论文信息
论文标题:Improve Unsupervised Domain Adaptation with Mixup Training
论文作者:Shen Yan, Huan Song, Nanxiang Li, Lincan Zou, Liu Ren
论文来源:arxiv 2020
论文地址:download
论文代码:download
引用次数:93
1 Introduction
现有方法分别对源域和目标域施加约束,忽略了它们之间的重要相互作用。本文使用 mixup 来加强训练约束来直接解决目标域的泛化性能。
当前工作假设:当在表示级处理域差异时,训练后的源分类器能够在目标域上自动取得良好的性能。然而,当前研究表明,在两个域上都表现良好的分类器可能不存在 [6,7],所以仅依赖源分类器可能导致目标域的显著错误分类。现有最先进的方法在对抗学习过程中寻求额外的训练约束,不过他们都是在所选择的域独立地使用训练约束,而不是联合约束。这使得这两个域之间的重要相互作用尚未被探索,并可能会显著限制训练约束的潜力。
本文通过简单的 ,证明了引入该训练约束可以显著提高模型适应性能。
:给定一对样本 、 ,生成的增强表示为:
其中,。
通过使用 训练,鼓励了模型的线性行为,其中原始数据中的线性插值导致预测的线性插值。
2 Problem Statement
The overview of IIMT framework is shown in . We denote the labeled source domain as set and unlabeled target domain as set . Here denotes one-hot labels. The overall classification model is denoted as with the parameterization by . Following prominent approaches in UDA [6, 7], we consider the classification model as the composite of an embedding encoder and an embedding classifier . Note that encoder is shared by the two domains. The core component in our framework is mixup, imposed both across domains (Inter-domain in ) and within each domain (Intra-domain (source) and Intradomain (target) in . All mixup training losses and the domain adversarial loss are trained end-to-end.
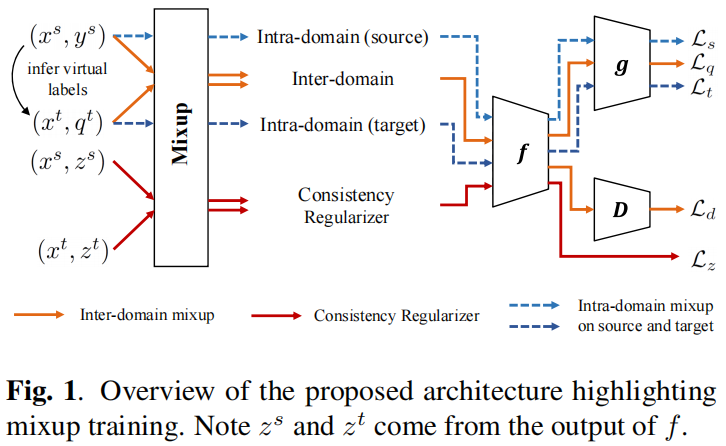
3 Method
3.1 Inter-domain Mixup Training
本文框架中的关键组件:源域和目标域之间的 训练。在 的训练中, 提供了插值标签来强制分类器跨域的线性预测行为。与单独使用源标签训练相比,它们导致了一种简单的归纳偏差,但本文可以直接提高分类器对目标域的泛化能力。
训练需要样本标签来进行插值,本文利用推断出的标签作为对目标域的弱监督。类似的想法在半监督学习设置[10,9]中被证明在开发相关的未标记数据方面是非常有效的。
首先,对目标域每个数据样本执行 个任务相关的随机增强,以获得转换后的样本 。然后,计算目标域的虚拟标签:,归一化为 ,使用较小的 产生更清晰的预测分布。

其中, 代表 , 为交叉熵损失, 加权参数根据: 和 选择。
当设置 接近于 时,从范围 中选择 为中间值的概率更大,使得两个域之间的插值水平更高。请注意, 始终超过 ,以确保源域占主导地位。同样地,也可产生目标域主导的 ,只需要通过在 中切换 和 的系数,对应地形成 。使用目标域主导的 ,采用均方误差(MSE)损失,因为它更能容忍目标域中的虚假虚拟标签。
3.1.1 Consistency Regularizer
在域差异非常大的情况下,域间 所施加的线性约束可能效果较差。具体来说,当异构的原始输入在 中被插值时,迫使模型 产生相应的插值预测变得更加困难。同时,对于特征级域混淆的域对抗损失的联合训练会增加训练难度。
因此,本文为潜在特征设计一个一致性正则化器,以更好地促进域间 训练:
即:通过两个向量之间的 损失,使混合特征更接近于混合输入的特征。这个正则化器的作用:当 强制 , 通过浅分类器 ,模型预测的线性更容易满足。
3.1.2 Domain Adversarial Training
最后一个组成部分是使用标准的域对抗性训练来减少域的差异。本文的实现限制在更基本的 DANN 框架[1]上,以试图集中于评估混合线性约束。在DANN中,一个域鉴别器和共享嵌入编码器(生成器)在对抗性目标下进行训练,使编码器学习生成域不变特征。本文的源和目标样本 的域对抗性损失:



adversarial_loss = torch.nn.BCELoss() # 损失函数(二分类交叉熵损失) generator = Generator() #生成器 discriminator = Discriminator() #鉴别器 optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2)) # 生成器优化器 optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2)) # 鉴别器优化器 for epoch in range(opt.n_epochs): for i, (imgs, _) in enumerate(dataloader): # Adversarial ground truths valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False) #torch.Size([64, 1]) fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False) #torch.Size([64, 1]) real_imgs = Variable(imgs.type(Tensor)) #torch.Size([64, 1, 28, 28]) 真实数据 # ----------------------> 训练生成器 [生成器使用噪声数据,使得其尽可能为真,迷惑鉴别器] optimizer_G.zero_grad() z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim)))) #torch.Size([64, 100]) gen_imgs = generator(z) #torch.Size([64, 1, 28, 28]) g_loss = adversarial_loss(discriminator(gen_imgs), valid) g_loss.backward() optimizer_G.step() # ----------------------> 训练鉴别器 [ 尽可能将真实数据和噪声数据区分开] optimizer_D.zero_grad() real_loss = adversarial_loss(discriminator(real_imgs), valid) fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake) d_loss = (real_loss + fake_loss) / 2 d_loss.backward() optimizer_D.step()
3.2 Intra-domain Mixup Training
给定源标签和目标虚拟标签, 训练也可以在每个域内执行。由于在同一域内的样本遵循相似的分布,因此不需要应用特征级的线性关系。因此,只对这两个领域使用标签级 训练,并定义它们相应的损失:
虽然域内混合作为一种数据增强策略是直观的,但它对 UDA 特别有用。正如在[6]中所讨论的,没有局部约束的条件熵的最小化会导致数据样本附近的预测突变。在[6]中,利用虚拟对抗训练[10]来增强邻域的预测平滑性。不同的是,我们发现域内混合训练能够实现相同的目标。
3.3 Training Objective
训练目标:
由于 只涉及虚拟标签,因此很容易受到目标域的不确定性的影响。本文为训练中的 设置了一个线性时间表,从 到一个预定义的最大值。从初始实验中,观察到该算法对其他加权参数具有良好的鲁棒性。因此,只搜索 ,而简单地将所有其他权重固定为 。
4 Experiment
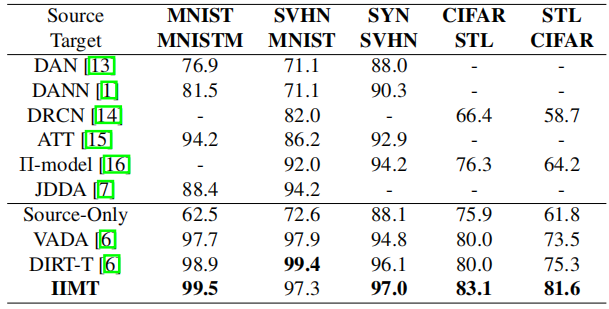
For image classification experiments, we evaluate on MNIST, MNIST-M, Street View House Numbers (SVHN), Synthetic Digits (SYN DIGITS), CIFAR-10 and STL-10.
A → B to denote the domain adaptation task with source domain A and target domain B.
前三:手写数组识别;后二:目标检测:
消融实验:

Note
条件熵:条件熵 表示在已知随机变量 的条件下随机变量 的不确定性。
import torch from torch.autograd import Function import torch.nn as nn import torch.nn.functional as F class ReverseLayerF(Function): @staticmethod def forward(ctx, x, alpha): print("forward===========================") print("xx = ",x) ctx.alpha = alpha ctx.feature = x return x.view_as(x) @staticmethod def backward(ctx, grad_output): print("backward===========================") print("grad_output = ",grad_output) output = grad_output.neg() * ctx.alpha return output, None class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.featurizer = nn.Linear(4,3) self.classifier = nn.Linear(3,2) self.discriminator = nn.Linear(3,2) self.alpha = 1 def forward(self,x,disc_labels,label): # 特征提取 z = self.featurizer(x) print("z = ",z) disc_input = z disc_input = ReverseLayerF.apply(disc_input, self.alpha) disc_out = self.discriminator(disc_input) disc_loss = F.cross_entropy(disc_out, disc_labels) all_preds = self.classifier(z) classifier_loss = F.cross_entropy(all_preds,label) loss = classifier_loss + disc_loss loss.backward() return x = torch.tensor([[ 1.1118, 1.8797, -0.9592, -0.6786], [ 0.4843, 0.4395, -0.2360, -0.6523], [ 0.7377, 1.4712, -2.3062, -0.9620], [-0.7800, 1.8482, 0.0786, 0.0179]], requires_grad=True) disc_labels = torch.LongTensor([0,0,1,1]) label = torch.LongTensor([0,0,1,1]) print("x = ",x) print("disc_labels = ",disc_labels) print("label = ",label) print("+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++") model = Net() model(x,disc_labels,label)
adversarial_loss = torch.nn.BCELoss() # 损失函数(二分类交叉熵损失) generator = Generator() #生成器 discriminator = Discriminator() #鉴别器 optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2)) # 生成器优化器 optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2)) # 鉴别器优化器 for epoch in range(opt.n_epochs): for i, (imgs, _) in enumerate(dataloader): # Adversarial ground truths valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False) #torch.Size([64, 1]) fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False) #torch.Size([64, 1]) real_imgs = Variable(imgs.type(Tensor)) #torch.Size([64, 1, 28, 28]) 真实数据 # ----------------------> 训练生成器 [生成器使用噪声数据,使得其尽可能为真,迷惑鉴别器] optimizer_G.zero_grad() z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim)))) #torch.Size([64, 100]) gen_imgs = generator(z) #torch.Size([64, 1, 28, 28]) g_loss = adversarial_loss(discriminator(gen_imgs), valid) g_loss.backward() optimizer_G.step() # ----------------------> 训练鉴别器 [ 尽可能将真实数据和噪声数据区分开] optimizer_D.zero_grad() real_loss = adversarial_loss(discriminator(real_imgs), valid) fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake) d_loss = (real_loss + fake_loss) / 2 d_loss.backward() optimizer_D.step()
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/17028724.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix