论文信息
论文标题:Rumor Detection on Twitter with Claim-Guided Hierarchical Graph Attention Networks
论文作者:Erxue Min, Yu Rong, Yatao Bian, Tingyang Xu, Peilin Zhao, Junzhou Huang,Sophia Ananiadou
论文来源:2021,EMNLP
论文地址:download
论文代码:download
Background
传播结构为谣言的真假提供了有用的线索,但是现有的谣言检测方法要么局限于用户相应关系,要么简化了对话结构。
本文说的 Claim 代表的是 Source post ,即源帖。
1 Introduction
如下为一个简单的 conversation thread 例子:

本文提出的点:考虑兄弟之间的关系,如下图虚线部分。
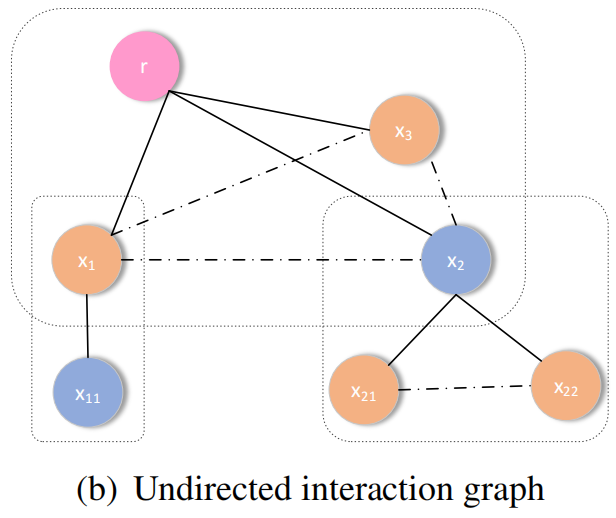
2 Claim-guided Hierarchical Graph Attention Networks
总体框架如下:
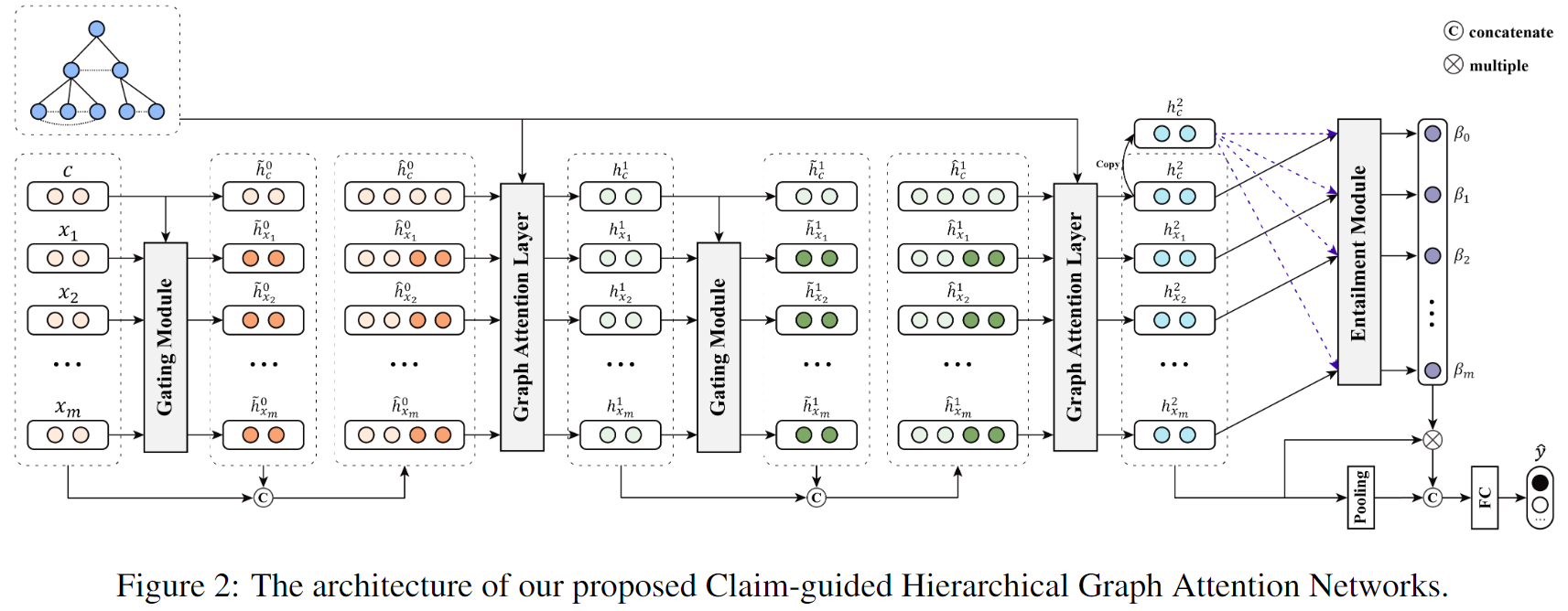
本文的模型包括两个注意力模块:
- A Graph Attention to capture the importance of different neighboring tweets
- A claim-guided hierarchical attention to enhance post content understanding
2.1 Claim-guided Hierarchical Attention
对于每个 tweet ,首先使用 Bi-LSTM 获得 Post 的特征矩阵 ,其中 。
为加强模型的主题一致性和语义推理:
Post-level Attention
为了防止主题偏离和丢失 claim 的信息,本文采用 gate module 决定它应该接受 claim 多少信息,以更好地指导相关职位的重要性分配。claim-aware representation 具体如下:
其中, 是一个 gate vector, 和 是可学习参数。
然后,将 claim-aware representation 与 original representation 拼接起来,作为 的输入去计算注意力权重:
2.2 Graph Attention Networks
为了编码结构信息,本文使用 GAT encoder:
输入:
过程:
考虑多头注意力:
替换输出层的表示向量:
输出:图表示
Event-level Attention
出发点:获得图表示的时候采用的 平均池化并不是一定有意义的,可能存在某些节点对于图分类来说更准确。
受到 Natural Language Inference (NLI) 的影响,本文考虑对 GAT 最后一层的 和 做如下处理 :
1)concatenation
2)element-wise product
3)absolute element-wise difference
接着获得一个联合表示:
通过使用该联合表示计算 Event-level Attention :
最后将其 与 GAT 最后一层的平均池化图表示 拼接作为最终图表示,并进行分类:
3 Experiments
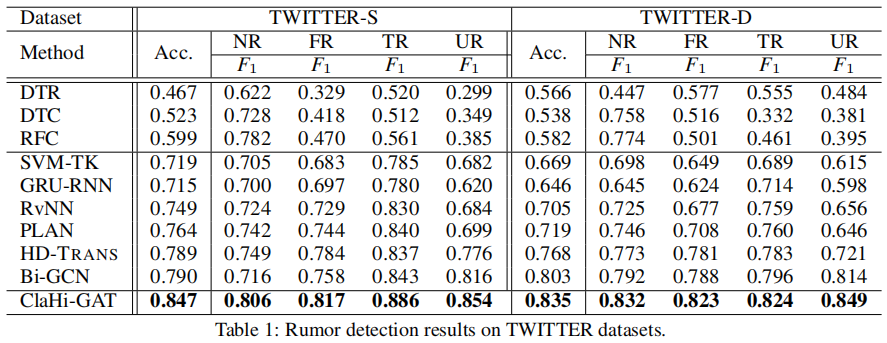
3.2 Rumor Classifification Performance
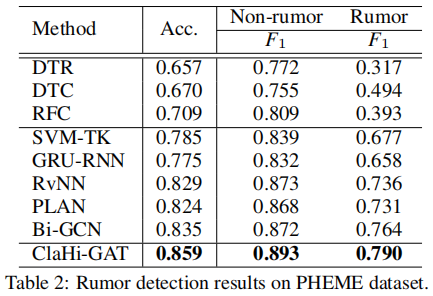
3.3 Ablation Study
1) ClaHi-GAT/DT: Instead of the undirected interaction graph, we use the directed trees as the model input.
2) GAT+EA+SC: We simply concatenate the features of the claim with the node features at each GAT layer, to replace the claim-aware representation.
3) w/o EA: We discard the event-level (inference-based) attention as presented.
4) w/o PA: We neglect the post-level (claim-aware) attention by leaving out the gating module introduced.
5) GAT: The backbone model.
6) GCN: The vanilla graph convolutional networks with no attention.
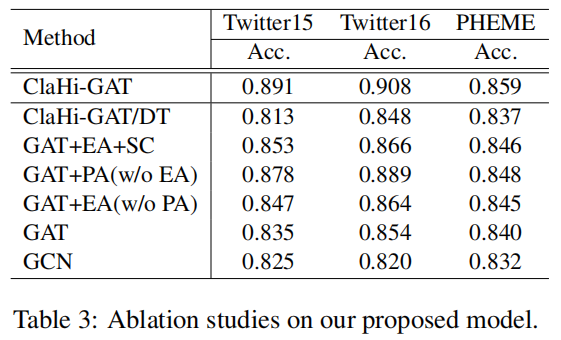
3.4 Evaluation of Undirected Interaction Graphs
- ClaHi-GAT/DT Utilize the directional tree applied in past influential works as the modeling way instead of our proposed undirected interaction graph.
- ClaHi-GAT/DTS Based on the directional tree structure similar to ClaHi-GAT/DT but the explicit interactions between sibling nodes are taken into account.
- ClaHi-GAT/UD The modeling way is our undirected interaction topology but without considering the explicit correlations between sibling nodes that reply to the same target.
- ClaHi-GAT In this paper, we propose to model the conversation thread as an undirected interaction graph for our claim-guided hierarchical graph attention networks.
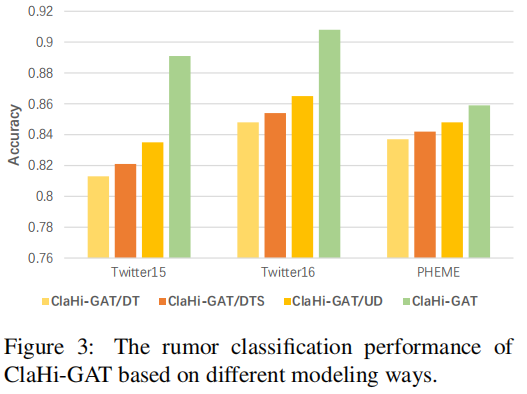
3.5 Early Rumor Detection
关键点:随着 claim 的传播,或多或少会产生更多的语义信息和噪声,所以使用 claim 的信息至关重要。
举例说明:false claim 的注意力分数得分图如下:

言下之意:错误的 post 会被赋予较小的权重,这就是为什么该模型早期谣言检测比较稳定的原因。
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16772120.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2021-10-09 机器学习第一次作业