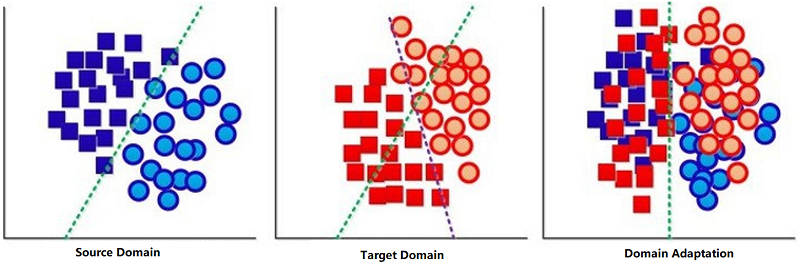
Formally, given a fully-labeled source domain dataset with Ns image and label pairs Ds=(Xs,ys)={(xis,yis)}Nsi=1 , and an unlabeled dataset in a target domain with Nt images Dt=Xt={xit}Nti=1 , both {xis} and {xit} belong to the same set of M predefined categories. We use yis∈{0,1,…,M−1} to represent the label of the i-th source sample while the labels of target samples are unknown during training. UDA aims to predict labels of testing samples in the target domain using a model ft:Xt→Yt trained on Ds∪Dt . The model, parameterized by θ consists of a feature encoder g:Xt→Rd and a classifier h:Rd→RM , where d is the dimension of features produced by the encoder.
许多标准的 UDA 设置,假设在源域和目标域上共享相同的特征编码器,然而由于特征编码器不能同时在源域和目标域上训练,所以 Source Data-free UDA 无法实现。本文的 CDCL 在缺少源域数据的情况下面临的挑战是 :(1) form positive and negative pairs and (2) to compute source class prototypes。
本文通过用训练模型 fs 的分类器权值替换源样本来解决这个问题。直觉是,预先训练模型的分类器层的权向量可以看作是在源域上学习到的每个类的原型特征。特别地,我们首先消除了全连通层的 bias ,并对分类器进行了归一化处理。假设 wms∈Ws=[w1s,…,wMs] 代表从源域学到的 M 分类器的权重向量,由于权值是规范化的,所以我们将它们用作类原型。当适应目标域时,冻结分类器层的参数,以保持源原型,并且只训练特征编码器。通过用源原型替换源样本,在源数据自由设置下的跨域对比损失可以写为:




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 【杂谈】分布式事务——高大上的无用知识?