论文解读(Moco v3)《An Empirical Study of Training Self-Supervised Vision Transformers》
论文信息
论文标题:Improved Baselines with Momentum Contrastive Learning
论文作者:Xinlei Chen, Saining Xie, Kaiming He
论文来源:2021 ICCV
论文地址:download
论文代码:download
引用次数:656
1 介绍
影响自监督 ViT 模型训练的关键是:训练的不稳定性。这种训练的不稳定性所造成的结果并不是训练过程无法收敛 ,而是性能的轻微下降 (下降1%-3%的精度)。
2 方法
整体框架:
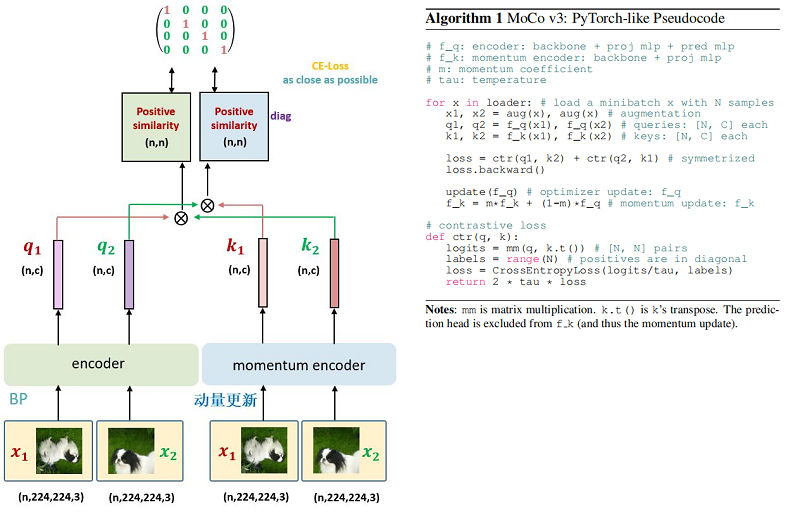
特点:
-
- 取消 Memory Queue 的机制;
- Encoder $f_{\mathrm{q}}$ 除了 Backbone 和预测头 Projection head 以外,还添加了 Prediction head;
- 对于同一张图片的 2 个增强版本 $x_{1}$, $x_{2}$ ,分别通过 Encoder $f_{\mathrm{q}}$ 和 MomentumEncoder $f_{\mathrm{Mk}}$ 得到 $q_{1}$, $q_{2}$ 和 $k_{1}$, $k_{2}$ 。让 $(q_{1}, k_{2})$ 和 $(q_{2}, k_{1})$ 通过 Contrastive loss 进行优化 Encoder $f_{\mathrm{q}}$ 的参数,Momentum Encoder $f_{\mathrm{Mk}}$ 进行动量更新;
3 总结
思路:类似于交叉注意力机制【去掉加权部分】
创兴点:
-
- 取消了 $\text{Memory bank}$ 的机制;【好处呢?】
- 将 $\text{Moco}$ 的 $\text{Query encoder}$ 的输入从一个 $\text{batch}$ 的数据转换成 一对 $\text{batch}$ 数据;
- 可以添加预测头,即在 $\text{Query encoder}$ 后面(也可以是投影头之后)添加预测头用于预测;【代码中没有体现】
不足:
-
- 重新回归到了基于 $\text{batch}$ 的训练方式,负样本的数量受限,又吃显卡;
4 其他
鹿柴 王维
空山不见人,但闻人语响。
返影入深林,复照青苔上。
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17240213.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号