迁移学习(EBGAN)《Energy-based Generative Adversarial Network》
论文信息
论文标题:Energy-based Generative Adversarial Network
论文作者:J. Zhao, Michaël Mathieu, Yann LeCun
论文来源:2017 aRxiv
论文地址:download
论文代码:download
引用次数:
1 前言
特点:
-
- 基于能量模型;
- 生成对抗网络;
出发点:使用 $\text{AE}$ 代替鉴别器,能量是重构误差;
2 方法
整体框架:
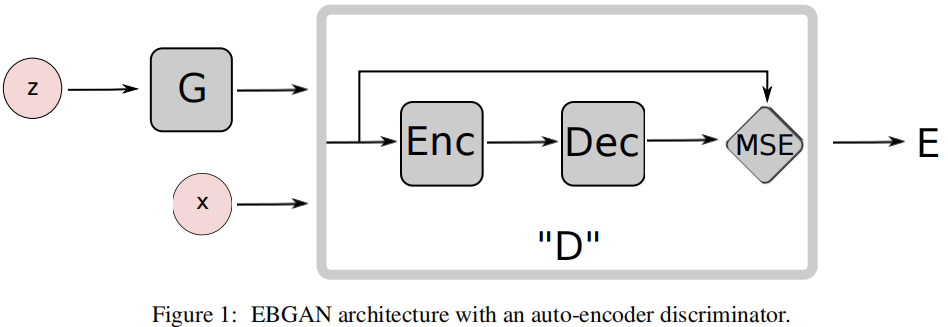
组件:
-
- 鉴别器:
$\mathcal{L}_{D}(x, z) =D(x)+[m-D(G(z))]^{+} \quad\quad(1)$
$\begin{aligned}\mathcal{L}_{\mathrm{D}}(\mathrm{x}, \mathrm{z}) & =\mathrm{D}(\mathrm{x})+[\mathrm{m}-\mathrm{D}(\mathrm{G}(\mathrm{z}))]^{+} \\& =\|\operatorname{Dec}(\operatorname{Enc}(\mathrm{x}))-\mathrm{x}\|+[\mathrm{m}-\|\operatorname{Dec}(\operatorname{Enc}(\mathrm{G}(\mathrm{z})))-\mathrm{G} (\mathrm{z})\|]^{+}\end{aligned}$
- $\mathcal{L}_{\mathrm{D}}$ 使得真实图像重构误差笑,生成图像重构误差大;
- Note:生成图像的重构误差有上界 $m$;
- 生成器:
$\mathcal{L}_{G}(z) =D(G(z)) \quad\quad(2)$
$\begin{aligned}\mathcal{L}_{\mathrm{G}}(\mathrm{z}) & =\|\mathrm{D}(\mathrm{G}(\mathrm{z}))\| \\& =\|\operatorname{Dec}(\operatorname{Enc}(\mathrm{G}(\mathrm{z})))-\mathrm{G}(\mathrm{z})\|\end{aligned}$
-
- Note:迷惑鉴别器 $\text{AE}$,使得生成图片重构误差小;
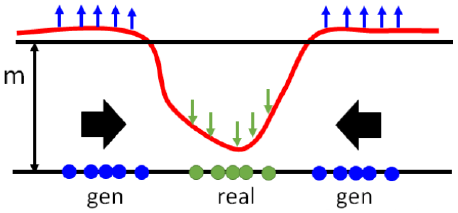
- 模型坍塌
-
-
- 模型坍塌问题是指,在某些情况下,深度学习模型在生成过程中只会生成相似或相同的输出,而不是多样化的输出。这个问题在生成式深度学习任务中尤为常见,比如图像生成或自然语言生成;
- 模型坍塌的原因是模型在训练过程中学会了只输出一种或几种很像的输出,而忽略了其他可能性。这种情况通常发生在训练数据中某一类别的样本数量过少或难以区分时。模型通过最大化生成这些样本的概率,而不是尝试生成更多不同的样本;
- 为了解决模型坍塌问题,研究人员提出了多种方法,例如正则化、增加噪声、引入对抗性损失等。这些方法可以帮助模型更好地探索数据空间,增加样本多样性,从而避免模型坍塌;
-
- 推远项
- 用来生成多样性、解决模型坍塌问题。模型要使得生成图像的重构误差倾向于 $m$ ,那么可能会生成一些重构误差为 $m$ 的同一类样本,所以为使得生成图像的多样性,期望生成的图像嵌入彼此正交:
$\mathrm{f}_{\mathrm{PT}}(\mathrm{S})=\frac{1}{\mathrm{~N}(\mathrm{~N}-1)} \sum\limits _{\mathrm{i}} \sum\limits_{\mathrm{j} \neq \mathrm{i}}\left(\frac{\mathrm{S}_{\mathrm{i}}^{\top} \mathrm{S}_{\mathrm{j}}}{\left\|\mathrm{S}_{\mathrm{i}}\right\|\left\|\mathrm{S}_{\mathrm{j}}\right\|}\right)^{2}$
-
- 模型坍塌
- 模型坍塌问题是指,在某些情况下,深度学习模型在生成过程中只会生成相似或相同的输出,而不是多样化的输出。这个问题在生成式深度学习任务中尤为常见,比如图像生成或自然语言生成;
- 模型坍塌的原因是模型在训练过程中学会了只输出一种或几种很像的输出,而忽略了其他可能性。这种情况通常发生在训练数据中某一类别的样本数量过少或难以区分时。模型通过最大化生成这些样本的概率,而不是尝试生成更多不同的样本;
- 为了解决模型坍塌问题,研究人员提出了多种方法,例如正则化、增加噪声、引入对抗性损失等。这些方法可以帮助模型更好地探索数据空间,增加样本多样性,从而避免模型坍塌;
- 模型坍塌的解决思路
- 增加模型复杂度:增加模型的层数和节点数量,提高模型的拟合能力,使模型能够更好地捕捉数据的复杂性和多样性;
- 使用正则化方法:通过L1、L2正则化等方法,限制模型的权重,减少模型的过拟合问题,从而避免模型坍塌现象的发生;
- 增加数据样本:增加训练数据样本数量,充分利用更多的数据,提高模型的泛化能力,使模型更具多样性和创造力;
- 使用对抗训练:通过对抗训练的方式,使模型在训练过程中不断与对手进行对抗和调整,从而提高模型的创造力和多样性;
- 使用注意力机制:通过引入注意力机制,使模型能够更好地关注数据的关键信息和特征,从而提高模型的表现和多样性;
- 增加模型复杂度:增加模型的层数和节点数量,提高模型的拟合能力,使模型能够更好地捕捉数据的复杂性和多样性;
- 模型坍塌
3 总结
当我看完这篇论文,立马想到使用 $AE$ 代替 $\text{DANN}$ 的域鉴别器,但是...........................悲伤总是那么多。
思路总结:
-
- 使用源域数据训练一个网络,那么训练好的网络就能很好的拟合源域数据,目标域的数据并没有参与预训练;【实际上,代码中并没有预训练的过程】
- 源域数据预训练好之后,AE 的重构误差小,目标域的数据去拟合始终会存在一个 $\text{gap}$【基于 “ 拟合困难,破坏简单” 的思想】,$\text{AE}$ 在源域数据和目标域数据之间会存在一个能量间隔,也就是 $\text{gap}$;
创新点:
从能量的角度,使用 $\text{AE}$ 代替鉴别器;
不足:
只是借鉴能量模型的思路,但是并没有真正意义上的使用能量模型,能量模型是从类分布的角度考虑;
4 代码
推远项代码:


def pullaway_loss(embeddings): norm = torch.sqrt(torch.sum(embeddings ** 2, -1, keepdim=True)) normalized_emb = embeddings / norm similarity = torch.matmul(normalized_emb, normalized_emb.transpose(1, 0)) batch_size = embeddings.size(0) loss_pt = (torch.sum(similarity) - batch_size) / (batch_size * (batch_size - 1)) return loss_pt
5 其他
春晓 唐孟浩然
春眠不觉晓,处处闻啼鸟。
夜来风雨声,花落知多少。
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17223903.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号