虚假新闻检测(DITFEND)《Improving Fake News Detection of Influential Domain via Domain- and Instance-Level Transfer》
论文信息
论文标题:Improving Fake News Detection of Influential Domain via Domain- and Instance-Level Transfer
论文作者:Qiong Nan, Danding Wang, Yongchun Zhu, Qiang Sheng, Yuhui Shi, Juan Cao, Jintao Li
论文来源:COLING 2022
论文地址:download
论文代码:download
1 Introduction
跨领域虚假新闻检测存在两个挑战:(1) 多领域学习的“跷跷板”现象。一些领域上虚假新闻检测效果的提升往往伴随着在另外一些领域上效果的损失;(2)不同样例的可迁移性不同。
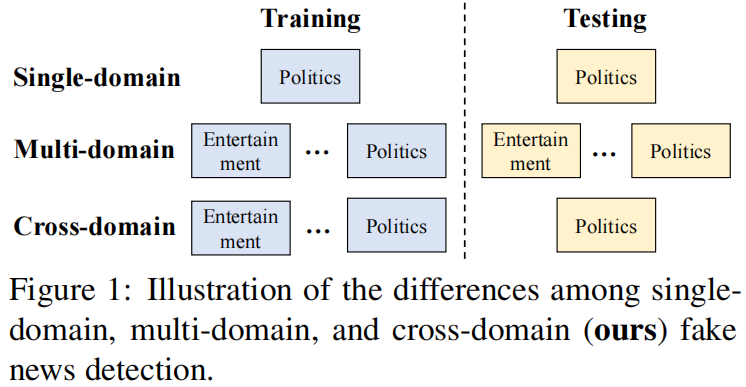
本工作中,我们采用跨领域虚假新闻检测范式,即考虑不同领域新闻之间的联系,利用其它领域的数据提高目标领域虚假新闻的检测效果。单领域虚假新闻检测、多领域虚假新闻检测和跨领域虚假新闻检测的对比如下图所示。
我们希望设计一套机制,从而(1)缓解多领域建模中的“跷跷板”现象,提升模型的泛化能力;(2)区分不同源领域样本的可迁移性。基于上述思考,我们提出了基于领域和样例级别迁移的跨领域虚假新闻检测方法DITFEND。具体地,我们通过元学习的方式在多个领域上训练得到一个具有较强的泛化能力的模型;为了评估不同源领域数据的可迁移性,我们训练得到目标领域的语言模型并在源领域样本上计算该模型的困惑度,以此来衡量样本的可迁移性并对其进行加权;最后我们使用目标领域样本和加权的源领域样本微调可泛化模型,从而提升模型在目标领域的虚假新闻检测性能。
贡献:
- 首次探索了利用多个源领域提升目标领域性能的跨领域虚假新闻检测问题;
- 提出了基于领域和样例级别迁移的跨领域虚假新闻检测方法 DITFEND;
- 通过离线实验(中文、英文数据集)和线上实验证明了 DITFEND 的有效性;
2 相关工作
2.1 假新闻检测
现有的假新闻检测方法通常可以分为两个类:基于社会上下文的方法 和 基于内容的方法。
基于社会上下文的方法:一些分析传播模式挖掘结构信号进行假新闻检测,其他人利用群体智能,如情感和立场来检测假新闻,捕捉环境信号来检测假新闻帖子。
或基于内容的方法,一些从外部来源提取证据,而其他人只分析新闻本身,专注于更好的构建特征,这属于我们的研究范围。
由于现实世界的新闻平台将新闻文章分为不同的领域,一些研究人员关注每个领域的假新闻检测性能,特别是那些具有严重社会影响的领域。有些只考虑一个特定领域,执行单域假新闻检测(Wang,2017;阿尔科特和根茨科,2017;Bovet和Makse,2019;戴等,2020;崔等,2020;周等,2020;尚等,2022),但他们忽略了来自其他领域的有用信息。一些方法同时对各个领域进行建模,以提高所有域的整体性能(多域假新闻检测)(Wangetal.,2018;Silva等,2021;Nan等,2021;Zhu等,2022),但由于跷跷板现象,部分目标域的性能出现退化。.Huang等人(2021)和Mosallanezhad等人(2022)提出采用域自适应策略进行跨域假新闻检测,但他们只将知识从一个源域转移,以确保模型在目标域上的检测性能。然而,在实际场景中,来自多个源域的新闻片段与目标域内在地相关。将所有源域合并到一个域中,并执行跨域假新闻检测(Huang et al.,2021)和(had等人,2022),但改进可能并不显著。因此,有必要找到一种更好的方法来充分利用所有的源域来提高目标域的性能。
2.1 迁移学习
迁移学习的目的是利用来自源领域的知识来提高学习性能或最小化目标领域中所需的标记示例的数量(Pan and Yang,2010;Zhuang等人,2021)。最近,迁移学习已被广泛应用于自然语言处理(Devlin等人,2019年;刘等人,2019年;刘易斯等人,2020年),如情感分类(Peng等人,2018年)、神经机器翻译(Kim等人,2019年)、风格转移(Yang等人,2018年)。同时,元学习作为一种范例,可以用来改善迁移学习问题(hesedales等人,2022)。元学习得益于整合以往经验以及所有领域的普遍性,已被广泛应用(Li等人,2018;Wang等人,2021)。在本文中,我们提出了一种基于元学习的跨域假新闻检测传输框架。
2 Method
我们框架的核心思想是利用来自所有领域的新闻来训练目标假新闻检测器。主要包括三个阶段:第一阶段,用来自所有领域的新闻来训练一个通用模型,这样模型就可以缓解跷跷板现象(即 domain-level transfer);在第二阶段,评估和量化来自源域的实例可迁移性;在第三阶段,将一般模型调整到目标域。
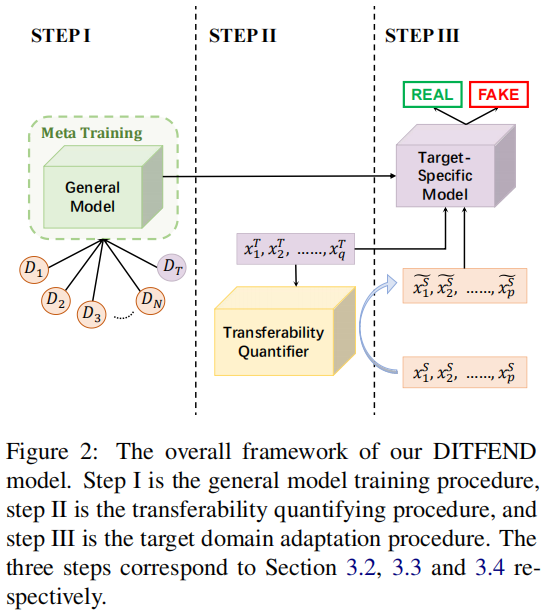
2.1 General Model Training
对于域级别的迁移,采用元学习的方式训练一个可泛化模型,使得该模型学习到所有领域的知识。
训练流程如下所示:

在元学习的方式下,除了基础模型参数之外,每一个任务都有其对应的一组模型参数。在每一次模型参数更新过程中,本文将一个批量的数据划分成 $n$ 组数据,分属于 $n$ 个任务,对于每一组任务数据,我们将其划分成 Suport set $\mathcal{D}_{d}^{s}$ 和 Query set $\mathcal{D}_{d}^{q}$,模型首先在 Suport set 上训练并通过交叉熵计算得到对应的分类损失:
$\mathcal{L}_{d}^{s}(\theta)=\frac{1}{m_{s}} \sum_{i=1}^{m_{s}}-y_{i} \log \hat{y}_{i}-\left(1-y_{i}\right) \log \left(1-\hat{y}_{i}\right) \quad\quad\quad(1)$
其中 $m_{s}$ 是当前 Suport set 的数据量, $y_{i}$ 为第 $i$ 个数据的真实标签, $\widehat{y_{i}}$ 为第 $\mathrm{i}$ 个数据的预测标签值,根据该损失更新当前任务数据对应的模型参数 $\theta_{d}$ :
之后,当前任务的模型被赋予参数 $\theta_{d}$ ,并在当前任务数据的 Query set 上计算损失:
$L_{d}^{q}\left(\theta_{d}\right)=\frac{1}{m_{q}} \sum_{i=1}^{m_{q}}-y_{i} \log \widehat{y_{i}}-\left(1-y_{i}\right) \log \left(1-\widehat{y_{i}}\right) \quad\quad\quad(2)$
其中 $m_{q}$ 是当前任务 Query set 的数据量,$y_{i}$ 为第 $i$ 个数据的真实标签, $\widehat{y_{i}}$ 为第 $\mathrm{i}$ 个数据的预测标签值, 当遍历完一个批量数据的所有任务之后,累加在每一个任务的 Query set 上计算得到的损失 $L_{i}^{q}$ ,并根 据该损失更新模型参数:
$\theta=\theta-\beta \nabla_{\theta} \sum_{i=1}^{n} L_{i}^{q} \quad\quad\quad(3)$
2.2 Transferability Quantifying
首先,我们训练得到一个目标领域自适应的语言模型:对于目标领域中的每一个数据,进行分词后 得到包含 $m$ 个词元的序列 $\left\{w_{0}, \ldots, w_{m-1}\right\}$ ,之后通过掩码语言建模任务 (Masked Language Modeling)在目标领域上训练语言模型,通过最小化交叉熵损失来更新语言模型,最终得到目标 领域自适应的语言模型。之后,将源领域的每一条数据 $ P_{s}$ 进行分词得到
$P_{s}=\left\{[C L S], w_{0}, \ldots, w_{m-1},[S E P]\right\} \quad\quad\quad(4)$
通过依次掩盖每个位置的词元得到掩码后数据:
$P_{\text {mask }}=\left\{[C L S], \ldots, w_{i-1},[M A S K], w_{i+1}, \ldots,[S E P]\right\} \quad\quad\quad(5)$
使用目标领域自适应的语言模型预测源领域数据中的每一个词元并计算其预测正确的概率 $\operatorname{prob}\left(w_{i}\right)=M L M\left(\mathcal{P}, w_{i}\right)$ , 以计算语言模型在该样本上的困惑度 $p$ :
$\operatorname{prob}\left(w_{i}\right)=M L M\left(P_{\text {mask }}, w_{i}\right)\quad\quad\quad(6)$
源领域数据的可迁移性可通过如下方式表示:
$w=1 / p p \quad\quad\quad(5)$
2.3 Target Domain Adaptation
为了使 2.1 节中得到的可泛化模型适应目标领域,我们同时使用目标领域数据和根据可迁移性加权的源领域数据训练可泛化模型,通过最小化交叉熵损失进行优化,最终得到适应目标领域的模型。
$L^{c e}(y, \hat{y})=-y \log \hat{y}-(1-y) \log (1-\hat{y}) \quad\quad\quad(6)$
$L=\mathbb{E}_{(x, y) \sim p_{s}(x, y)} w(x) L^{c e}(y, \hat{y})+\mathbb{E}_{(x, y) \sim p_{t}(x, y)} L^{c e}(y, \hat{y})$
其中 $y$ 为样本真实值, $\hat{y}$ 为样本预测值,$L^{c e}(y, \hat{y})$ 为交叉熵损失函数,$w(x)$ 为源领域样本权重。
3 Experiment
本文分别在中文数据集和英文数据集上进行了实验。中文数据集采用 Weibo21 数据, 英文数据集我们使用 FakeNewsNet[4](分为政治部分 PolitiFact 和娱乐部分GossipCop)以 及COVID 组成三个领域。
数据统计如下表所示:
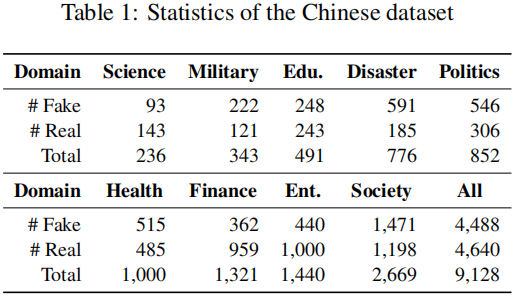
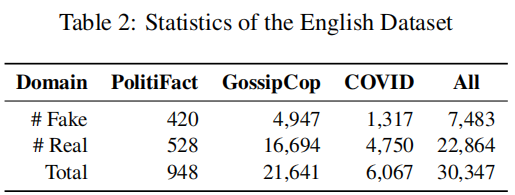
在我们的实验中,为了分析领域数量的影响,我们从中文数据的9个领域中选择了3个领域(政治,健康和娱乐)构成Ch-3数据集,选择了 6 个领域(教育考试、灾难事故、健康、财经商业、娱乐和社会生活)构成 Ch-6 数据集。对于 Ch-9 和 Ch-3 数据集,我们将健康和政治作为目标领域,对于 Ch-6 数据集,我们将财经商业和健康作为目标领域,对于英文数据集,我们将 PolitiFact 和 COVID 作为目标领域。
Performance Comparison
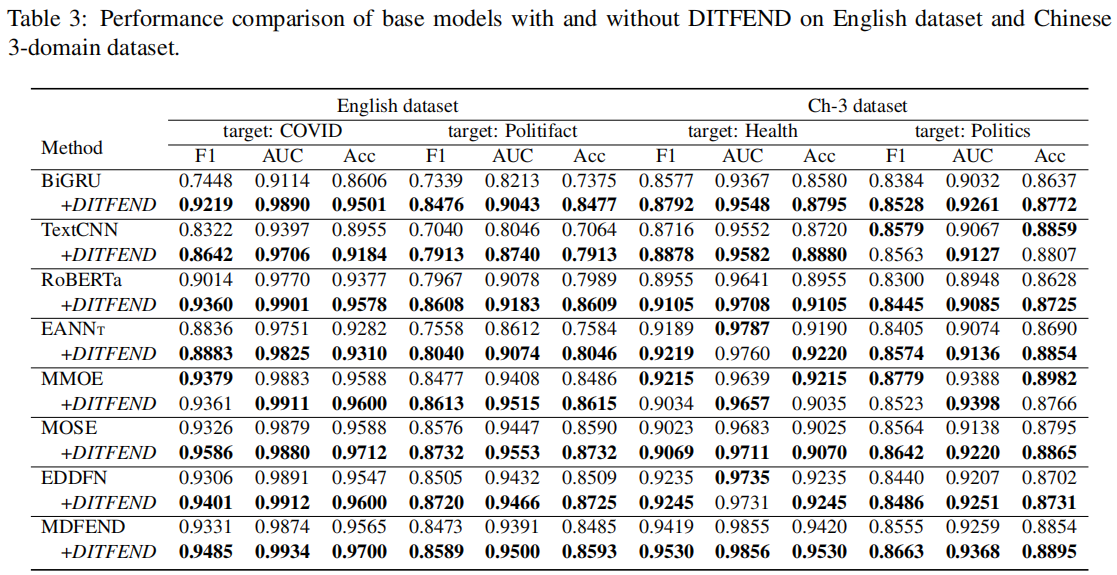
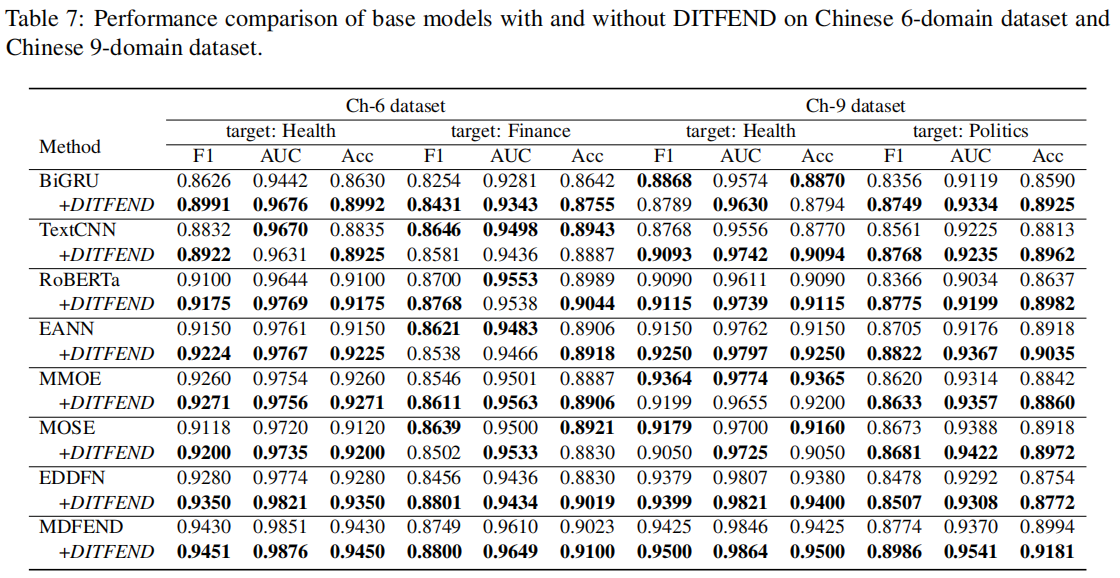
为了分别分析在DITFEND中元学习方式和源领域数据所起到的作用,我们进行了消融实验——w/o meta即用普通的训练方式代替元学习的训练方式, w/o sources 即仅仅使用目标领域数据进行目标领域自适应的模型训练。实验结果如下表所示:
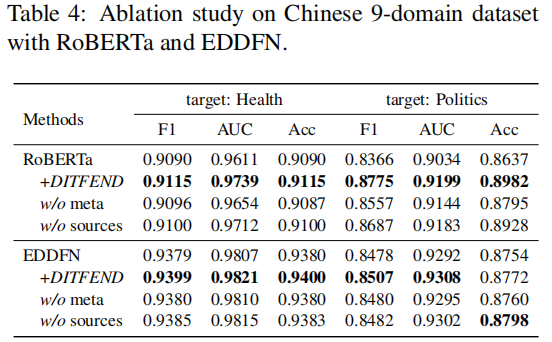
可以看到,元学习方式和源领域的数据对DITFEND提升基础模型表现性能均有不可或缺的作用。
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16968838.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号