迁移学习(EADA)《Active Learning for Domain Adaptation: An Energy-Based Approach》【已复现迁移】
论文信息
论文标题:Active Learning for Domain Adaptation: An Energy-Based Approach
论文作者:Binhui Xie, Longhui Yuan, Shuang Li, Chi Harold Liu, Xinjing Cheng, Guoren Wang
论文来源:AAAI 2022
论文地址:download
论文代码:download
引用次数:225
0 前言
主动学习(Active Learning)的大致思路就是:通过机器学习的方法获取到那些比较“难”分类的样本数据,让人工再次确认和审核,然后将人工标注得到的数据再次使用有监督学习模型或者半监督学习模型进行训练,逐步提升模型的效果,将人工经验融入机器学习的模型中。
1 介绍
在本文中,提倡使用基于能量的模型(EBMs)来帮助实现领域转移下的主动学习的潜力。已经证明,与标准鉴别分类器相比,基于能量的训练提高了校准,更好地区分分布内和分布外样本。在这一点上,本文开始使用不同的方法来研究自由能在源域和目标域上的分布,并从 $\text{Figure1}$ 中进行了一些观察:
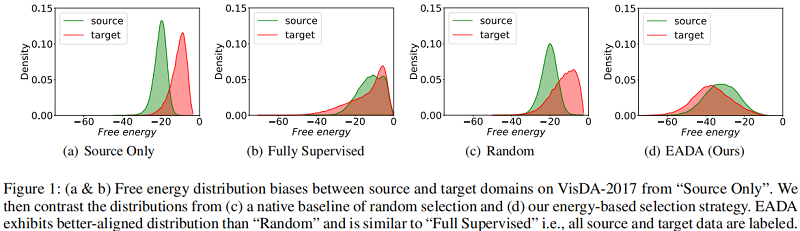
Figure1(a):仅对标记源数据进行训练的模型会导致监督源数据的自由能分布低于未标记目标数据的自由能分布,即两个域之间的自由能偏差;
Figure1(b):当对源域和目标域数据使用监督数据的时候,两者的自由能趋于一致;
Figure1(c):当在训练中随机标注一些未标记的目标数据时,偏差略微有消除;
Figure1(d):本文使用的方法;
2 问题描述
在主动域适应学习中,拥有不同数据分布的带标签源域数据 $\mathcal{S}=\left\{\left(x_{s}, y_{s}\right)\right\} $ 和不带标签的目标域数据 $\mathcal{T}=\left\{x_{t}\right\}$。根据标准的主动域适应学习,$B$ 是远小于带标签数 $\mathcal{T}$ 的采样数,目标域包括带标签样本 $\mathcal{T}_{l}$ 和不带标签样本
3 方法
3.1 基于能源的模型重新审视
机器学习的本质是对变量之间的依赖关系进行编码。考虑一个有两组变量 $x$ 和 $y$ 的基于能量的模型($\text{EBM}$)。该能量模型训练的意义是:找到一个能量函数 $E(x, y)$,使得它给正确的答案能量最低,给不正确的答案能量更高。即,模型必须产生 $E(x, y)$ 最小的值 $y^{*}$:
$y^{*}=\arg \underset{y \in \mathcal{Y}}{\text{min}} E(x, y) \quad\quad\quad(1)$
通过吉布斯分布估计输入 $x$ 和标签 $y$ 的联合概率:
$p(x, y)=\exp (-E(x, y)) / Z \quad\quad\quad(2)$
其中,$Z=\sum\limits_{x \in \mathcal{X}} \sum\limits_{y \in \mathcal{Y}} \exp (-E(x, y))$。
Note:$E(x, y)$ 越大,$p(x, y)$ 越小。
边缘化 $y$,得到 $x$ 的概率密度:
$p(x)=\sum\limits _{y \in \mathcal{Y}} p(x, y)=\sum\limits_{y \in \mathcal{Y}} \exp (-E(x, y)) / Z\quad\quad\quad(3)$
在 Active DA 中,为选择最具代表性的样本(需要优化的样本),从 $\text{Eq.3}$ 中估计每个样本的出现概率,然后选择概率 $p(x)$ 较低的样本。
由于无法计算,甚至可靠地估计 $Z$。因此,转向自由能,即 $\mathcal{F}(x)$,作为变量 $x$ 出现的 “合理性”。在数学上,$x$ 的概率密度表示为:
$p(x)=\frac{\exp (-\mathcal{F}(x))}{\sum\limits _{x \in \mathcal{X}} \exp (-\mathcal{F}(x))} \quad\quad\quad(4)$
Note:$\mathcal{F}(x)$ 越大,$p(x)$ 越小。
理解:期望 $p(x)$ 越小越好, 即 所有的 $E(x, y^i)$ 越大越好
这个公式表明,用 $\mathcal{F}(x)$ 可以代替 $p(x)$ 来选择概率较低的目标样本。通过 $\text{Eq.3}$ 和 $\text{Eq.4}$,有:
$\mathcal{F}(x)=-\log \sum\limits _{y \in \mathcal{Y}} \exp (-E(x, y))\quad\quad\quad(5)$
Note:$E(x, y^i)$ 越大,$\mathcal{F}(x)$ 越大。
3.2 基于能源的主动域自适应
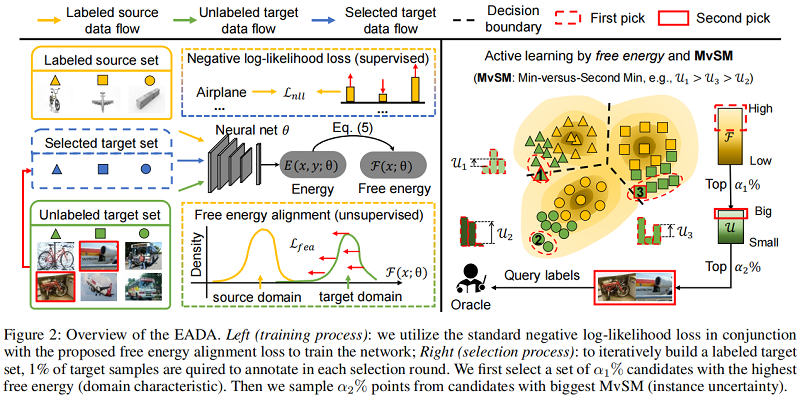
3.2.1 训练过程
给定一组标记源样本 $\mathcal{S}=\left\{\left(x_{s}, y_{s}\right)\right\}$,要想训练一个好的 $\text{EBM}$,它应该给正确答案最低的能量,给不正确的答案提供更高的能量。为此,本文利用 $\text{EBM}$ 中常用的损失来训练一个分类模型,即:
$\mathcal{L}_{n l l}(x, y ; \theta)=E(x, y ; \theta)+\frac{1}{\tau} \log \sum\limits _{c \in \mathcal{Y}} \exp (-\tau E(x, c ; \theta))\quad\quad\quad(6)$
其中 $\tau(\tau>0)$ 是 $\text{reverse temperature}$,较小的 $\tau$ 对应于空间 $y$ 上能量的平滑分配。本文固定 $\tau=1$,$\text{Eq.6}$ 等价于:
$\mathcal{L}_{n l l}(x, y ; \theta)=E(x, y ; \theta)-\mathcal{F}(x ; \theta)\quad\quad\quad(7)$
交叉熵损失函数 $\operatorname{loss}(x, \text { class })=-\log \left(\frac{\exp (x[\text { class }])}{\sum\limits _{j} \exp (x[j])}\right)=-x[\text { class }]+\log \left(\sum\limits_{j} \exp (x[j])\right)$
Note:$\text{Eq.7}$ 中的第二项将导致正确和错误答案的能量将被拉上来,但是提升不明显。
从 $\text{Figure 1}$ 中,目标域样本的自由能值明显高于源域样本上的自由能,这被称为 自由能偏差。本文将它作为反映域差异的替代品,通过设计一个简单的正则化项,来减少自由能偏差,这在某种程度上减少了域差异,该正则化项称之为 自由能对齐损失 $\mathcal{L}_{fea}$:
$\mathcal{L}_{\text {fea }}(x ; \theta)=\max (0, \mathcal{F}(x ; \theta)-\Delta)\quad\quad\quad(8)$
其中,$\Delta=\mathbb{E}_{x \sim \mathcal{S}} \mathcal{F}(x ; \theta)$ 为源域数据上自由能平均值。
在训练期间,$\Delta$ 估计通过指数移动平均估计:$\Delta_{t}=\lambda \Delta_{t-1}+(1-\lambda) \Delta_{t}^{\prime}$,其中 $\Delta_{t}^{\prime}$ 是第 $t$ 个 minibatche 的平均值,$\lambda$ 是从均匀分布中采样的权重 $\lambda \sim U(0,1)$。实验证明,这种方法可以与计算整个源域数据的平均值相当,同时提高了效率。
完整的学习目标是:
$\underset{\theta}{\text{min}} \; \mathbb{E}_{(x, y) \sim \mathcal{S} \cup \mathcal{T}_{l}} \mathcal{L}_{n l l}(x, y ; \theta)+\gamma \mathbb{E}_{x \sim \mathcal{T}_{u}} \mathcal{L}_{\text {fea }}(x ; \theta)\quad\quad\quad(9)$
3.2.2 选择过程
Active DA的目标是识别更多有价值的目标样本,这些样本一旦被标记并用于训练,就可以显著提高模型的准确性和泛化性能。在实践中,我们提出了一种两步抽样策略,通过结合域特征和实例的不确定性来充分保证这些样本。需要说明的是,我们将基于上述讨论的训练和选择过程总结为算法1。

第一步:我们观察到源域和目标域之间的自由能分布存在偏差。因此,我们可以利用未标记目标样本的固有自由能作为替代度量来反映域特征。当然,具有较高自由能的目标样品对目标分布是唯一的,同时与标记的源数据是互补的。
第二步:为了测量实例的不确定性,现有的方法主要依赖于熵值分数。相反,我们将两个答案的能量值之间的差异与最低的估计能量值作为不确定性的度量。由于它是对最小答案和第二个最小答案的比较,我们将它称为 Min-versus-Second-Min(MvSM)策略,它可以表述为
$\mathcal{U}(x)=E\left(x, y^{*} ; \theta\right)-E\left(x, y^{\prime} ; \theta\right)\quad\quad\quad(10)$
其中 $y^{*}=\arg \min _{y \in \mathcal{Y}} E(x, y ; \theta)$ 是最低能量输出, $y^{\prime}=\arg \min _{y \in \mathcal{Y}} \backslash\left\{y^{*}\right\} E(x, y ; \theta)$ 是第二低能量输出。这种衡量方法是从分类的角度来估计阶级成员混淆的一种更直接的方法。使用MvSM度量,将在选择过程中选择 Fig.2 中决策边界周围的实例来查询一个 oracle。
主动学习参考资料:https://zhuanlan.zhihu.com/p/239756522?utm_source=zhsharetargetidmore
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17062137.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号