谣言检测(SRD-PSCD)《Rumor Detection with Self-supervised Learning on Texts and Social Graph》
论文信息
论文标题:Rumor Detection with Self-supervised Learning on Texts and Social Graph
论文作者:Yuan Gao, Xiang Wang, Xiangnan He, Huamin Feng, Yongdong Zhang
论文来源:2202,arXiv
论文地址:download
论文代码:download
1 Introduction
出发点:考虑异构信息;
本文的贡献描述:看看就行...............................
2 Methodology
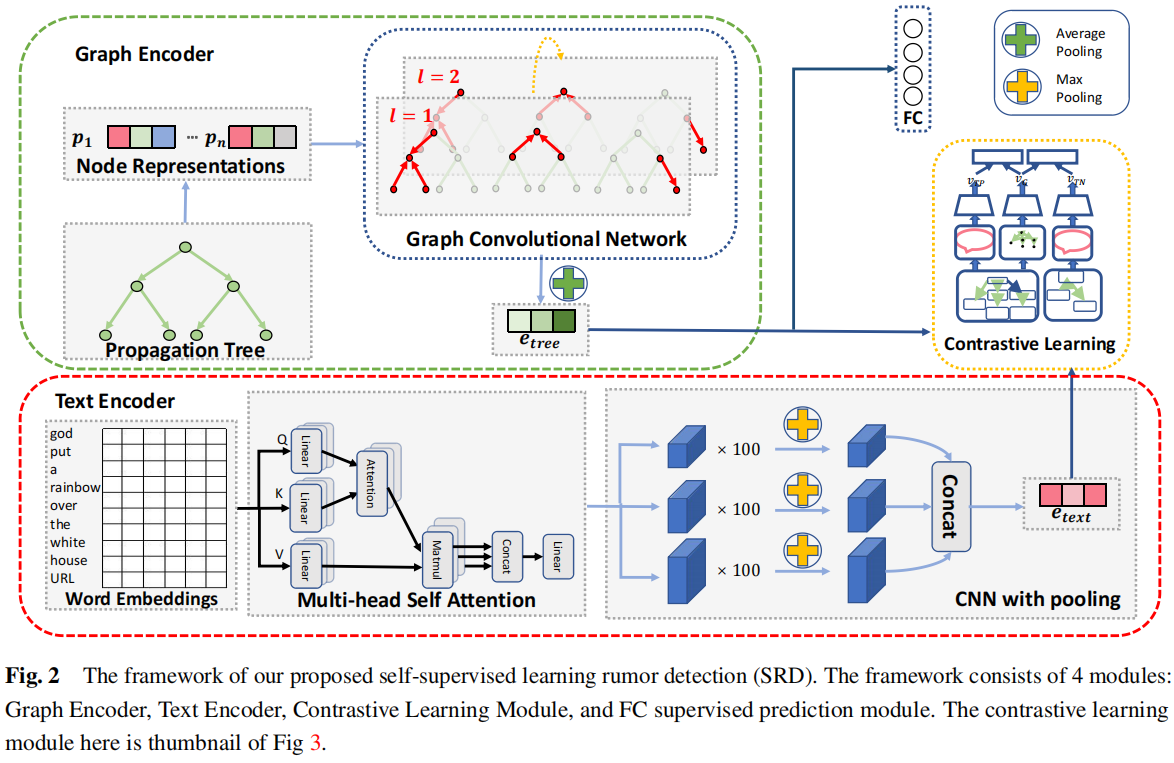
模块:
(1) propagation representation learning, which applies a GNN model on the propagation tree;
(2) semantic representation learning, which employs a text CNN model on the post contents;
(3) contrastive learning, which models the co-occurring relations among propagation and semantic representations;
(4) rumor prediction, which builds a predictor model upon the event representations.
2.1 Propagation Representation Learning
考虑结构特征
对于帖子特征编码:
$\mathbf{H}^{(l)}=\sigma\left(\mathbf{D}^{-\frac{1}{2}} \hat{\mathbf{A}} \mathbf{D}^{-\frac{1}{2}} \mathbf{H}^{(l-1)} \mathbf{W}^{(l)}\right)\quad\quad\quad(2)$
帖子图级表示:
$\mathbf{g}=f_{\text {mean-pooling }}\left(\mathbf{H}^{(L)}\right)\quad\quad\quad(3)$
2.2 Semantic Representation Learning
首先:在帖子特征上使用多头注意力机制得到初始词嵌入 $\mathbf{Z} \in \mathbb{R}^{l \times d_{\text {model }}}$ ($l$ 代表着帖子数,$d_{\text {model }}$ 代表帖子的维度):
$\boldsymbol{Z}_{i}=f_{\text {attention }}\left(\boldsymbol{Q}_{i}, \boldsymbol{K}_{i}, \boldsymbol{V}_{i}\right)=f_{\text {softmax }}\left(\frac{\boldsymbol{Q}_{i} \boldsymbol{K}_{i}^{T}}{\sqrt{d_{k}}}\right) \boldsymbol{V}_{i}\quad\quad\quad(4)$
$\boldsymbol{Z}=f_{\text {multi-head }}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=f_{\text {concatenate }}\left(\boldsymbol{Z}_{1}, \ldots, \boldsymbol{Z}_{h}\right) \boldsymbol{W}^{O}\quad\quad\quad(5)$
接着:使用 CNN 进一步提取文本信息
考虑感受野大小为 $h$ ,得到 feature vector $\boldsymbol{v}_{i}$
$\boldsymbol{v}_{i}=\sigma\left(\boldsymbol{w} \cdot \boldsymbol{z}_{i: i+h-1}+\boldsymbol{b}\right)\quad\quad\quad(6)$
在 sentence 中遍历,得到词向量集合:
$\boldsymbol{v}=\left[\boldsymbol{v}_{1}, \boldsymbol{v}_{2}, \ldots, \boldsymbol{v}_{n-h+1}\right]$
在词向量集合 $\boldsymbol{v}$ 采用 max-pooling 得到全局表示 $\hat{\boldsymbol{v}}\quad\quad\quad(7)$:
$\hat{\boldsymbol{v}}=f_{\text {max-pooling }}(\boldsymbol{v})\quad\quad\quad(8)$
考虑使用 $n$ 个 feature map ,并拼接表示得到文本表示 $\mathbf{t}$:
$\mathbf{t}=f_{\text {concatenate }}\left(\hat{\boldsymbol{v}}_{1}, \hat{\boldsymbol{v}}_{2}, \ldots, \hat{\boldsymbol{v}}_{n}\right)\quad\quad\quad(4)$
2.3 Contrastive Learning
本文认为同一帖子的基于结构的表示 $\boldsymbol{g}_{i}$ 和基于语义 $\boldsymbol{t}_{i}$ 的表示是正对:
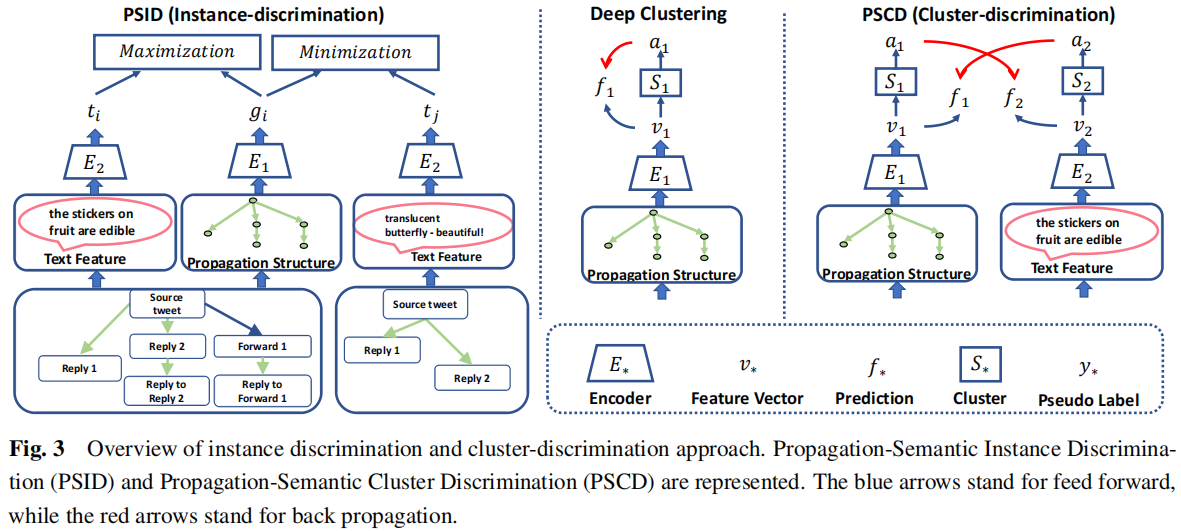
2.3.1 Propagation-Semantic Instance Discrimination (PSID)
${\large \mathcal{L}_{\mathrm{ssl}}=\sum\limits_{i \in C}-\log \left[\frac{\exp \left(s\left(\boldsymbol{g}_{i}, \boldsymbol{t}_{i}\right) / \tau\right)}{\sum\limits _{j \in C} \exp \left(s\left(\boldsymbol{g}_{i}, \boldsymbol{t}_{j}\right) / \tau\right)}\right]} \quad\quad\quad(10)$
2.3.2 Propagation-Semantic Cluster Discrimination (PSCD)
聚类级对比学习:
$\begin{array}{l}\underset{\mathbf{S}_{G}}{\text{min}}\quad \sum\limits _{c \in C} \underset{\mathbf{a}_{1}}{\text{min}} \left\|E_{1}(\mathbf{g})-\mathbf{S}_{G} \mathbf{a}_{1}\right\|_{2}^{2}+\underset{\mathbf{S}_{T}}{\text{min}} \sum\limits _{c \in C} \underset{\mathbf{a}_{2}}{\text{min}} \left\|E_{2}(\mathbf{t})-\mathbf{S}_{T} \mathbf{a}_{2}\right\|_{2}^{2}\\\text { s.t. } \quad \mathbf{a}_{1}^{\top} \mathbf{1}=1, \quad \mathbf{a}_{2}^{\top} \mathbf{1}=1\end{array}\quad\quad\quad(11)$
-
- $\mathbf{S}_{G}\in \mathbb{R}^{d \times K}$ 和 $\mathbf{S}_{T} \in \mathbb{R}^{d \times K}$ 分别代表了 基于结构信息和基于语义信息的可训练质心矩阵;
- $\mathbf{a}_{1}\in\{0,1\}^{K}$ 和 $\mathbf{a}_{2} \in\{0,1\}^{K}$ 代表了聚类分配;
- $E_{1}$ 和 $E_{2}$ 代表了编码器;
$\mathcal{L}_{\mathrm{ssl}}=\sum\limits _{c \in C} l\left(f_{1}\left(E_{1}(\mathbf{g})\right), \mathbf{a}_{2}\right)+l\left(f_{2}\left(E_{2}(\mathbf{t})\right), \mathbf{a}_{1}\right) \quad\quad\quad(12)$
其中,$l(\cdot)$ 是 negative log-softmax function $l(\cdot) = -\operatorname{LogSoftmax}\left(x_{i}\right)=\log \left(\frac{\exp \left(x_{i}\right)}{\sum\limits _{j} \exp \left(x_{j}\right)}\right)$,$f_{1}(\cdot)$ 、$f_{2}(\cdot)$是一个可训练的分类器。
PSCD 和 PSID 的处理过程如 Figure 3 :
2.4 Rumor Prediction
$p(c)=\sigma(\mathbf{W} \mathbf{g}+\mathbf{b})\quad\quad\quad(13)$

3 Experiments and Analyses
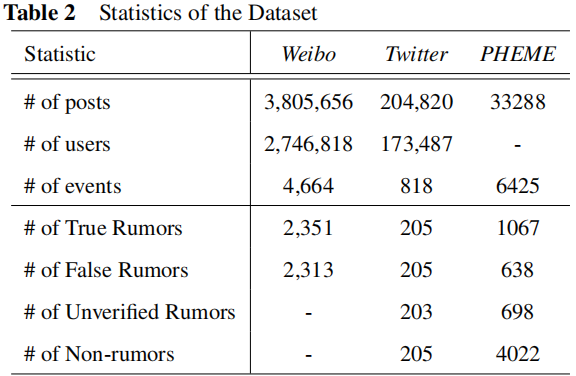
3.1 Dataset
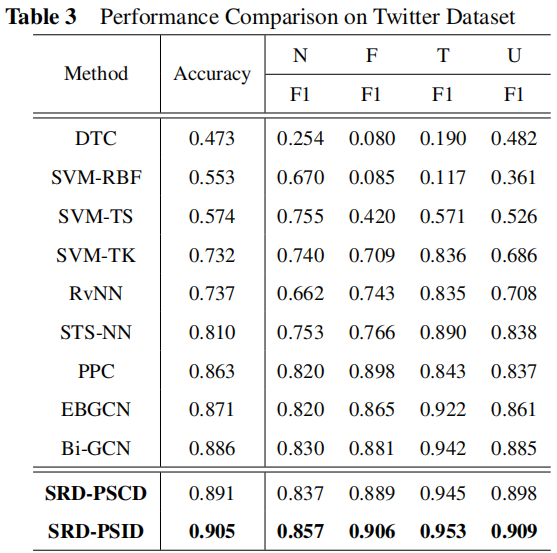
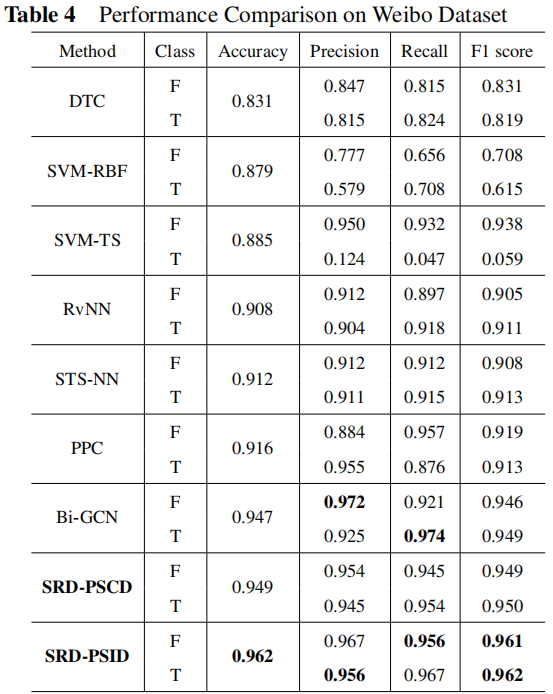
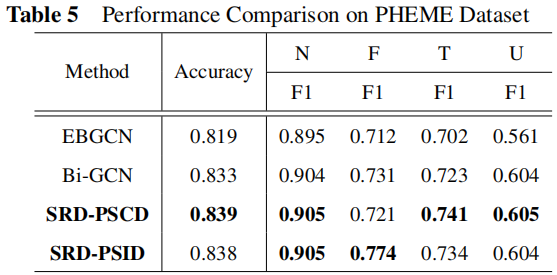
3.2 Result
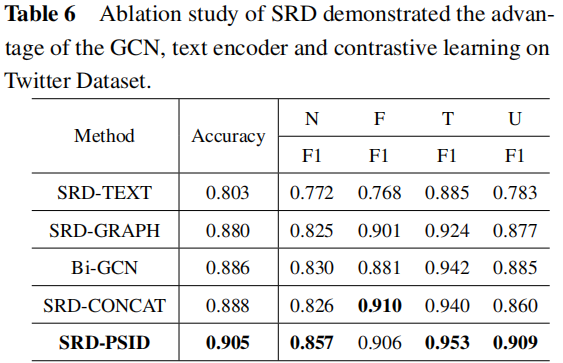
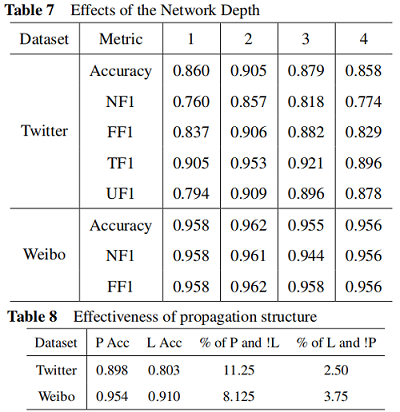
3.3 Ablation Analysis
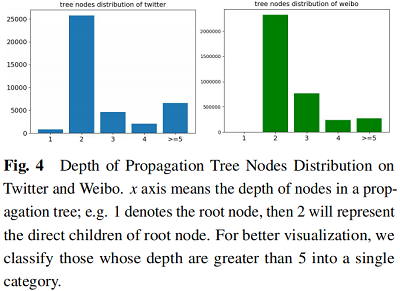
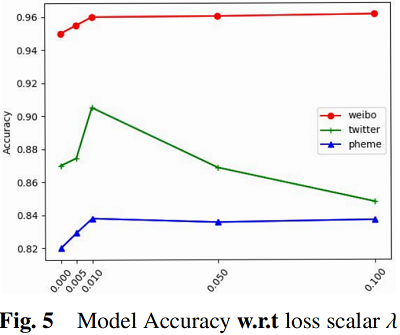
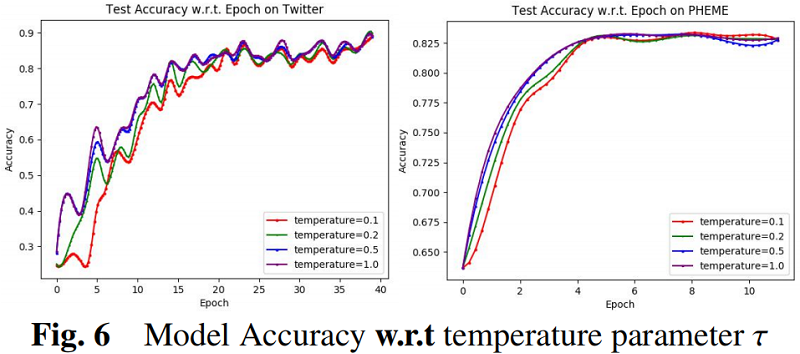
因上求缘,果上努力~~~~ 作者:图神经网络,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16860457.html

