论文解读《Do We Need Zero Training Loss After Achieving Zero Training Error?》
论文信息
论文标题:Do We Need Zero Training Loss After Achieving Zero Training Error?
论文作者:Takashi Ishida, I. Yamane, Tomoya Sakai, Gang Niu, M. Sugiyama
论文来源:2020 ICML
论文地址:download
论文代码:download
视屏讲解:click
1 简介
训练模型的时候,需要将训练损失降到 0 吗?显然不用。一般来说,是用训练集来训练模型,但希望的是验证集的损失越小越好,而正常来说训练集的损失降低到一定值后,验证集的损失就会开始上升,因此没必要把训练集的损失降低到 0。
2 方法
假设原来的损失函数是 $\mathcal{L}(\theta)$ ,现在改为 $\tilde{\mathcal{L}}(\theta)$ :
$\tilde{\mathcal{L}}(\theta)=|\mathcal{L}(\theta)-b|+b$
其中 $b$ 是预先设定的阈值。当 $\mathcal{L}(\theta)>b$ 时 $\tilde{\mathcal{L}}(\theta)=\mathcal{L}(\theta)$ ,这时候就是执行普通的梯度下降;而 $\mathcal{L}(\theta)<b$ 时 $\tilde{\mathcal{L}}(\theta)=2 b-\mathcal{L}(\theta)$ ,注意到损失函数变号了,所以这时候是梯度上升。因此,总的来说就 是以 $b$ 为阈值,低于阈值时反而希望损失函数变大。论文把这个改动称为 “Flooding”。
论文显示,在某些任务中,训练集的损失函数经过这样处理后,验证集的损失 能出现“二次下降 (Double Descent) ”,如下图:

3 实验
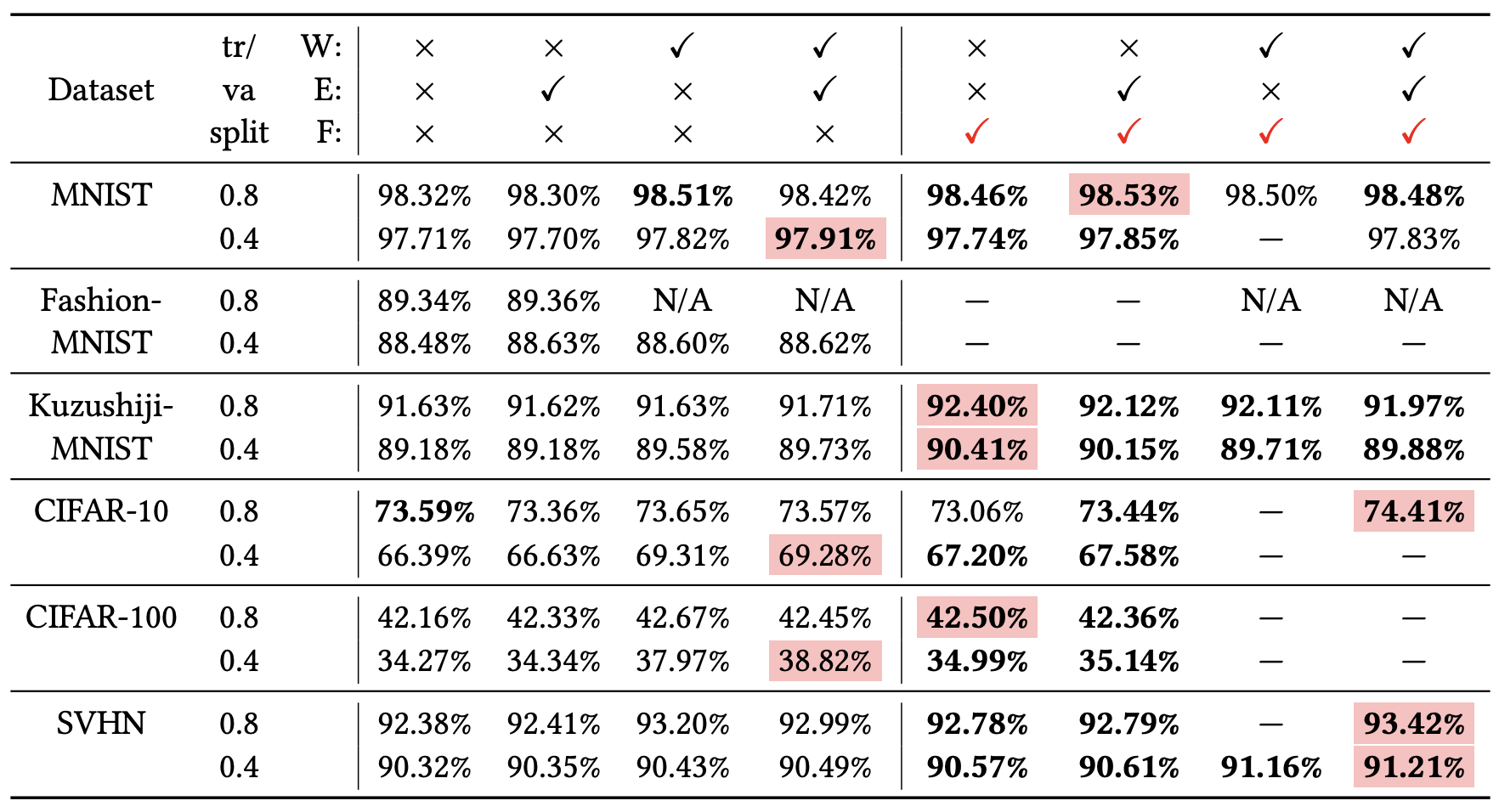
简单来说,就是最终的验证集效果可能更好些,原论文的实验结果如下:
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17343286.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号