论文解读(DWL)《Dynamic Weighted Learning for Unsupervised Domain Adaptation》
[ Wechat:Y466551 | 付费咨询,非诚勿扰 ]
论文信息
论文标题:Dynamic Weighted Learning for Unsupervised Domain Adaptation
论文作者:Jihong Ouyang、Zhengjie Zhang、Qingyi Meng
论文来源:2023 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
2 方法
2.1 出发点
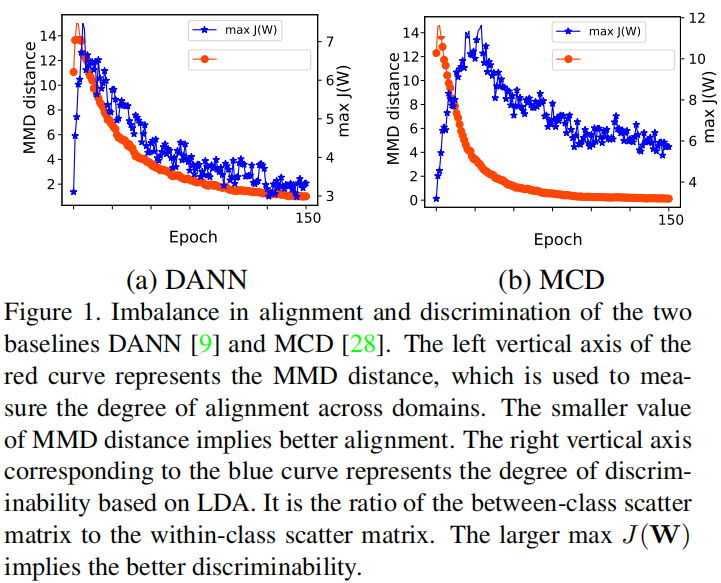
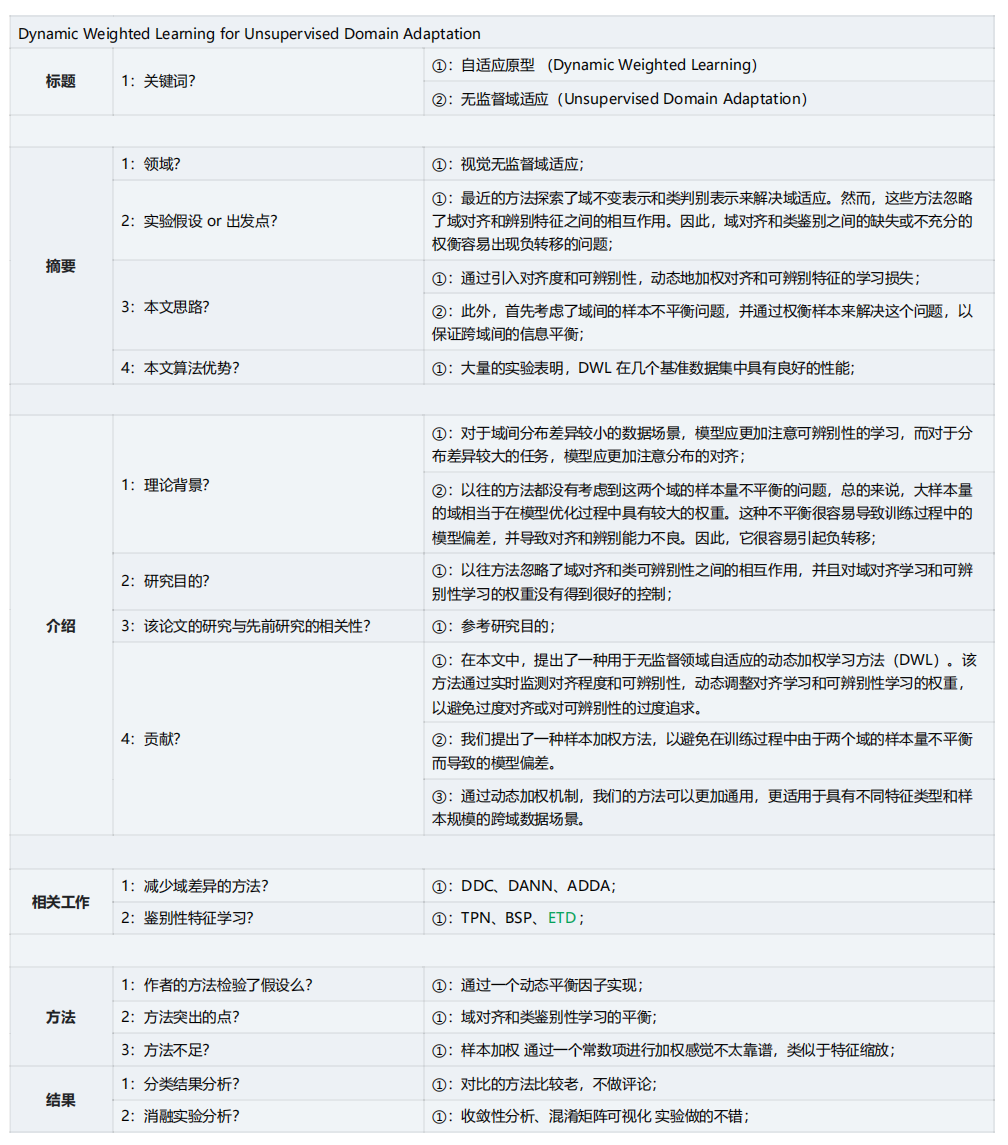
反应的问题:随着域对齐的实现,判别性在下降;
2.2 模型框架
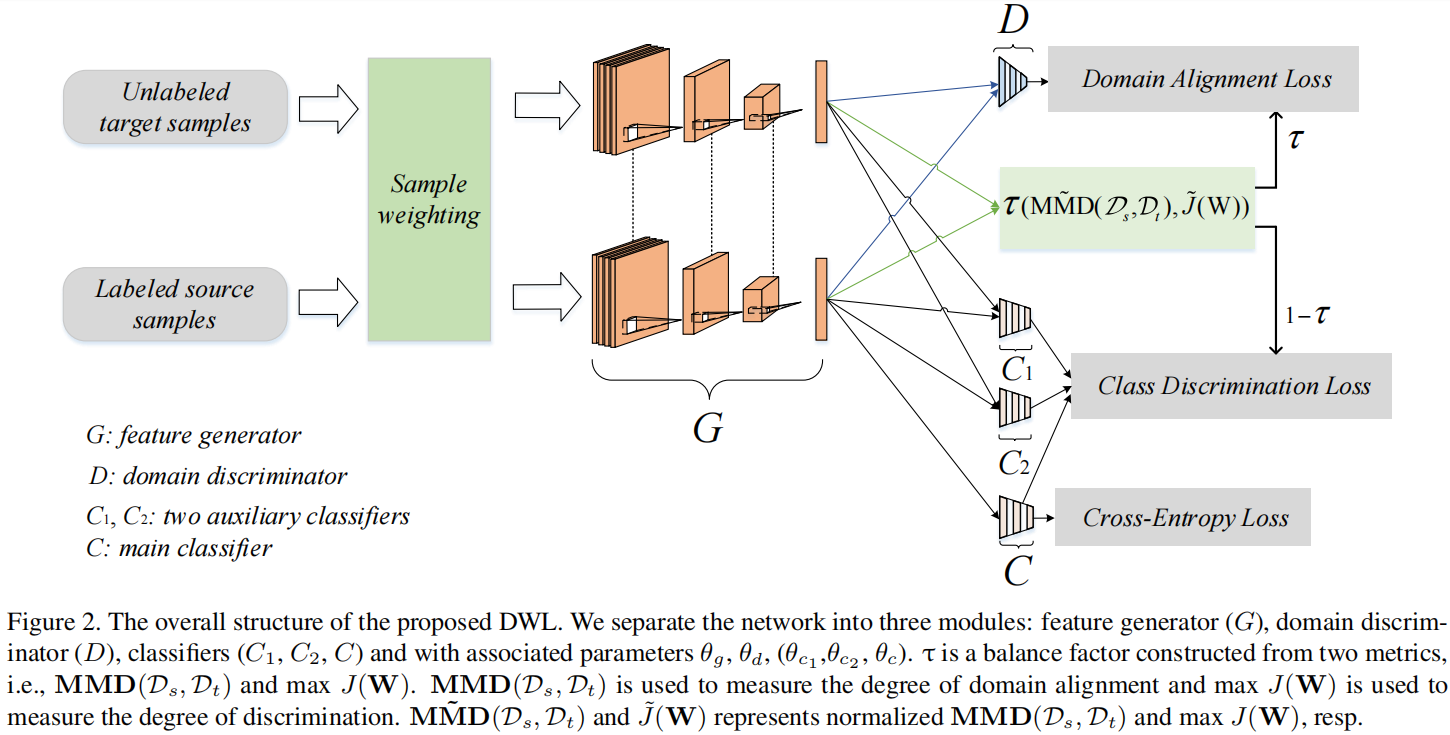
2.3 Sample Weighting
$\begin{array}{l}\hat{x}_{i}^{s}=a\left(1+\frac{n_{t}}{n_{s}}\right) x_{i}^{s} \quad, \quad i=1,2, \ldots, n_{s} \\\hat{x}_{j}^{t}=a\left(1+\frac{n_{s}}{n_{t}}\right) x_{j}^{t} \quad, \quad j=1,2, \ldots, n_{t}\end{array} $
其中,$a \in(0,1]$ 是一个控制样本加权程度的超参数。
2.4 Domain Alignment Learning and Class Discrimination Learning
域对齐(对抗性学习):
$\begin{array}{r} \underset{\theta_{g}}{\text{min}} \; \underset{\theta_{d}}{\text{max}} \; \mathcal{L}_{d a}\left(\theta_{g}, \theta_{d}\right)=\mathbb{E}_{x_{i}^{s} \sim \mathcal{D}_{s}} \log \left[D\left(G\left(\hat{x}_{i}^{s}\right)\right)\right] +\mathbb{E}_{x_{j}^{t} \sim \mathcal{D}_{t}} \log \left[1-D\left(G\left(\hat{x}_{j}^{t}\right)\right)\right]\end{array}$
鉴别性特征学习:
$\begin{aligned} \underset{\theta_{g}, \theta_{c}}{\text{min}} \; \underset{\theta_{c_{1}}, \theta_{c_{2}}}{\text{max}} \; \mathcal{L}_{c d} & \left(\theta_{g}, \theta_{c}, \theta_{c_{1}}, \theta_{c_{1}}\right) \\= & \mathbb{E}_{x_{j}^{t} \sim \mathcal{D}_{t}}\left\|C_{1}\left(G\left(\hat{x}_{j}^{t}\right)\right)-C_{2}\left(G\left(\hat{x}_{j}^{t}\right)\right)\right\|_{1} \\& +\left\|C\left(G\left(\hat{x}_{j}^{t}\right)\right)-C_{1}\left(G\left(\hat{x}_{j}^{t}\right)\right)\right\|_{1} \\& +\left\|C\left(G\left(\hat{x}_{j}^{t}\right)\right)-C_{2}\left(G\left(\hat{x}_{j}^{t}\right)\right)\right\|_{1}\end{aligned}$
Note:$C$、$C_{1}$、$C_{2}$ 是使用源域数据预训练得到的分类器;
对抗性训练步骤:
- 固定 $G$ 和 $C$ 最大化 $C_1$ 和 $C_2$ 的差异;
- 固定 $C_{1}$ 和 $C_{2}$ 训练 $G$ 和 $C$;
2.5 Dynamic Weighted Learning
域对齐度量 [ MMD ]:
$\operatorname{MMD}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)=\left\|\mathbb{E}_{x_{i}^{s} \sim \mathcal{D}_{s}} G\left(\hat{x}_{i}^{s}\right)-\mathbb{E}_{x_{j}^{t} \sim \mathcal{D}_{t}} G\left(\hat{x}_{j}^{t}\right)\right\|^{2}$
鉴别性度量 [ LDA ]:
$\underset{\mathbf{W}}{\text{max}} \; J(\mathbf{W})=\frac{\operatorname{tr}\left(\mathbf{W}^{\top} \mathbf{S}_{\mathbf{b}} \mathbf{W}\right)}{\operatorname{tr}\left(\mathbf{W}^{\top} \mathbf{S}_{\mathbf{w}} \mathbf{W}\right)}$
其中,$\mathbf{S}_{\mathrm{b}}$ 为类间散射矩阵,$\mathbf{S}_{\mathbf{w}}$ 为类内散射矩阵。
注意:$J(\mathbf{W})$ 越大,具有更好的辨别性。
由于上述两个评价标准不在一个数量级上,本文对其进行了归一化处理:
$\begin{array}{l}\operatorname{\text{M}} \tilde{\text{M}} \text{D}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)=\frac{\operatorname{MMD}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)-\operatorname{MMD}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)_{\min }}{\operatorname{MMD}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)_{\max }\quad-\quad\operatorname{MMD}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)_{\min }} \end{array}$
$\tilde{J}(\mathbf{W})=\frac{J(\mathbf{W})\;-\;J(\mathbf{W})_{\min }}{J(\mathbf{W})_{\max }\quad- \quad J(\mathbf{W})_{\min }}$
构造一个动态平衡因子:
$\tau=\frac{\operatorname{M} \tilde{\mathbf{M}}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)}{\operatorname{M} \tilde{\mathbf{M}}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)+(1-\tilde{J}(\mathbf{W}))}$
因此:
-
- 当域对齐的程度远优于类的可辨别性时,$\text{M} \tilde{\text{M}} \text{D}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)$ 接近 $0$,$1-\tilde{J}(\mathbf{W}) $ 接近 $1$ ,$\tau$ 接近 $0$;
- 当域对齐程度远低于类别识别程度时,$\text{M} \tilde{\text{M}} \text{D}\left(\mathcal{D}_{s}, \mathcal{D}_{t}\right)$ 接近 $1$,$1-\tilde{J}(\mathbf{W}) $ 接近 $0$ ,$\tau$ 接近 $1$ ;
基于 $\tau$ 的良好特性,采用 $\tau$ 作为域对齐损失的权重,$1−\tau $ 作为类鉴别损失的权重。
因此,最终的动态加权模型如下:
$\begin{array}{l} \underset{\theta_{g}, \theta_{c}}{\text{min}} \;\; \underset{\theta_{\theta_{d}, \theta_{c_{1}}, \theta_{c_{2}}}}{\text{max}} \tau \cdot \mathcal{L}_{d a}\left(\theta_{g}, \theta_{d}\right)+ (1-\tau) \cdot \mathcal{L}_{c d}\left(\theta_{g}, \theta_{c}, \theta_{c_{1}}, \theta_{c_{2}}\right)\end{array}$
- 当域对齐学习的有效性远低于类辨别学习时,模型增加域对齐学习的权重;
- 当鉴别学习的学习效果远低于域对齐学习时,模型增加鉴别学习的权重;
在这种动态加权学习机制下,可保持域对齐与类辨别学习之间的一致性,避免过度的域对齐或类可辨别性。
2.6 Overall Training Objective
总体训练目标整合了样本加权、领域对齐学习、类判别学习和动态加权学习。此外,还需要最小化标记源样本的期望源误差。最终的极大极小目标:
$\begin{array}{l}\underset{\theta_{g}, \theta_{c}}{\text{min}} \;\;\underset{\theta_{d}, \theta_{c_{1}}, \theta_{c_{2}}}{\text{max}}\sum_{i=1}^{t_{s}} \mathcal{L}_{c e}\left(C\left(G\left(x_{i}^{s} ; \theta_{g}\right) ; \theta_{c}\right), y_{i}^{s}\right) +\tau \cdot \mathcal{L}_{d a}\left(\theta_{g}, \theta_{d}\right)+(1-\tau) \cdot \mathcal{L}_{c d}\left(\theta_{g}, \theta_{c}, \theta_{c_{1}}, \theta_{c_{2}}\right)\end{array}$
3 实验
分类结果

收敛性分析
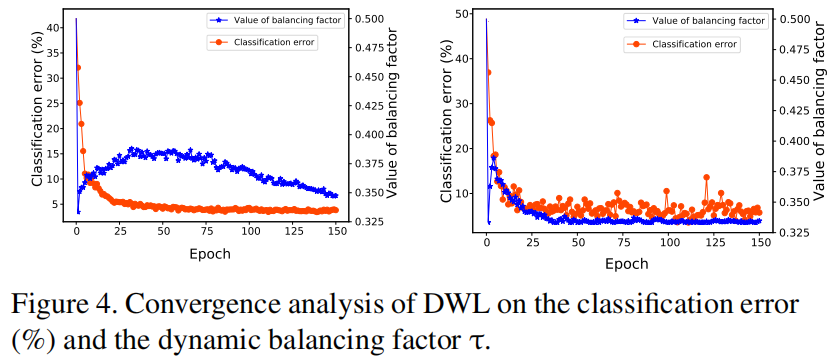
对于每个子图,红色曲线的左轴表示分类误差,蓝色曲线的右轴表示平衡因子 $\tau$ 的值。可以发现,随着迭代,它们两者都逐渐收敛到一个平坦的值。这意味着随着 $\tau$ 的减少,使得类的可鉴别性被强调,使得分类误差也减小。
在迭代过程中,当 $\tau$ 的变化相对明显时,识别精度的提高也相对明显。我们将 $\tau$ 的初始值设为 $0.5$,可以发现 $\tau$ 在第一个时期急剧下降到 $0.5$ 以下,说明该模型的对齐性相对较好,但可辨别性相对较差。
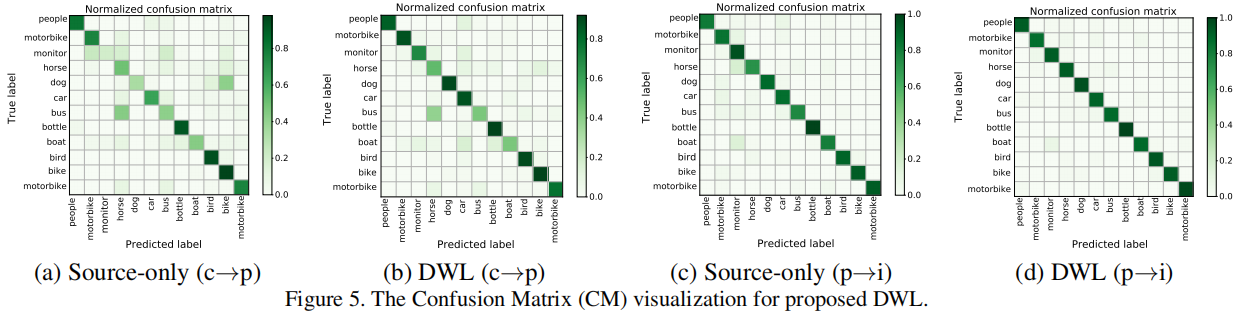
混淆矩阵可视化
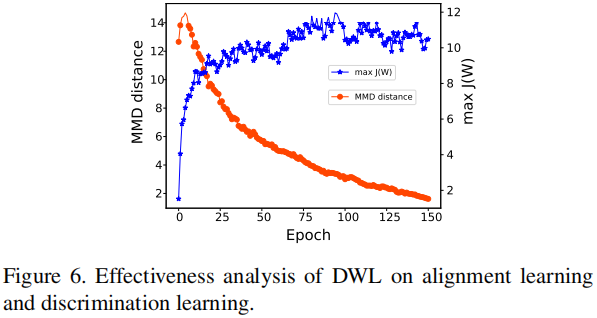
对齐度和可鉴别性度的分析
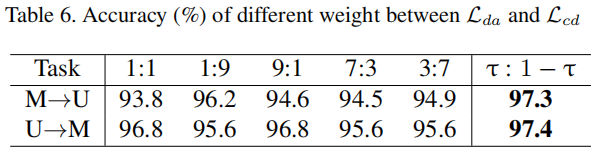
消融实验

因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17604174.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号