论文解读(BERT-DAAT)《Adversarial and Domain-Aware BERT for Cross-Domain Sentiment Analysis》
Note:[ wechat:Y466551 | 付费咨询,非诚勿扰 ]
论文信息
论文标题:Adversarial and Domain-Aware BERT for Cross-Domain Sentiment Analysis
论文作者:
论文来源:2020 ACL
论文地址:download
论文代码:download
视屏讲解:click
1 介绍

2 问题定义
在跨域情绪分析任务中,给出了两个域 $D_{s}$ 和 $D_{t}$,它们分别表示源域和目标域。在源域中,$D_{s}^{l}=\left\{x_{s}^{i}, y_{s}^{i}\right\}_{i=1}^{N_{s}^{l}}$ 是 $N_{s}^{l}$ 标记的源域例子,其中 $x_{s}^{i}$ 表示一个句子,$y_{s}^{i}$ 是对应的标签。在源域中也有 $N_{s}^{u}$ 个未标记的数据 $D_{s}^{u}=\left\{x_{s}^{i}\right\}_{i=1+N_{s}^{l}}^{N_{s}^{l}+N_{s}^{u}}$。在目标域中,有一组未标记的数据 $D_{t}=\left\{x_{t}^{i}\right\}_{i=1}^{N_{t}}$,其中 $N_{t}$ 为未标记数据的数量。跨域情绪分析要求我们学习一个基于标记源域数据训练的鲁棒分类器来预测目标域中未标记句子的标签。
2 方法
2.1 BERT Post-training
2.1.1 域区分任务
本文用域区分任务(DDT)来替换 NSP 任务:50% 的时间句子 A 和句子 B 都是从目标域评论中随机抽取的,我们将其标记为 TargetDomain。50% 的时间句子 A 和句子 B 来自目标域和另一个域,其标签为MixDomain。
我们在合并表示上添加一个输出层,并使正确标签的可能性最大化。领域区分预训练使BERT能够提取出不同领域的特定特征,增强了下游的对抗性训练,有利于跨域情绪分析。
2.1.2 目标域 MLM
为了注入目标领域的知识,本文利用掩蔽语言模型(MLM),它需要预测句子中随机掩蔽的单词。在跨域情绪分析中,在目标域中没有标记数据,只有大量的未标记数据来进行 MLM 训练 BERT。具体来说,本文用 [MASK] 随机替换 15% 的 Token,并进行 mask token 的预测。
Note:来自其他域的句子将是带来域偏差的噪声。因此,当域区分任务标签是 MixDomain 时,只掩码目标域句子中的 Token。
2.2 对抗训练
BERT Post-training 注入目标领域的知识,并为 BERT 带来了对领域的意识。基于 BERT Post-training,现在可以利用对抗训练放弃提炼的域特定特征来导出域不变特征。具体来说,设计了一个情绪分类器和一个域鉴别器来处理特殊分类嵌入 [CLS] 的隐藏状态 $h_{[CLS]}$。
2.2.1 情绪分类器
分类器:
$y_{s}=\operatorname{softmax}\left(W_{s} h_{[C L S]}+b_{s}\right)$
2.2.2 域鉴别器
标准的 DANN:
$d=\operatorname{softmax}\left(W_{d} \hat{h}_{[C L S]}+b_{d}\right)$
$L_{d o m}=-\frac{1}{N_{s}+N_{t}} \sum_{i}^{N_{s}+N_{t}} \sum_{j}^{K} \hat{d}^{i}(j) \log d^{i}(j)$
$\begin{array}{c}Q_{\lambda}(x)=x, \\\frac{\partial Q_{\lambda}(x)}{\partial x}=-\lambda I .\end{array}$
2.3 训练目标
完整的训练目标:
$L_{\text {total }}=L_{\text {sen }}+L_{\text {dom }}$
3 实验结果
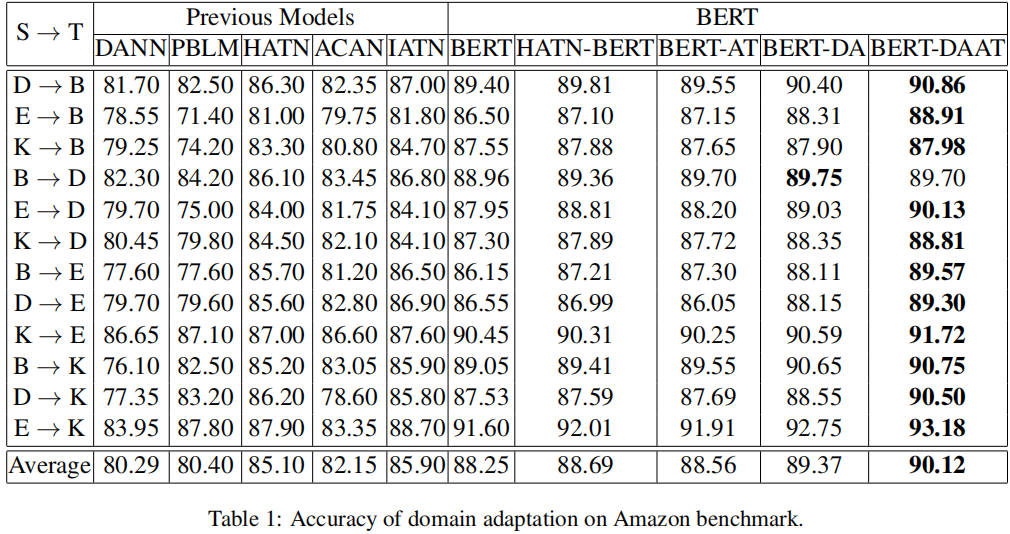
分类结果
A-distance

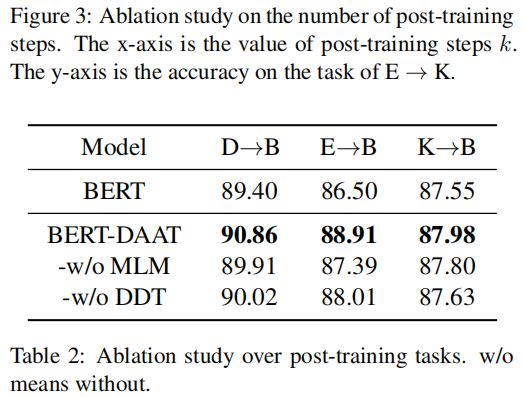
消融实验

因上求缘,果上努力~~~~ 作者:图神经网络,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17585186.html

