论文解读(FedPCL)《Federated Learning from Pre-Trained Models: A Contrastive Learning Approach》
论文信息
论文标题:Federated Learning from Pre-Trained Models: A Contrastive Learning Approach
论文作者:Yue Tan, Guodong Long, Jie Ma, Lu Liu, Tianyi Zhou, Jing Jiang
论文来源:2022,ICML
论文地址:download
论文代码:download
1 Introduction
联邦学习 Federated Learning (FL) + 原型对比学习 Prototype Contrastive Learning。
解决问题:通过使用原型对比学习,解决朴素版本联邦学习存在的数据之间异质性问题。
2 Problem Formulation
组成:$1$ 个服务器(server), $m$ 个客户端(client)。
拥有 $m$ 个客户端的 $\text{global objective}$ 是:
$\underset{\left(w_{1}, w_{2}, \cdots, w_{m}\right)}{\text{min}} \frac{1}{m} \sum_{i=1}^{m} \frac{\left|D_{i}\right|}{N} L_{i}\left(w_{i} ; D_{i}\right) \quad\quad\quad(1)$
其中,$L_{i}$ 和 $w_{i}$ 分别为客户端 $i$ 的局部损失函数和模型参数,$D_{i}$ 是第 $i$ 个客户端的私有数据集,$N$ 是所有客户端中的样本总数。
朴素版本的联邦学习,如 FedAvg :将服务器和所有客户端的模型参数设置为一样 $w=w_{1}=w_{2}=\cdots=w_{m}$ (同步更新)。然而由于数据的异构性,参数同步有时会降低本地数据集的性能。[6,60] 等个性化联邦学习(personalized Federated Learning) 通过对客户端应用各种约束和正则化项解决这个问题,这允许客户端保留不同的模型参数 $w_{i}, i \in[1, m]$,以在本地数据集上获得更高的性能。
Lightweight FL Framework 拥有 $m$ 个客户端和一个中心服务器。每个客户端 $i \in[1, m]$ 都拥有 $K$ 个共享和固定的预训练 backbone,以及一个不能彼此共享的私有数据集 $D_{i}$。每个可学习的模型可以由两部分组成:
(1) Feature Encoder:$r\left(\cdot ; \Phi^{*}\right): \mathbb{R}^{d} \rightarrow \mathbb{R}^{K \times d_{e}}$,包含 $K$ 个预训练的的 backbone,每个 backbone 将 $d$ 维的原始样本 $\mathbf{x}$ 变成 $d_{e}$ 维,最终将 $K$ 个backbone 的表示拼接得到 $r_{\mathbf{x}}$ 。
(2) Projection Network :将 $h\left(\cdot ; \theta_{i}\right): \mathbb{R}^{K \times d_{e}} \rightarrow \mathbb{R}^{d_{h}}$ , 将 $r_{\mathbf{x}}$ 进行映射,以进行进一步的表示学习。
正式的定义如下:
$r\left(\mathbf{x} ; \Phi^{*}\right):=\operatorname{concat}\left(r_{1}\left(\mathbf{x} ; \phi_{1}^{*}\right), \ldots, r_{K}\left(\mathbf{x} ; \phi_{K}^{*}\right)\right) \quad\quad\quad(2)$
$z(\mathbf{x})=h\left(r_{\mathbf{x}} ; \theta_{i}\right)\quad\quad\quad(3)$
Global objective 如下:
$\begin{array}{l}\underset{\theta_{1}, \theta_{2}, \ldots, \theta_{m}}{\text{min}}\quad\sum\limits _{i=1}^{m} \frac{\left|D_{i}\right|}{N} \mathbb{E}_{(\mathbf{x}, y) \in D_{i}}\left[L_{i}\left(\theta_{i} ; z(\mathbf{x}), y\right)\right]\\\text{s.t.} \quad z(\mathbf{x})=h\left(r\left(\mathbf{x} ; \Phi^{*}\right) ; \theta_{i}\right) \quad\text{where}\quad \Phi^{*}=\left\{\phi_{1}^{*}, \phi_{2}^{*}, \cdots, \phi_{K}^{*}\right\}\end{array}\quad\quad\quad(4)$
3 Federated Prototype-wise Contrastive Learning (FedPCL)
整体框架如下:
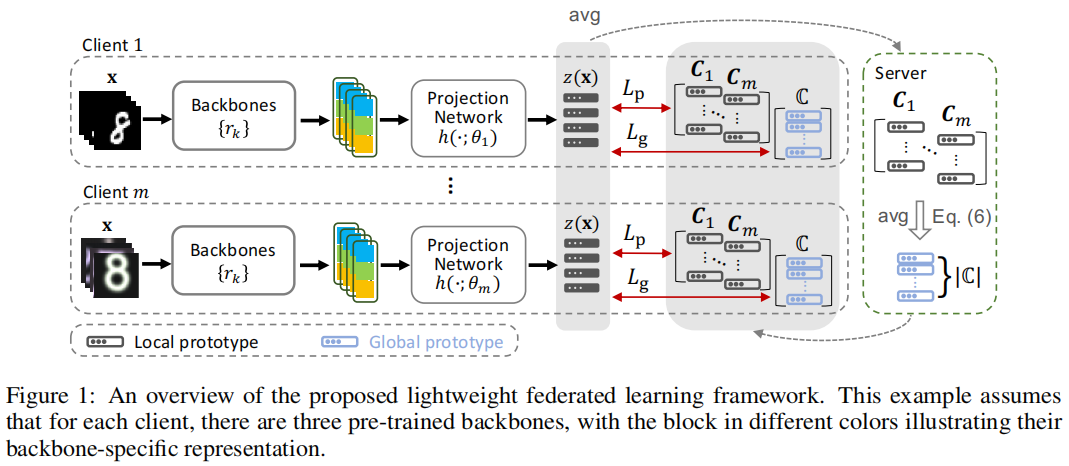
为捕获类相关的语义信息,本文建议在客户端和服务器之间传输类原型信息,传输类原型的优点:
首先,原型的形式更紧凑,大大降低了训练过程中所需的通信成本。
其次,非参数通信允许每个客户端学习一个更多定制的本地模型,而无需与其他客户端同步参数。第三,原型是高级的统计信息,而不是原始的特性,它不会给系统产生额外的隐私问题,并且对基于梯度的攻击[66,67]具有鲁棒性。
本地类相关特征(class-relevant information),为同一类 $j$ 内的融合表示的平均值组成:
${\large C_{i}^{(j)}:=\frac{1}{\left|D_{i, j}\right|} \sum\limits _{(\mathbf{x}, y) \in D_{i, j}} z(\mathbf{x})} \quad\quad\quad(5)$
其中,$D_{i, j}$ 表示由属于类 $j$ 的所有实例组成的 $D_{i}$ 的子集,$\boldsymbol{C}_{i}$ 表示第 $i$ 个客户端的局部原型集。经上述计算,将每个客户端的本地原型集发送到中央服务器进行知识聚合,中央服务器共享基于其本地数据集在每个特定客户端上提取的本地类相关信息。
${\large \bar{C}^{(j)}:=\frac{1}{\left|\mathcal{N}_{j}\right|} \sum\limits _{i \in \mathcal{N}_{j}} \frac{\left|D_{i, j}\right|}{N_{j}} C_{i}^{(j)}} \quad\quad\quad(6)$
其中,$\mathcal{N}_{j}$ 表示拥有类 $j$ 实例的客户端集,$N_{j}$ 表示在所有客户端上属于类 $j$ 的实例数。全局原型集表示为 $\mathbb{C}= \left\{\bar{C}^{(1)}, \bar{C}^{(2)}, \ldots\right\}$。通过这种聚合机制,全局原型集总结了所有客户端共享的粗粒度的类相关知识,这为表示学习提供了一个高级的视角
聚合之后,服务器将全局原型集和从所有客户端收集到的完整本地原型集发送回每个客户端。对于在某些非 IID 情况下,每个客户端中只有几个类的情况,我们在服务器中引入了一个原型填充过程,以确保每个本地原型集包含对应于所有类的原型:
基于原型的通信和聚合允许每个客户端拥有一个独特的投影网络,该网络能够以定制的方式融合一般表示。返回的本地原型集可以鼓励从客户相关的角度相互学习,而全局原型集,其中每个元素表示总体数据中的一个类中心,提供了一个从高度总结的与客户无关的角度学习的机会。
在从 server 接收到原型集后,局部训练的主要目标是分别有效地从局部原型和全局原型中提取有用的知识,从而最大限度地有利于局部表示学习。为了实现这一点,我们提出了一个原型式的监督对比损失,它包括两个项,即全局项和局部项。
为了迫使局部投影网络生成的融合表示 $z (x)$ 更接近其对应的全局类中心,从而提取更多与类相关但与客户端无关的信息,我们将基于全局原型的全局损失项定义为
除了全局项之外,为了通过潜在空间中的交替客户对比学习将 $z(\mathbf{x}) $ 与每个客户的本地原型对齐,并实现更多的客户间知识共享,我们将基于局部原型的损失项定义为
对于第 $i$ 个 client,目标函数,形式如下:

4 Experiments
4.1 Datasets
包括 3 个 benchmark datasets :
-
- Digit-5—— SVHN, USPS, SynthDigits, MNIST-M, MNIST
- Office-10—— Amazon, Caltech, DSLR, WebCam
- DomainNet—— Clipart, Info, Painting, Quickdraw, Real, Sketch
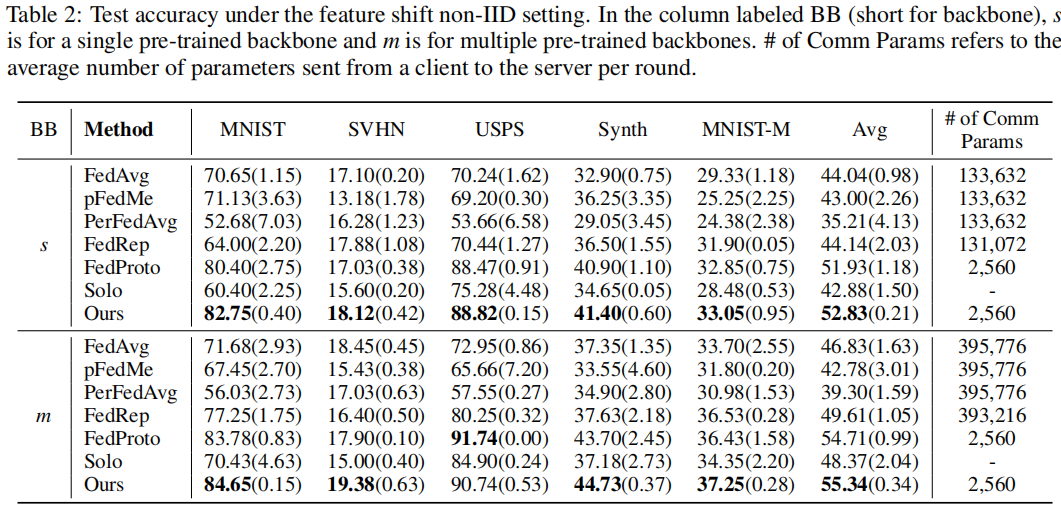
4.2 Result
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16807674.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号