论文信息
论文标题:Jointly embedding the local and global relations of heterogeneous graph for rumor detection
论文作者:Chunyuan Yuan, Qianwen Ma, Wei Zhou, Jizhong Han, Songlin Hu
论文来源:2019,IJCAI
论文地址:download
论文代码:download
Abstract
在本文中,我们提出了一种新的全局-局部注意网络(GLAN),它联合编码局部语义和全局结构信息。我们首先,通过将相关转发的语义信息与注意机制相融合,为每个源推文生成一个更好的集成表示。然后,我们将所有源推文、转发和用户之间的全局关系建模为一个异构图,以捕获丰富的结构信息,用于谣言检测。我们在三个真实世界的数据集上进行了实验,结果表明,GLAN在谣言检测和早期检测场景中都显著优于最先进的模型。
I Introduction
在谣言检测任务中,以往的研究大多认为每个源微博都是独立的,且不相互影响,因此它们没有充分利用不同类型节点之间的相关性。为了说明本文的动机,提供一个全局异构图,它包含三个具有对应用户响应的源推文,如 Figure 1 所示:
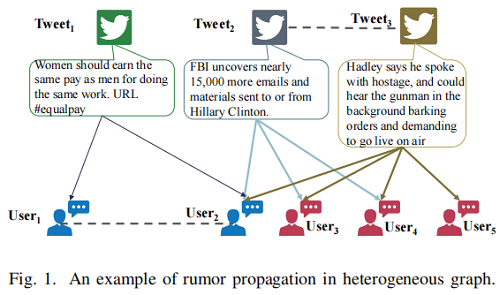
在这个例子中,两个用户 和 没有关系,他们彼此也不一致,但他们都转发了同一条推文 。此外,这三条推文在内容上无关,但是 和 共享相似的邻居,这表明它们很可能会有相同的标签。基于这些观察结果,我们构建了一个全局异构图来捕获所有源推文、转发和用户之间的局部和全局关系。具体来说,如果用户节点参与(发推文和转发推文)相同的微博(如-)(推文或转发),连接它们。如果源推文有相同的 ,那么对源推文之间加一个连接(-)。这样,我们就可以学习图中不同类型节点的潜在表示。微博和他们的相关用户往往会有密切的潜在代表,所以用户也会发布类似的推文或分享类似的参与者的推文,即使他们没有在网络中直接连接。
本文做的工作:
(1)如何从转发的推文中整合复杂的语义信息;
(2)如何对所有微博和参与者的异构图结构进行全局建模,以进行谣言检测;
为解决上述两个问题,本文提出了一种具有局部和全局注意力的谣言检测方法。本文首先聚焦于如何计算源推文和转发的推文之间的局部注意力相融合,然后为每个源推文构建一个新的表示。其次,本文构建了一个全局异质图,通过将不同源推文的结构和语义属性相结合,而不是使用单一的微博谣言。
2 Related work
谣言检测的相关内容可以分为如下几类:
(1) Feature-based Classification Methods;
(2) Deep Learning Methods;
(3) Propagation Tree Related Methods;
A. Feature-based Classification Methods
早期的工作主要基于手工特征做的谣言检测。这些谣言检测方法主要从 text content 和 users’ profile information 提取有用的信息。
[1] 探索了 Twitter 上诸如 text-based, user-based, topic-based, propagation-based features 的特征信息。
[12] 探索了基于谣言生命周期的时间序列,探讨了这些特征的时间特征,并纳入了各种社会背景信息。
[13] 探索了一种基于谣言传播的时间、结构和语言特性来识别谣言的新方法。
[4] 在新浪微博上引入了新的功能(如所使用的微博客户端程序和事件位置信息)来识别谣言。
B. Deep Learning Methods
[10] 提出了一种基于递归神经网络(RNN)的模型来学习相关文章的文本表示。
[14] 提出了一种基于卷积神经网络(CNN)的卷积误信息识别方法,该方法可以捕获重要特征之间的高级交互作用。
[15], [16] 探索利用深度神经网络来融合各种特征。例如,在这些研究中,我们探讨了微博文本、用户的分析数据。
[8] 将传播路径建模为多元时间序列,并应用循环网络和卷积网络来捕获用户特征沿传播路径的变化。
但是,这些方法要么忽略了传播模式,要么将传播路径建模为一个序列结构,从而不能充分利用微博的传播信息。
C. Propagation Tree Related Methods
[5] 利用流行病学模型来描述推特上由真实新闻和假新闻产生的信息级联。
[17] 提出了一种随机游走图核来对消息传播树建模,以提高谣言检测。
[6] 利用一个关于一个新闻报道的对话片段之间的隐性联系来预测其真实性。
[7] 提出了一种基于核的利用传播树捕获微博帖子传播的高阶模式的方法,为微博随时间的传播和发展提供了有价值的线索。
在图中,用户传递或重新发布消息,使其传播快速和广泛。这些基于传播树的方法只探讨了信息传递结构的差异,而没有考虑不同传播树之间的关系。
3 Problem formulation
让 是源微博的集合,其中每个源微博 有 个转发 。对于每个微博,用符号 表示发布时间。在异构图中,将转发视为源微博的邻居节点,其表示为 。社交媒体用户表示为 。目标是学习一个函数 来预测源微博是否是谣言。 为类标签, 表示模型的所有参数。
4 The proposed model
本文的谣言检测模型包括四个部分:
-
- microblog representation;
- local relation encoding;
- global relation encoding;
- rumor detection with local and global relations;
Figure 2 显示了该模型的体系结构:
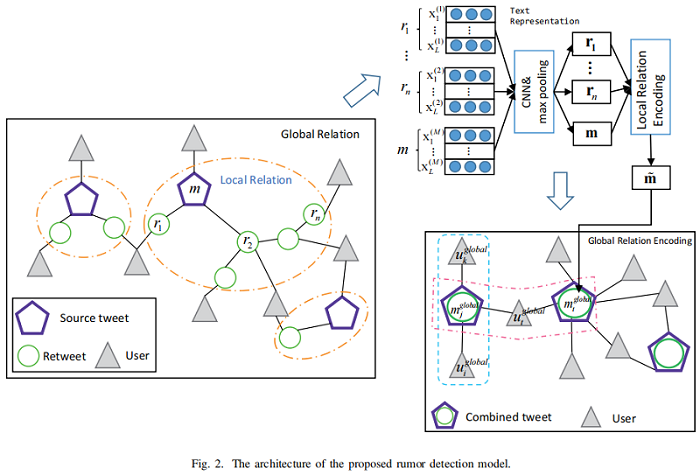
A. Microblog Representation
将 定义为微博 中第 个词对应的 维词嵌入。假设每个微博都有 个单词。当微博长度小于 时,在文档开始处填充 ,如果微博长度大于 ,则在结束位置截断微博。长度为 的句子表示为
其中, 是连接运算符。我们使用 来表示单词 。
学习文本语义表示的经典模型有 CNN [18], [19]、RNN [20], [21],本文采取 CNN 模型去学习微博的语义表示。
1) CNN:卷积层用于词向量矩阵 :
然后得到一个 feature map ,其中 , 代表卷积核的大小,最后使用最大池化算子在 feature map:。
从上述操作中,从一个滤波器中提取一个特征。CNN层使用 的滤波器(具有不同的感受野 )来获得多个特征。
然后,我们将各种滤波器的输出连接成 ,作为第 个微博 的表示。通过同样的方法,我们可以得到每个转发的文本表示 。转发表示被堆叠在一起,形成转发矩阵 。
我们通过卷积网络从单词嵌入中获得了微博表示。然后,我们将介绍如何对源推文和转发评论之间的本地关系进行编码。
B. Local Relation Encoding
不同以往采用递归神经网络的工作(难以并行、以及无法获得多粒度的语义信息),本文采用现在流行的注意力机制。
1) Multi-head Attention
Figure 3 显示了多头注意的结构:
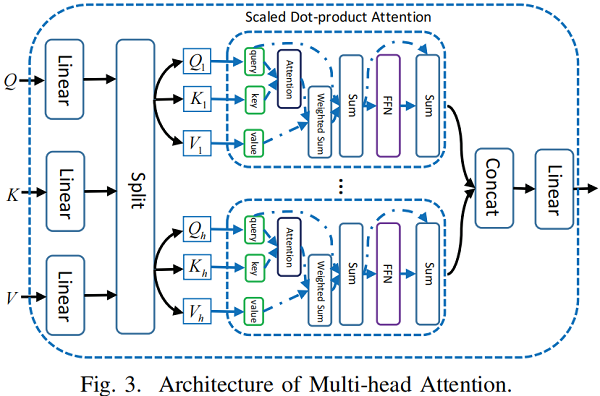
Multi-head Attention module 有三个输入句子:the query sentence、the key sentence 和 the value sentence,即 , , 。其中,、、 表示每个句子中的单词数, 为嵌入的维数。
本文使用的多头注意力: 头 的输出值由
其中 ,, 是线性变换
为了建立源微博与转发之间的内部连接,我们首先使用多头注意力对每个转发的表示进行细化,其表述为:
其中,。
Self-attention 让每一次转发都能相互关注,并通过其他类似的转发来代表每个转发。因此,该表示可以编码不同转发之间的语义关系。
然后,我们应用 cross attention 来建立源推文和转发之间的连接。具体来说,我们将源推文 视为键,并使用它来参加转发 ,以计算每次转发推文的注意力分数。
其中, 是一个注意力分数。该分数用于聚合转发,以形成一个新的文本表示。
为了确定原始微博表示和新微博表示之间的重要性,利用融合门(fusion gate)组合两种表示:
其中, 为 sigmoid 型激活函数, 和 为融合门的可学习参数。而 则是最终的微博表示形式。
我们构建了全局异构图,其中包含两种类型的节点:combined text node(源微博节点和转发节点)和 user node。首先,我们阐明了这两种类型的节点的组成:
考虑到用户节点 和文本节点 是不同语义空间(),我们将它们转换为相同的语义空间进行进一步处理,可以表述为
Figure 2 的右边有两种类型的关系:
(1) user-centric relation (such as );
(2) microblog-centric relation (such as );
本文使用的注意力机制为:
其中 是可学习的参数。
为了从不同的关系中捕获多个表征,我们将我们的注意机制扩展到采用多头形式,这类似于多头注意[23]。具体来说, 个独立的注意机制执行 的变换,然后将它们的特征连接起来,得到以下输出特征表示:
The global relation encoding algorithm:
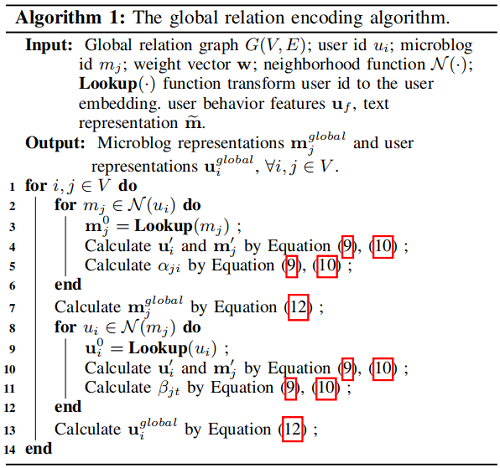
经过上述步骤,我们得到了局部表示 和全局表示 。这两种表示对于谣言检测都很重要,因此它们被连接为分类的最终特征。然后,应用全连接层将最终表示投影到类概率的目标空间:
其中为 是权重参数, 是偏差项。
最后,利用交叉熵损失作为谣言检测的优化目标函数:
其中 为谣言类的金概率, 表示模型的所有参数。
5 Experiments
A.Dataset
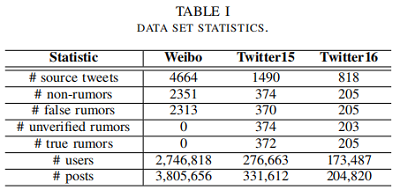
微博数据集包括二进制标签,即:“false rumor” 、“non-rumor”。Twitter15 和 Twitter16 的数据集分别包含四种不同的标签,即 “false rumor” (FR)、“non-rumor”(NR)、“unverified”(UR)和 “true rumor”(TR)。请注意,“true rumor”的标签是指一个微博,它告诉人们某个微博是假的。对于每个数据集,由 source tweets、responsive tweets 和 related users 构建一个异构图。Table I 显示了这三个数据集的统计数据。由于原始数据集不包含用户信息,所以我们通过 Twitter API 对其抓取了所有相关的用户档案。
B. Baseline Models
• DTC [1]: A decision tree-based model that utilizes a combination of news characteristics.
• SVM-RBF [4]: An SVM model with RBF kernel that utilize a combination of news characteristics.
• SVM-TS [12]: An SVM model that utilizes time-series to model the variation of news characteristics.
• DTR [29]: A decision-tree-based ranking method for detecting fake news through enquiry phrases.
• GRU [10]: A RNN-based model that learns temporal linguistic patterns from user comments.
• RFC [30]: A random forest classifier that utilizes user,linguistic and structure characteristics.
• PTK [7]: An SVM classifier with a propagation tree kernel that detects fake news by learning temporal-structure patterns from propagation trees.
• RvNN [22]: A bottom-up and a top-down tree-structured model based on recursive neural networks for rumor detection on Twitter.
• PPC [8]: A novel model that detects fake news through propagation path classification with a combination of recurrent and convolutional networks.
C. Data Preprocessing
与最初的论文 [10],[22] 相同,我们随机选择 10% 的实例作为开发数据集,并在所有三个数据集中以 3:1 的比例将其余的实例进行训练和测试集。
模型中所有的词嵌入都用 维的词向量进行初始化,并通过 Skip-gram [31] 算法在领域特定的审查语料库上进行训练。没有出现在预先训练过的单词向量集合中的单词是从均匀分布初始化的。我们在训练过程中保持单词向量的可训练性,并且可以对每个任务进行微调。
对于 Twitter15 和 Twitter16 的数据集,单词是用空白来分割的。对于微博数据集,单词由 Jieba 库进行分割。我们删除出现次数少于 次的单词,因为它们可能是停止单词。
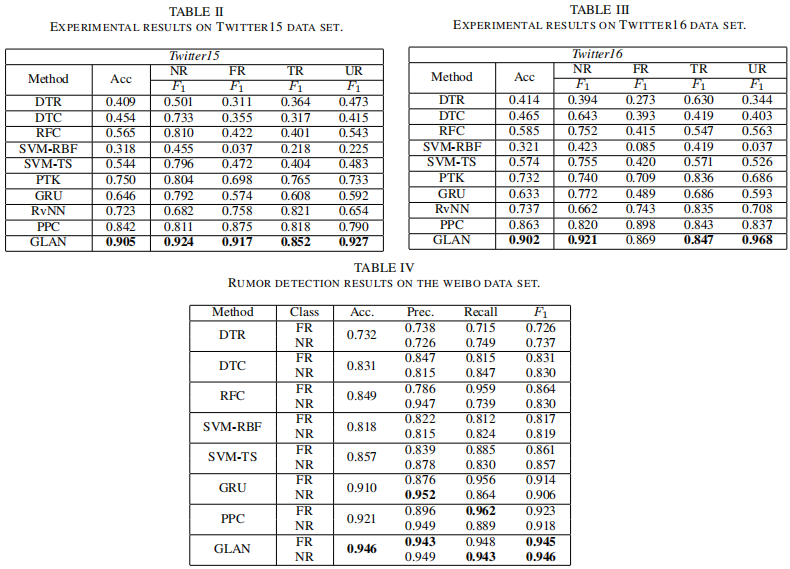
为了公平比较,我们采用了之前工作 [8],[22] 中使用的相同的评价指标。因此,采用 accuracy、precision、recall 和 F1 score 进行评价。
表 IV,、II 和 III 显示了所有比较方法的性能。为了进行公平的比较,基线模型的实验结果直接引用了之前的研究 [8],[22]。我们还将所有表中每一列的最佳结果加粗。从表 IV、表 II 和表 III 中,我们可以观察到 GLAN 在三个数据集上优于所有其他基线。
VI. Conclusion and future work
在本文中,我们提出了一个具有局部和全局关注的异构图,它结合了局部语义和全局结构信息的谣言检测。不同于大多数现有的提取手工制作的特征的研究,或者直接将转发序列进行网络,我们通过多头注意将源推文和本地上下文信息融合,为每个源推文生成更好的集成表示。为了从不同来源的推文中获取复杂的全局信息,我们利用具有全局关注的全局结构信息构建了一个异构图来检测谣言。在微博和推特数据集上进行的大量实验表明,所提出的模型在谣言分类和早期检测任务上都能显著优于其他最先进的模型。
在未来的工作中,我们计划将其他类型的信息,如用户配置文件和地理位置,集成到本地异构图中。此外,我们将探索更有效的方法来构建全局图,利用新的结构信息,进一步增强文本表示学习和早期检测谣言传播者。[24]–[26] 将异质图结构编码到一个连续的空间。
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16676800.html


· Blazor Hybrid适配到HarmonyOS系统
· Obsidian + DeepSeek:免费 AI 助力你的知识管理,让你的笔记飞起来!
· 解决跨域问题的这6种方案,真香!
· 一套基于 Material Design 规范实现的 Blazor 和 Razor 通用组件库
· 分享4款.NET开源、免费、实用的商城系统
2020-09-10 图论---最小生成树----普利姆(Prim)算法
2020-09-10 图论---最小生成树
2020-09-10 图的遍历BFS广度优先搜索