域适应,协变量偏移;
2 方法
2.1 整体框架
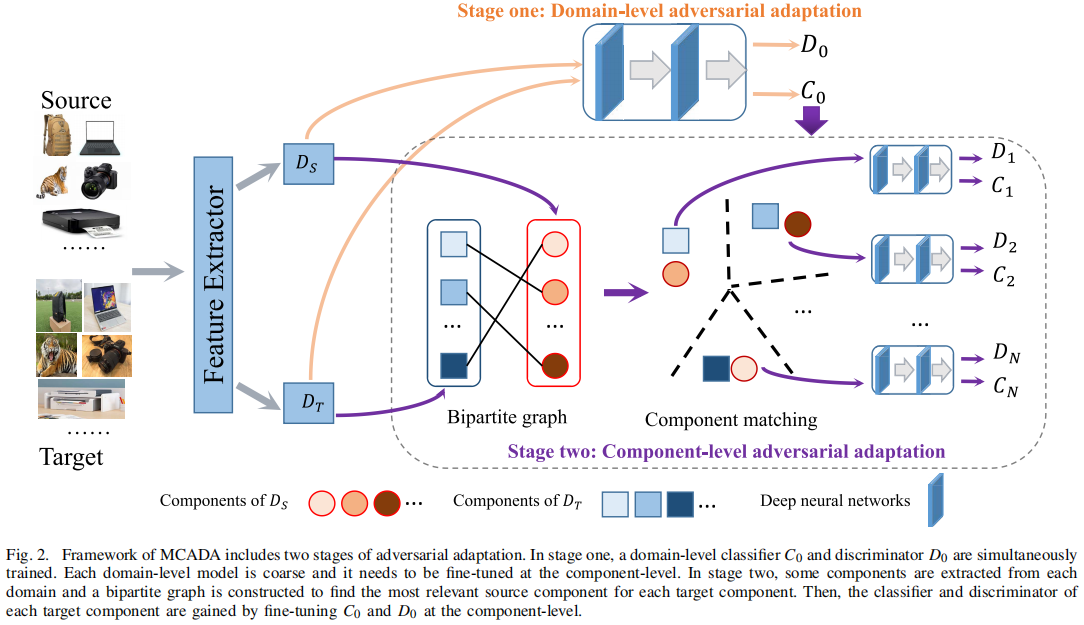
2.2 Domain-Level Adversarial Adaptation
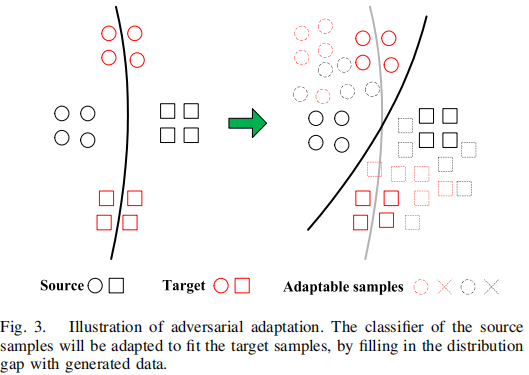
在对抗自适应过程中,需要少量已标记的目标样本,其必要性如 Figure 4 所示:
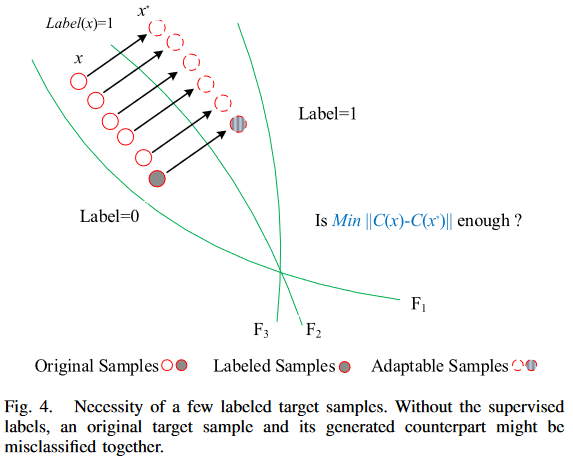
即:对比于无监督来说,其类中心更加准确;
1) Adversarial Generation
可迁移样本应该满足两个条件:
-
- 应该迷惑域鉴别器 $D$;
- 应该位于源域和目标域之间;
生成可迁移样本的方法:
$f_{\text {Fake }} \leftarrow f_{\text {True }}+\alpha \nabla_{f_{\text {Tue }}} \mathcal{L}+\beta \text { Dist. }$
注意:$f_{\text {Fake }}$ 为生成的对抗性样本,$f_{\text {True }}$ 原始样本;
使用可迁移样本可以增强分类器对 域变化 和 对抗性扰动 的鲁棒性:
$\mathcal{L}_{\text {cla }}=\mathcal{L}_{c}(x)+\mathcal{L}_{c, \text { adv }}\left(x^{*}\right)$
使用可迁移样本可以有效的弥补域差异,定义如下:
$\mathcal{L}_{\text {dis }}=\mathcal{L}_{d}(x)+\mathcal{L}_{d, \text { adv }}\left(x^{*}\right)$
第一阶段的优化问题可以总结如下:
$\underset{\Theta_{C}, \Theta_{D}}{\text{min}} \; \mathcal{L}_{\text {cla }}+\mathcal{L}_{\text {dis }}$
该小结算法如下:

2.3 Component Matching Based on Bipartite Graph
当数据分布被全局对齐后,接着便是考虑特征的内在特征,同一领域的样本往往具有不同的内在特征,而这些特征被域级的自适应所忽略。因此,应单独考虑它们,以有效地弥合分布差异。
每个域都应该被划分为不同的组件,可以通过使用基于距离的聚类方法来实现(如 k-means)。如果目标域 $D_{T}$ 被划分为 $N$ 个分量,那么 $D_{T}=\cup_{n=1}^{N} D_{T}^{n}$,其中 $D_{T}^{n} (1 \leqslant n \leqslant N)$ 表示第 $n$ 个分量。此外,$D_{S}$ 中的不同组件可能与 $D_{T}$ 中的组件之间有不同的关系。需要发现这些关系,然后分开对待它们。一个二部图可以捕获分量之间的关系。如果 $D_{S}$ 和 $D_{T}$ 分别有 $M$ 和 $N$ 个分量,则边数为 $N$,因为最终目的是对目标域进行预测。设分量级二部图为 $G=(V_s、V_t、E_{st})$,其中 $V_s$、$V_t$ 和 $E_{st}$ 分别表示源分量集、目标分量集和跨域边,$E_{\mathrm{st}}$ 中的每条边都表示基于距离的最近的关系。给定分别属于源域和目标域的两个分量 $D_{S}^{i} (1 \leqslant i \leqslant M)$ 和 $D_{T}^{j}(1 \leqslant j \leqslant N)$,这两个分量之间的距离由以下方法计算
$d_{\left(D_{S}^{i}, D_{T}^{j}\right)}=\left|\mathbb{E}_{x \sim D_{S}^{i}}[f(x)]-\mathbb{E}_{x \sim D_{T}^{j}}[f(x)]\right|$
分量的距离矩阵由一个 $M \times N$ 矩阵来描述。接下来,将匹配组件来构建成对关系,只需要为目标域中的每个组件找到最相关的源组件。
由于不同的组件具有不同的内在特征,因此需要对在第一阶段学习到的基本模型 $C_0$ 进行微调,以适应每一对匹配的组件。与域级的对抗性适应不同,标记的目标样本对于组件级的适应是不必要的,因为 $C_0$ 已经包含了这些信息。
2.4 Component-Level Adversarial Adaptation
使用上述生成的二部图对 $P=\cup_{n=1}^{N}\left\langle D_{S}^{n}, D_{T}^{n}\right\rangle(1 \leqslant n \leqslant N)$ 进行对抗性训练
组件之间的对抗性样本:
$f_{S_{i}^{\omega}} \leftarrow+f_{S_{i}}{ }^{\omega}+\alpha \nabla_{f_{S_{i}} \omega} \mathcal{L}_{d}\left(f_{S_{i}}{ }^{\omega}, \Theta_{d}^{n}\right) +\alpha \nabla_{f_{S_{i} \omega}} \mathcal{L}_{c}\left(f_{S_{i} \omega}, \Theta_{c}^{n}\right) -\beta \nabla_{f_{S_{i}} \omega} \ell_{2}\left(f_{S_{i}}{ }^{\omega}, f_{S_{i}}{ }^{0}\right)$
$f_{T_{i}{ }^{\omega+1}} \leftarrow f_{T_{i}{ }^{\omega}}+\alpha \nabla_{f_{T_{i}}{ }^{\omega}} \mathcal{L}_{d}\left(f_{T_{i}{ }^{\omega}}, \Theta_{d}^{n}\right) -\beta \nabla_{f_{T_{i}} \omega} \ell_{2}\left(f_{T_{i}{ }^{\omega}}, f_{T_{i}{ }^{0}}\right)$
即:和原样本距离尽可能小,域鉴别和(分类)能力尽可能差;
$C_{n}$ 训练如下:
$\begin{array}{l}\mathcal{L}_{c}\left(P_{n},\left.\Theta_{C}^{n}\right|_{n=1} ^{N}\right)= \mathbb{E}_{\left(x_{s}^{(i)}, y_{s}^{(i)}\right) \sim D_{S}^{n}} \Phi_{\mathrm{ce}}\left(C_{n}\left(x_{s}^{(i)}\right), y_{s}^{(i)}\right) \\\mathcal{L}_{c, \text { adv }}\left(P_{n},\left.\Theta_{C}^{n}\right|_{n=1} ^{N}\right)= \mathbb{E}_{\left(x_{s}^{*(i)}, y_{s}^{(i)}\right) \sim D_{S}^{n}} \Phi_{\mathrm{ce}}\left(C_{n}\left(x_{s}^{*(i)}\right), y_{s}^{(i)}\right) +\mathbb{E}_{x_{t}^{*(i)} \sim D_{T}^{n}}\left\|C_{n}\left(x_{t}^{*(i)}\right)-C_{n}\left(x_{t}^{(i)}\right)\right\|_{2}\end{array}$
$D_{n}$ 训练如下:
$\begin{array}{l}\mathcal{L}_{d}\left(P_{n},\left.\Theta_{D}^{n}\right|_{n=1} ^{N}\right)= -\mathbb{E}_{x_{s}^{(i)} \sim D_{S}^{n}} \log \left[D_{n}\left(x_{s}^{(i)}\right)\right] -\mathbb{E}_{x_{t}^{(i)} \sim D_{T}^{n}} \log \left[1-D_{n}\left(x_{t}^{(i)}\right)\right] \\\mathcal{L}_{d, \text { adv }}\left(P_{n},\left.\Theta_{D}^{n}\right|_{n=1} ^{N}\right)= -\mathbb{E}_{x_{s}^{*(i)} \sim D_{S}^{n}} \log \left[D_{n}\left(x_{s}^{*(i)}\right)\right] -\mathbb{E}_{x_{t}^{*(i)} \sim D_{T}^{n}} \log \left[1-D_{n}\left(x_{t}^{*(i)}\right)\right]\end{array}$
对 $P_n(1⩽n⩽n)$ 的优化问题总结如下:
$\begin{aligned}\left(\hat{\Theta}^{1}, \ldots, \hat{\Theta}^{n}\right)= & \arg \underset{\Theta^{1}, \ldots, \Theta^{n}}{\text{min}} \mathcal{L}_{c}\left(P_{n}, \Theta_{C}^{n}\right)+\mathcal{L}_{d}\left(P_{n}, \Theta_{D}^{n}\right) \\& +\lambda \mathcal{L}_{c, \text { adv }}\left(P_{n}, \Theta_{C}^{n}\right)+\lambda \mathcal{L}_{d, \text { adv }}\left(P_{n}, \Theta_{D}^{n}\right)\end{aligned}$
算法如下:

2.4 Extensibility of MCADA on Streaming Data

3 实验
域适应结果:

因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17616870.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号