论文信息
论文标题:Category-Adaptive Domain Adaptation for Semantic Segmentation
论文作者:Zhiming Wang, Yantian Luo, Danlan Huang, Ning Ge, Jianhua Lu
论文来源:ICASSP 2022
论文地址:download
论文代码:download
视屏讲解:click
1 摘要
UDA 面临两个问题:
- 如何缩小域差异以提高性能;
- 如何改进自监督学习(SSL)的伪标记生成机制;
Task:语义分割任务的 UDA;
方法简介:首先,将对抗性学习引入风格差距桥接机制,以保持来自相似空间中两个领域的风格信息。 其次,为了保持每个类别伪标签的平衡,提出了一种类别自适应阈值机制来为 SSL 选择类别伪标签。
2 介绍
域自适应(DA)旨在应用在源数据集上预训练的模型来泛化目标数据集。 然而,数据集之间通常存在巨大的差距,可以分为两类:基于内容的差距 和 基于风格的差距。 基于内容的差距是由数据集间的数量和类别的频率差异引起的,可以通过选择具有相似场景的数据集来缓解这种差距,因此经常为了方便而忽略它。 风格差距指的是光照、事物质感等方面的差异。然而,对样式信息进行建模仍然是一个悬而未决的学术问题。[1] 已经说明 CNN 的浅层提取低级特征,而深层提取高级特征。
此外,SSL 的域自适应已经取得了很大进展,其关键是伪标记机制。 它解决了目标域上缺少可用注释的问题。 CBST [4]引入每个类别的数量作为一个优化项,以平衡每个类别的伪标签概率。 但是,SSL 的每次迭代都需要进行排序操作,非常耗时。 BDL [5] 直接为所有类别设置了一个固定的置信度阈值,当相应的置信度分数高于该阈值时获得伪标签。 然而,固定阈值机制存在不同类别伪标签数量不同的问题,这不可避免地会影响最终的分割性能。 ADVENT [6] 在源域上引入了类别比先验来指导伪标签选择。 尽管如此,避免选择偏向简单类别的伪标签仍然具有挑战性。
贡献:
- 提出了一种基于对抗性学习的风格差距桥接机制,缩小了基于风格的差距,有助于缓解领域差异;
- 提出了一种用于伪标记的类别自适应阈值机制,以帮助 SSL 在目标域图像上;
- 对跨域分割任务进行了一系列实验,验证了我们方法的有效性和优越性;
3 方法
整体框架:
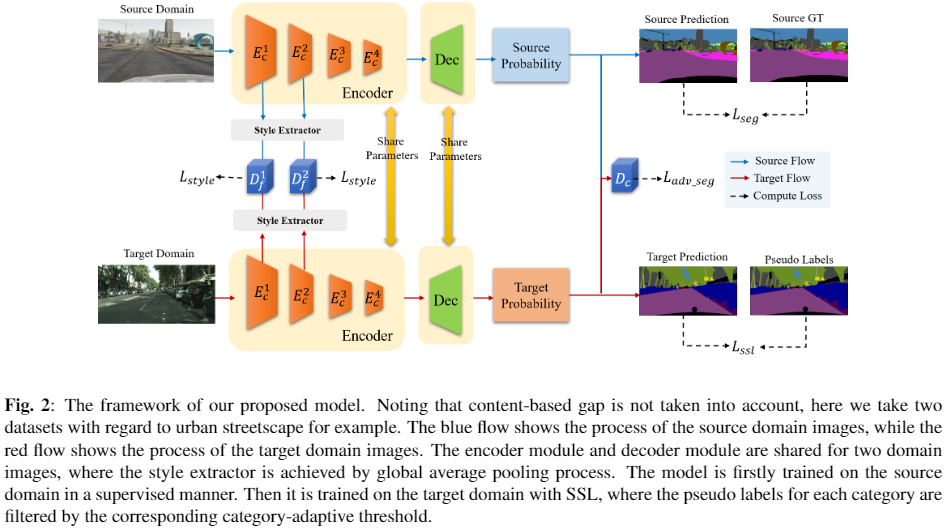
3.1 风格差距桥接机制
本文编码器的核心是保留内容信息,同时尽可能减少样式信息,因为语义性能在很大程度上取决于内容信息。 因此,缩小源域图像和目标域图像之间的风格信息差距是合理的。 在本文中,不失一般性,利用 作为 中的 ,因为通道统计显示与风格信息相关 [3]。 以前的工作 [7, 8] 通常将 MSE 作为样式约束,但是, 在高维数据上表现较差,并且受到线性和高斯假设 [9] 的限制。 相比之下,对抗性学习在理论上被证明可以缩小两个高维分布之间的差距。 在实践中,在 (即 和 )的帮助下,我们对从 2 个前端子编码器模块(即 中的 和 )提取的风格信息 应用对抗损失,其中 表示源域/目标域,。
3.2 目标域的伪标记
该小节提出一种用于 SSL 的类别自适应阈值方法。 基于的假设:由于不同类别的先验分布不均匀,预训练模型在不同类别上的表现是不同的。例如,“道路”这个类别占很大比重,而“火车”这个类别则正好相反。因此,不同类别的置信度阈值应该不同。 基于[10]的聚类方法,其中阈值由目标特征和类别质心之间的欧氏距离定义,本文认为每个类别内特征对类质心的贡献不同,因为预测置信度不同。因此,基于给定模型在目标域 上的输出,首先定义一个置信度加权的基于目标域的类别质心 :
其中 表示被判定为第 类的所有像素的预测置信度集合, 表示 的基数。, 是二元指示函数。
给定每个类别中的 ,我们的阈值基于熵距离。 第 行 列预测向量的熵 为:
类质心 的熵,即 与 类似。 直观上, 随着 的最大置信度增加而减少,因此我们选择基于熵的阈值。 这里我们定义了一个指示变量 来决定是否选择当前位置的预测作为可用的伪标签:
其中 是一个手动固定的超参数,用于控制每个类别的阈值。 当 增加时,可用伪标签的数量减少,而模型将具有更高的预测置信度,反之亦然。
3.3 损失函数
如上所述,训练过程包括两个阶段:域适应训练和 SSL。 域适应训练过程利用了以下三个损失:
分割损失
应用交叉熵函数来惩罚预测 和 one-hot ground truth 之间的误差:
基于输出的域适应损失
与 BDL [5] 一致,我们还利用 Goodfellow [11] 引入的原始 GAN 损失作为 来实现源域和目标域之间模型输出的域自适应,这是通过分段鉴别器 实现的 .
风格损失
为了帮助编码器模块 提取与风格无关的特征, 还利用了原始的 GAN 损失强制源域 上的样式信息关闭目标域 上的样式信息。
域适应训练时的损失函数总结如下
在SSL过程中,与 类似,Self-supervised Loss Lssl 也利用交叉熵函数使目标域上的预测 尽可能接近伪标签 :
4 实验
消融实验

5 总结
略
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17298525.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2020-04-08 任意进制转换