论文解读(LightGCL)《LightGCL: Simple Yet Effective Graph Contrastive Learning for Recommendation》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文信息
论文标题:LightGCL: Simple Yet Effective Graph Contrastive Learning for Recommendation
论文作者:Cai, Xuheng and Huang, Chao and Xia, Lianghao and Ren, Xubin
论文来源:2023 ICLR
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
出发点:现有图对比推荐方法主要么对用户-项目交互图执行随机增强(例如,节点/边缘扰动),要么依赖于基于启发式的增强技术(例如,用户聚类)来生成对比视图。本文认为这些方法不能很好的保存图内部的语义结构,而且容易收到噪声的干扰;
贡献:
-
- 在本文中,我们通过设计一个轻量级和鲁棒的图对比学习框架来增强推荐系统,以解决与该任务相关的关键挑战;
- 我们提出了一种有效的对比学习范式用于图的增强。通过全球协作关系的注入,我们的模型可以缓解不准确的对比信号所带来的问题;
- 与现有的基于gcl的方法相比,我们的方法提高了训练效率;
- 在几个真实数据集上进行的大量实验证明了我们的LightGCL的性能优势。深入的分析证明了LightGCL的合理性和稳健性;
2 方法
2.1 模型框架
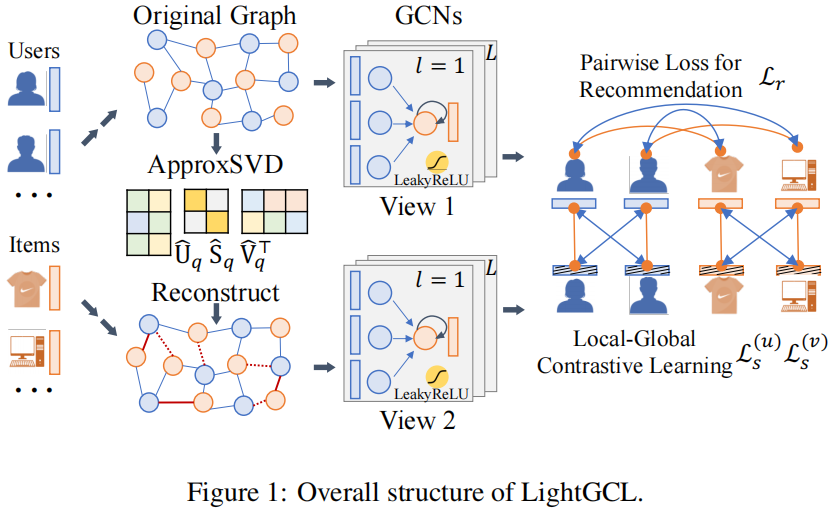
2.2 局部图依赖关系建模
使用一个 两层的 GCN 捕获用户-物品之间的局部关系:
$\boldsymbol{z}_{i, l}^{(u)}=\sigma\left(p\left(\tilde{\mathcal{A}}_{i,:}\right) \cdot \boldsymbol{E}_{l-1}^{(v)}\right), \quad \boldsymbol{z}_{j, l}^{(v)}=\sigma\left(p\left(\tilde{\mathcal{A}}_{:, j}\right) \cdot \boldsymbol{E}_{l-1}^{(u)}\right)$
最终的用户和物品嵌入表示如下(每层嵌入的加和):
$\boldsymbol{e}_{i}^{(u)}=\sum_{l=0}^{L} \boldsymbol{z}_{i, l}^{(u)}, \quad \boldsymbol{e}_{j}^{(v)}=\sum_{l=0}^{L} \boldsymbol{z}_{j, l}^{(v)}, \quad \hat{y}_{i, j}=\boldsymbol{e}_{i}^{(u) \top} \boldsymbol{e}_{j}^{(v)}$
2.3 高效的全局协作关系学习
为使图对比学习与全局结构学习一起进行推荐,引入 SVD 以便从全局的角度有效地提取重要的协作信号。
首先对归一化邻接矩阵进行 SVD 分解:
$\tilde{\mathcal{A}}=\boldsymbol{U} \boldsymbol{S} \boldsymbol{V}^{\top} $
注意:$\boldsymbol{U}$ 和 $\boldsymbol{V}$ 分别是 $I \times I $ 和 $J \times J$ 的矩阵,$S$ 是 $I \times J $ 的对角矩阵(主对角线为从大到小的奇异值);
由于最大的奇异值通常与矩阵的主成分相关联。因此,本文截断奇异值列表以保持大的奇异值值,并重构被截断的归一化邻接矩阵:
$\hat{\mathcal{A}}=\boldsymbol{U}_{q} \boldsymbol{S}_{q} \boldsymbol{V}_{q}^{\top} $
注意:$\boldsymbol{U}_{q} \in \mathbb{R}^{I \times q}$、$\boldsymbol{V}_{q} \in \mathbb{R}^{J \times q}$、$\boldsymbol{S}_{q} \in \mathbb{R}^{q \times q} $;
优点:
①:通过识别对用户偏好表示很重要和可靠的 user-item 交互来强调图的主成分;
②:生成的新图结构通过考虑每个 user-item 对来保持全局协作信号;
$\boldsymbol{g}_{i, l}^{(u)}=\sigma\left(\hat{\mathcal{A}}_{i,:} \cdot \boldsymbol{E}_{l-1}^{(v)}\right), \quad \boldsymbol{g}_{j, l}^{(v)}=\sigma\left(\hat{\mathcal{A}}_{:, j} \cdot \boldsymbol{E}_{l-1}^{(u)}\right)$
$\hat{\boldsymbol{U}}_{q}, \hat{\boldsymbol{S}}_{q}, \hat{\boldsymbol{V}}_{q}^{\top}=\operatorname{ApproxSVD}(\tilde{\mathcal{A}}, q), \quad \hat{\mathcal{A}}_{S V D}=\hat{\boldsymbol{U}}_{q} \hat{\boldsymbol{S}}_{q} \hat{\boldsymbol{V}}_{q}^{\top}$
$\boldsymbol{G}_{l}^{(u)}=\sigma\left(\hat{\mathcal{A}}_{S V D} \boldsymbol{E}_{l-1}^{(v)}\right)=\sigma\left(\hat{\boldsymbol{U}}_{q} \hat{\boldsymbol{S}}_{q} \hat{\boldsymbol{V}}_{q}^{\top} \boldsymbol{E}_{l-1}^{(v)}\right) ; \quad \boldsymbol{G}_{l}^{(v)}=\sigma\left(\hat{\mathcal{A}}_{S V D}^{\top} \boldsymbol{E}_{l-1}^{(u)}\right)=\sigma\left(\hat{\boldsymbol{V}}_{q} \hat{\boldsymbol{S}}_{q} \hat{\boldsymbol{U}}_{q}^{\top} \boldsymbol{E}_{l-1}^{(u)}\right)$
2.4 简化的局部-全局对比学习
传统方法:采用三视图范式,使用增强图之间的对比策略,而不使用原始图;
本文:认为,增强图之间的对比可能带来错误信息知道,可能是由于破坏了图结构,然而,在本文提出的方法中,增强图视图是通过全局协作关系创建的,这可以增强主视图的表示。
$\mathcal{L}_{s}^{(u)}=\sum_{i=0}^{I} \sum_{l=0}^{L}-\log \frac{\exp \left(s\left(\boldsymbol{z}_{i, l}^{(u)}, \boldsymbol{g}_{i, l}^{(u)} / \tau\right)\right)}{\sum_{i^{\prime}=0}^{I} \exp \left(s\left(\boldsymbol{z}_{i, l}^{(u)}, \boldsymbol{g}_{i^{\prime}, l}^{(u)}\right) / \tau\right)}$
推荐任务损失:
总损失:
$\mathcal{L}=\mathcal{L}_{r}+\lambda_{1} \cdot\left(\mathcal{L}_{s}^{(u)}+\mathcal{L}_{s}^{(v)}\right)+\lambda_{2} \cdot\|\Theta\|_{2}^{2} $
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17614670.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号