论文信息
论文标题:Deep Clustering for Unsupervised Learning of Visual Features
论文作者:Mathilde Caron, Piotr Bojanowski, Armand Joulin, Matthijs Douze
论文来源:
论文地址:download
论文代码:download
引用次数:
1 前言
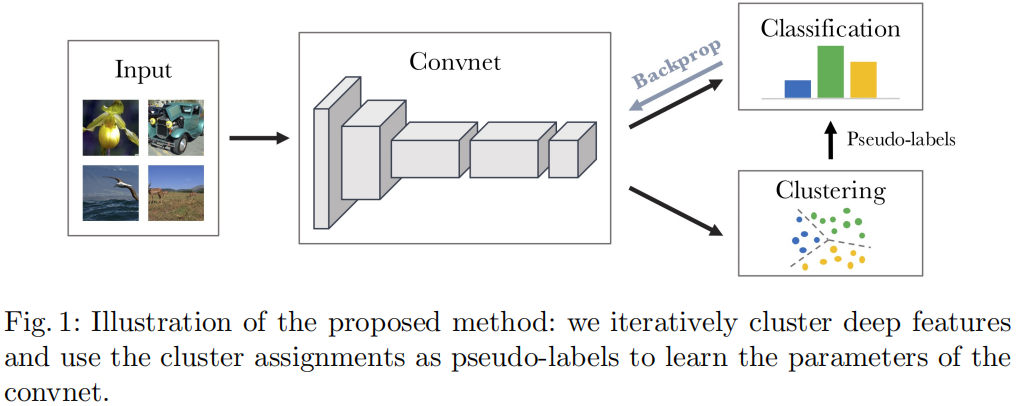
2 方法
整体框架:
Empty clusters
具体来讲,使用模型来预测伪标签,可能使得网络产生的特征经过聚类都位于某个簇心周围,而使得其他簇心没有样本,这个问题是由于没有限制某个簇心不能没有样本。
-
- 一个解决方法是限制每个簇心最少的样本数,这需要计算整个数据集,代价太高;
- 另一种方式是当某个簇心为空时,随机选择一个非空的簇心,在其上加一些小的扰动作为新的簇心,同时让属于非空簇心的样本也属于新的簇心;
Trivial parametrization
-
- 另外一个问题是大量的数据被聚类到少量的几类上,一种极端场景是被聚类到一类上,这种情况下网络可能对于任意的输入都产生相同的输出;
- 解决这个问题的方法是根据类别(或伪标签)对样本进行均匀采样;
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17230879.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律