论文解读(APCA)《Adaptive prototype and consistency alignment for semi-supervised domain adaptation》
[ Wechat:Y466551 | 付费咨询,非诚勿扰 ]
论文信息
论文标题:Adaptive prototype and consistency alignment for semi-supervised domain adaptation
论文作者:Jihong Ouyang、Zhengjie Zhang、Qingyi Meng
论文来源:2023 aRxiv
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
3 方法
3.1 模型框架
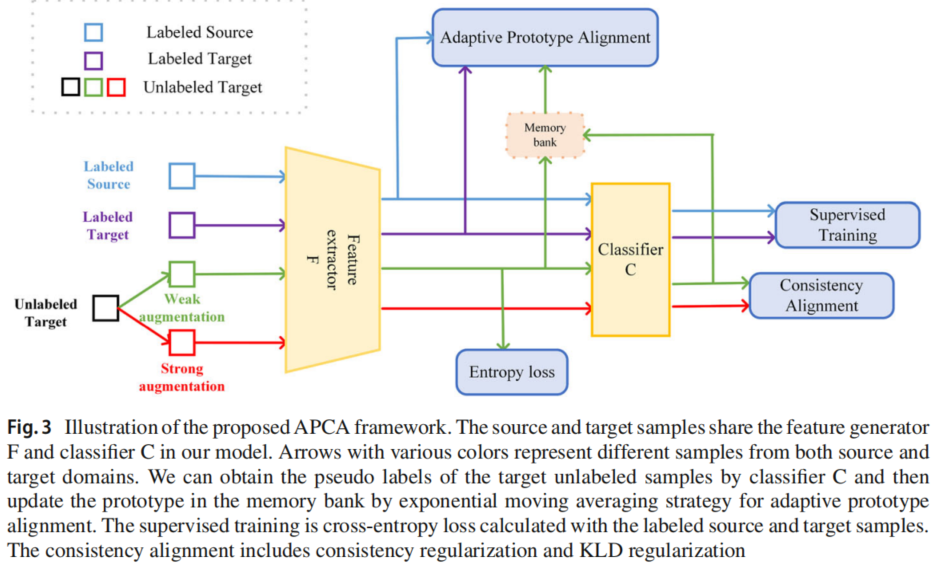
3.2 Supervised training
原型分类器(浅层):
$\mathbf{p}(\mathbf{x})=\sigma\left(\frac{\mathbf{W}^{\mathrm{T}} \ell_{2}(F(\mathbf{x}))}{T}\right) \quad\quad(1)$
源域和目标域监督训练:
$\mathcal{L}_{C E}=-\mathbb{E}_{(\mathbf{x}, y) \in \mathcal{D}_{s}, \mathcal{D}_{t}} y \log (\mathbf{p}(\mathbf{x})) \quad\quad(2)$
3.3 Adaptive prototype alignment
利用目标域带标记数据(弱)计算原型:
$\mathbf{c}_{k}^{\mathcal{T}}=\frac{1}{\left|\mathcal{D}_{k}\right|} \sum_{\left(x_{i}^{t}, y_{i}^{t}\right) \in \mathcal{D}_{k}} F\left(x_{i}^{t}\right)\quad\quad(3)$
利用目标域未带标记的数据计算原型(mini-batch级别):
$c_{k}^{u}=\frac{\sum_{i \in B_{t}}\; \mathbb{1}_{\left[k=\hat{y}_{i}\right]} \;\;F\left(x_{i}^{u}\right)}{\sum_{i \in B_{t}} \;\mathbb{1}_{\left[k=\hat{y}_{i}\right]}\;\;}\quad\quad(4)$
Note:目标域未带标记样本使用分类器给出伪标签;
利用 EMA 修改用目标域未带标记样本计算的原型:
$c_{k(m)}^{\mathcal{U}}=\eta c_{k}^{u}+(1-\eta) c_{k(m-1)}^{\mathcal{U}}\quad\quad(5)$
目标域总的原型:
$c_{k}=\frac{\mathbf{c}_{k}^{\mathcal{T}}+c_{k(m)}^{\mathcal{U}}}{2}\quad\quad(6)$
对于源域带标记数据,计算与目标原型距离,得到概率分布如下:
$p(y \mid x)=\frac{e^{-d\left(F(x), c_{y}\right)}}{\sum_{k} e^{-d\left(F(x), c_{k}\right)}}\quad\quad(7)$
自适应原型对齐损失(APA) 如下:
$\mathcal{L}_{A P A}=-\mathbb{E}_{\left(x_{i}^{s}, y_{i}^{s}\right) \in \mathcal{D}_{s}} \log p\left(y_{i}^{s} \mid x_{i}^{s}\right)\quad\quad(8)$
小结阐述:使用目标域数据(带、不带标记)计算目标域原型,然后预测源域样本的类别,并使用源域标签做监督;
3.4 Consistency alignment
目标域未带标记数据被分为弱、强数据增强样本,对于弱数据增强样本,使用分类器得到硬标签,并计算交叉熵(基于阈值$\gamma$):
$\left.\ell_{c r}=-\mathbb{1}\left(\max \left(\mathbf{p}_{w}\right)>\tau\right) \log \mathbf{p}\left(y=\hat{p} \mid \mathcal{S}\left(x_{i}^{u}\right)\right)\right)\quad\quad(9)$
为避免过拟合,使用多样性损失(基于阈值$\gamma$):
$\ell_{k l d}=-\mathbb{1}\left(\max \left(\mathbf{p}_{w}\right)>\tau\right) \sum_{k=1}^{C} \frac{1}{C} \log \mathbf{p}\left(y=k \mid \mathcal{S}\left(x_{i}^{u}\right)\right)\quad\quad(10)$
Note:KLD正则化鼓励预测结果接近均匀分布,从而使预测结果不会过拟合伪标签;
因此,一致性对齐模块的整体损失函数可以表示如下:
$\mathcal{L}_{C O N}=\mathbb{E}_{x_{i}^{u} \in \mathcal{D}_{u}}\left(\ell_{c r}+\lambda_{k l d} \ell_{k l d}\right)\quad\quad(11)$
3.5 Overall framework and training objective
本文方法是基于MME [45]的,它采用对抗性学习来改进域间自适应的样本特征对齐。将MME[45]中提到的熵损失纳入到本文的损失函数中。总体损失函数是上述损失函数的和,如下:
$\theta_{\mathcal{F}}=\underset{\theta_{\mathcal{F}}}{\arg \min } \mathcal{L}_{C E}+\mathcal{L}_{H}+\lambda_{1} \mathcal{L}_{A P A}+\lambda_{2} \mathcal{L}_{C O N}\quad\quad(13)$
$\theta_{\mathcal{C}}=\underset{\theta_{\mathcal{A}}}{\arg \min } \mathcal{L}_{C E}-\mathcal{L}_{H}+\lambda_{1} \mathcal{L}_{A P A}+\lambda_{2} \mathcal{L}_{C O N}$
其中:
$\mathcal{L}_{H}=-\mathbb{E}_{x_{i}^{u} \in \mathcal{D}_{u}} \sum_{i=1}^{K} p\left(y=i \mid x_{i}^{u}\right) \log p\left(y=i \mid x_{i}^{u}\right)$
3.6 算法框架

4 实验
分类准确度 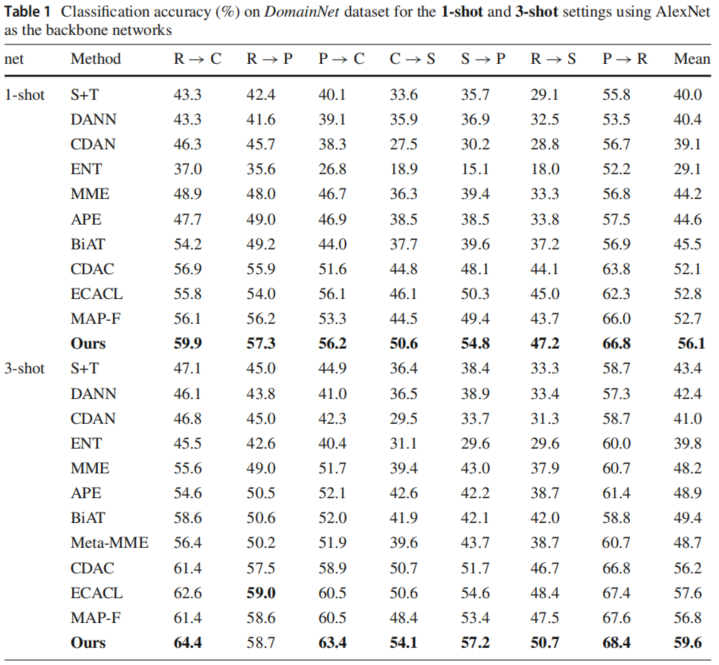
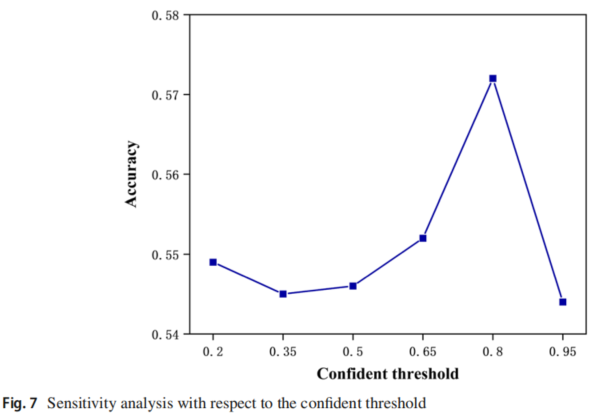
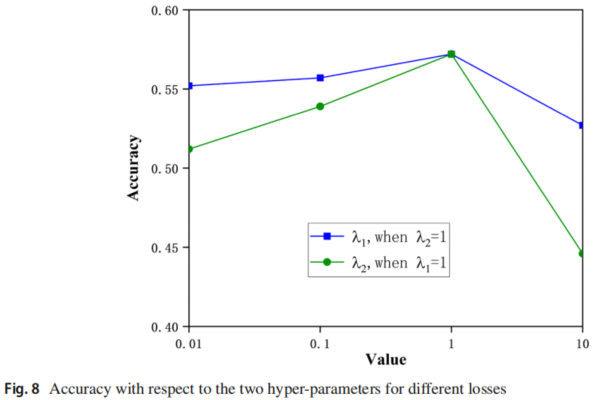
参数敏感性
消融实验

因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17600289.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号