论文信息
论文标题:Rumor detection based on propagation graph neural network with attention mechanism
论文作者:Yunrui Zhao, Qianqian Xu, Yangbangyan Jiang, Peisong Wen, Qingming Huang
论文来源:aRxiv 2020
论文地址:download
论文代码:download
1 Introduction
四种 "谣言":
- non rumors, namely verified information
- true rumors, namely the unverified information that turns out to be true
- false rumors, namely the unverified information that turns out to be false
- unconfirmed rumors, namely the unverified information that remains unresolved
贡献:
-
- 提出了一种显式构造谣言传播图的新方法
- 提出了一种基于门控图神经网络的表示学习算法
- 提出了两种不同分类策略的谣言检测模型
- 为了提高检测性能,引入了注意机制
2 Method
2.1 Text embedding
使用 word2vec 获得文本向量的方法:通常先讲每个单词表示为一个词向量,然后用词向量的平均作为整个句子的表示。社交媒体通常对于最大字数有限制,如微博最多允许发布 5000 字(2022年),但是通常我们的数据集帖子一般都很短,甚至就几个词,word2vec 算法通常不工作在这样的应用程序场景。本文使用 word2vec 算法的扩展方法—— Doc2vec 来生成推文内容的表示。Doc2vec 也被称为 paragraph2vec 或 sentence embedding ,它可以为一个短的文本甚至一个句子生成强大的表示。
2.2. Node update
使用 Doc2vec 算法得到传播图中每个节点的原始表示 h(0)v。然而,这种节点表示 h(0)v 只考虑了文本内容,而忽略了邻域节点的信息和传播图中的拓扑结构。
在单个迭代步骤中,邻居节点首先通过不同类型的关系路径交换信息,然后通过聚合邻域信息和它们自己的信息来更新它们的表示。因此,新获得的节点表示法同时包含了文本信息和上下文信息。
节点 v 的消息聚合函数:
h(t)v=∑u∈IN(v)|R|∑i=1I(Ψ(eu,v)==ri)αiWih(t−1)u+bi,|R|∑i=1αi=1(1)
其中,R 是关系路径的集合,|R| 表示关系路径类型的总数。【两种关系路径:如下的实线和虚线】
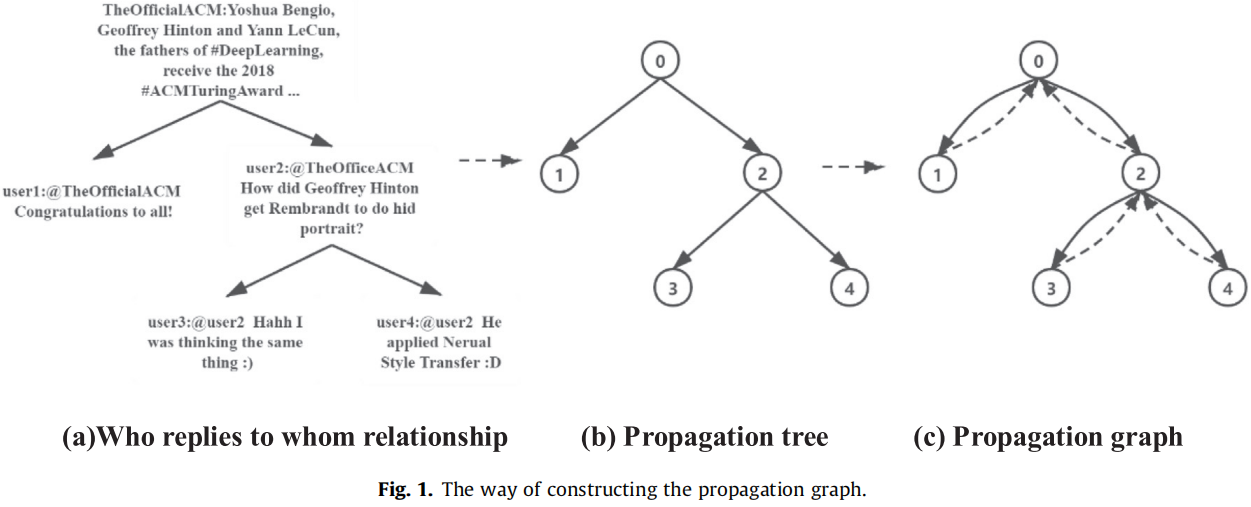
根据 Eq.1 这种方式能很快收敛到最终的表示(过平滑)。本文将门控机制纳入 Eq.1 的更新过程中,优点是消除过平滑。
门控循环神经网络有两种常见的变体:1)long short-term memory(LSTM)、gated recurrent units(GRU)。在这项工作中,本文使用 GRU 作为隐藏单元,而不是 LSTM 来提高效率,因为 GRU 使用了一个更简单的架构,并且可以以更少的参数实现几乎相同的性能
从步骤 t−1 到步骤 t 的更新过程如下所示:
δ(t)v=∑u∈N(v)|R|∑i=1I(Ψ(eu,v)==ri)αiWih(t−1)u+bi(2)z(t)v=σ(Wzδ(t)v+Uzh(t−1)v)(3)r(t)v=σ(Wrδ(t)v+Urh(t−1)v)(4)~h(t)v=tanh(~Wδ(t)v+~U(r(t)v⊙h(t−1)v))(5)h(t)v=(1−z(t)v)⊙h(t−1)v+z(t)v⊙~h(t)v(6)
其中:
-
- ⊙ 是元素乘;
- 重置门 r(t)v 决定着有多少之前的隐藏状态 h(t−1)v 被保存到当前的隐藏状态 ~h(t)v;
- 更新门 z(t)v 根据候选状态 ~h(t)v 和之前的状态 h(t−1)v 确定如何获取当前隐藏状态 h(t)v;
- σ(x) 和 tanh(x) 是激活函数;
Note:上述公式可以理解为 GNN 消息聚合 + GRU (不带偏置项)【直接将 GNN 的输出作为 GRU 的输入】
门控机制的好处:1) 可以控制信息的累积速度;2) 可以减少过度迭代引起的噪声;
GRU 的回顾:
rt=σ(Wirxt+bir+Whrh(t−1)+bhr)zt=σ(Wizxt+biz+Whzh(t−1)+bhz)nt=tanh(Winxt+bin+rt∗(Whnh(t−1)+bhn))ht=(1−zt)∗nt+zt∗h(t−1)
Fig.2 展示了节点 v 根据 Eq.2---Eq.6 的更新过程:【黑色的 dash line 代表感受野】
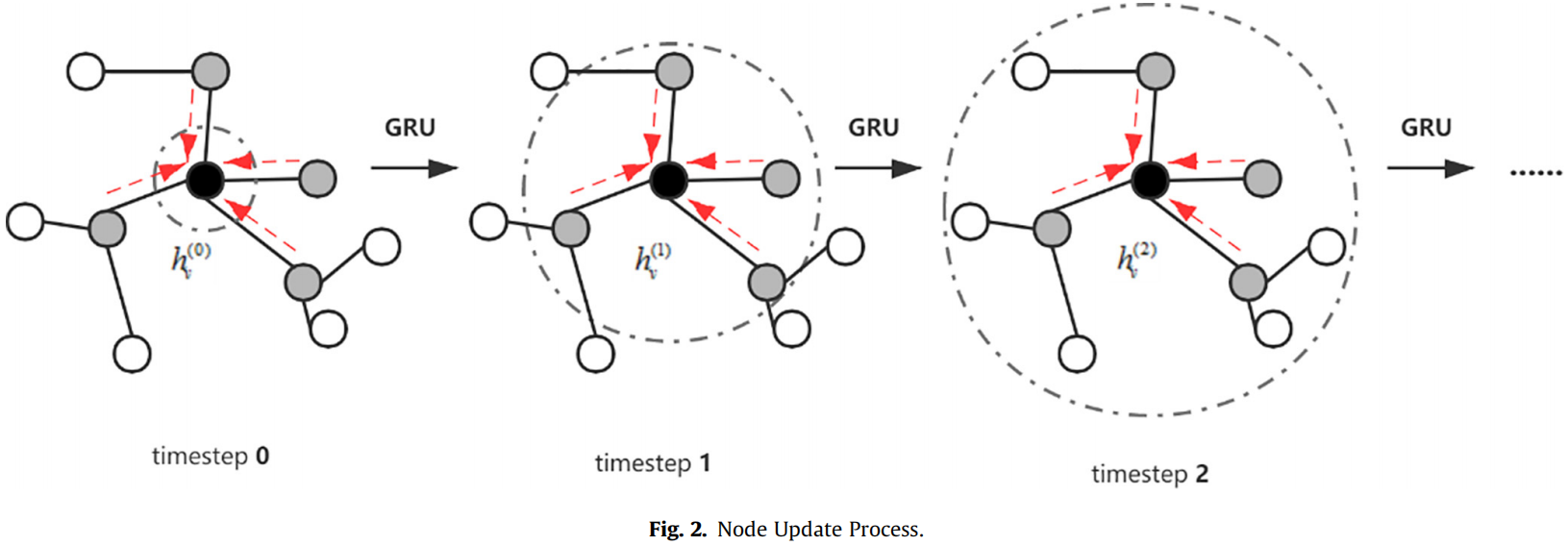
当在等式之后聚合来自邻居的信息时,我们加入了注意机制来调整权重,修正后的方程式显示为 Eq.7:
δ(t)v=∑u∈I(v)|R|∑i=1I(Ψ(eu,v)==ri)αiatt(t−1)uWih(t−1)u+bi(7)
注意力得分 att(t−1)u 如下:
att(t)u=exp(h(t)u⋅h(t)v)∑u′∈N(v)exp(h(t)u′⋅h(t)v),u∈IN(v)(9)
根据上述过程更新 T 次后,可以得到传播图中每个节点的最终表示。但由于表示的表达能力是通过单层的图神经网络学习的。我们提出的算法也使用了多层架构,更新过程如 Eq.2 到 Eq.6 所示,但是不同层的参数可能完全不同,这使得每一层在更新节点表示时都要关注不同的信息。相邻层中节点表示的关系如下:
∀v∈V,h(0)v(m+1)=h(Tm)v(m)(10)
其中 Tm 为在第 m 层的总更新时间,h(t)v(m) 为节点 v 在第 m 层更新 t 次后的隐藏状态。
完整算法如下:

2.3 Classifification
Idea1:谣言检测可以看成一个图分类问题:
将所有节点的表示平均池化,并放入 FC 中进行分类:
g=tanh((1N∑v∈VHv)TWg+bg)(10)
^y=softmax(F(g))(11)
Idea2:首先根据每个节点的表示来计算单个的预测概率,然后使用线性求和得到最终的结果:
^y=softmax(∑v∈Vσ(HTνWe+be))(13)
3 Experiment
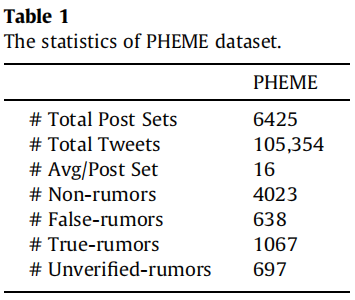
Datasets
Evaluation metrics
Precision =TPTP+FP Recall =TPTP+FNF1=2 Precision ⋅ Recall Precision + Recall
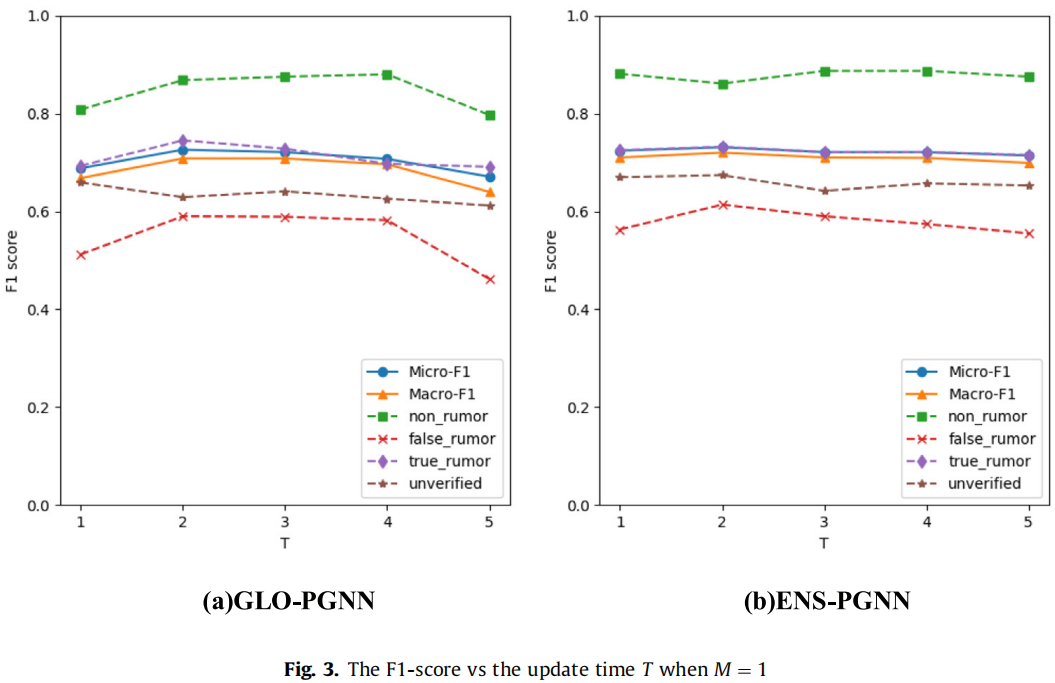
Result


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY