谣言检测——《MFAN: Multi-modal Feature-enhanced Attention Networks for Rumor Detection》
论文信息
论文标题:MFAN: Multi-modal Feature-enhanced Attention Networks for Rumor Detection
论文作者:Jiaqi Zheng, Xi Zhang, Sanchuan Guo, Quan Wang, Wenyu Zang, Yongdong Zhang
论文来源:2022,IJCAI
论文地址:download
论文代码:download
Abstract
本文提出的模型 MFAN 第一次将 文本、视觉和社图谱特征 融入同一个框架中。此外,还同时考虑了互补和不同模态之间的对齐关系来达到更好的融合。
1 Introduction
传统的谣言检测模型主要依赖与提取文本特征作为源帖表示,然后做分类。提出融合文本和视觉特征比单独使用文本效果更好工作:[Khattar et al., 2019;Wang et al., 2018; Zhou et al., 2020],上述工作的缺点在于没有考虑 graphical social contexts simultaneously,使用这种东西被证明有益的工作 [Yuan et al., 2019]。
- 节点表示学习的质量高度依赖于实体之间的可靠链接。由于隐私问题或数据爬行约束,可用的社交图谱数据很可能缺乏实体之间的一些重要的链接。因此,有必要补充社交图谱上的潜在链接,以实现更准确的检测;
- 图上相邻节点之间可能存在各种潜在关系,而传统的图神经网络(GNN)邻域聚合过程可能无法区分它们对目标节点表示的影响,导致性能较差;
- 如何有效地将学习到的社会图谱特征与其他模态特征(如视觉特征)整合起来,在现有的研究中探索较少。
具体地说,引入了自我监督损失来对齐从两种不同的视图中学习到的源后表示,即文本-视觉视图和社会图视图,旨在提高每个视图中的表示学习。一方面,我们提出了推断社交图中节点之间的潜在链接,以缓解不完全链接问题。另一方面,我们利用有符号注意机制来捕获正和负邻域相关性,以实现更好的节点表示。通过上述增强的跨模态融合和社交图表示学习,我们可以提高多媒体谣言检测的性能。
贡献:
- 提出了一种用于多媒体谣言检测的多模态特征增强注意网络,它可以有效地将文本、视觉和社会图的特征结合在一个单一的框架中。
- 引入了一种自监督损失来在不同的视图中对齐源后表示,以实现更好的多模态融合。
- 通过增强图的拓扑结构和邻域聚合过程来改进社会图的特征学习。
- 经验表明,该模型可以有效地识别谣言,并在两个大规模的真实数据集上优于最先进的基线。
2 Related Work
相关工作对比:
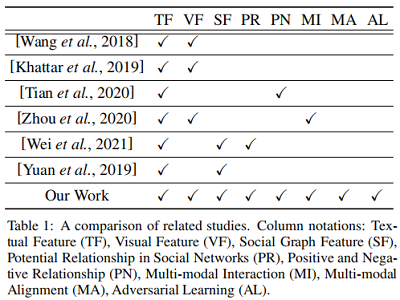
3 Problem Defnition
Let $P=\left\{p_{1}, p_{2}, \cdots, p_{n}\right\}$ be a set of multimedia posts on social media with both texts and images. For each post $p_{i} \in P$ , $p_{i}=\left\{t_{i}, v_{i}, u_{i}, c_{i}\right\}$ , where $t_{i}$, $v_{i}$ and $u_{i}$ denote the text, image and user who have published the post. $c_{i}=\left\{c_{i}^{1}, c_{i}^{2}, \cdots, c_{i}^{j}\right\}$ represents the set of comments of $p_{i}$ . Moreover, each comment $c_{i}^{j}$ is posted by a corresponding user $u_{i}^{j}$ .
In order to represent user behaviors on social media, we establish a graph $G=\{V, A, E\}$ , where $V$ is a set of nodes, including user nodes, comment nodes, and post nodes. $A \in\{0,1\}^{|V| *|V|}$ is an adjacency matrix between nodes to describe the relationships between nodes, including posting, commenting, and forwarding. $E$ is the set of edges.
We define rumor detection as a binary classification task. $y \in\{0,1\}$ denotes class labels, where $y=1$ indicates rumor, and $y=0$ otherwise. Our goal is to learn the function $F\left(p_{i}\right)=y$ to predict the label of a given post $p_{i}$ .
4 Methodology
我们建议的重点是有效地结合文本、视觉和社交图特征,以提高谣言检测。为此,我们首先提取了这三种类型的特征。为了产生更好的社会图特征,我们提出了基于GAT的图拓扑和聚合过程。然后,我们捕获跨模态交互和对齐,以实现更好的多模态融合。最后,我们连接了增强的多模态特征来进行分类。我们还应用对抗性训练来提高鲁棒性。整个体系结构如 Figure 1 所示。
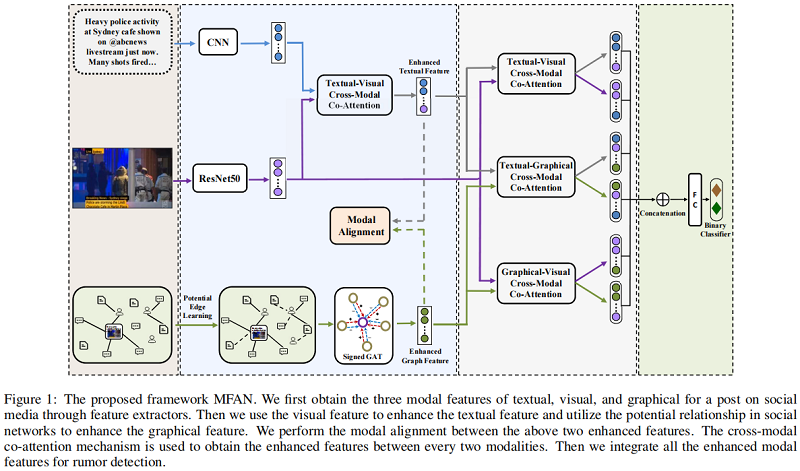
4.1 Textual and Visual Feature Extractor
Textual Representations
对于每个帖子 $p_{i}$,它的文本内容 $t_{i}$ 被填充或者截断为相同长度 $L$ 的 Token ,可以表示为:
$\mathcal{O}_{1: L}^{i}=\left\{o_{1}^{i}, o_{2}^{i}, \cdots, o_{L}^{i}\right\} \quad\quad\quad(1)$
其中,$o \in \mathbb{R}^{d}$ 是 $d$ 维的词嵌入,$o_{j}^{i}$ 表示 $t_{i}$ 的第 $j$ 个词的嵌入词。【One-hot】
对上述的 Token 即 词嵌入矩阵 $\mathcal{O}_{j: j+k-1}^{i}$,使用卷积 CNN 获得特征映射 $s_{i j}$,其中 $k$ 是感受野的大小,上述特征映射可以完整表达为:$s^{i}= \left\{s_{i 1}, s_{i 2}, \cdots, s_{i(L-k+1)}\right\}$,然后在完整的特征映射 $s^{i}$ 上使用最大池化获得 $\hat{s}^{i}=\max \left(s^{i}\right) $,这里使用不同的卷积核 $k \in\{3,4,5\}$ 来获得不同粒度的语义特征。最后,我们 concat 所有 flters 的输出,形成 $t_i$ 的整体文本特征向量:
$R_{t}^{i}=\operatorname{concat}\left(s_{k=3}^{i \hat{i}}, s_{k=4}^{\hat{i}}, s_{k=5}^{\hat{i}}\right) \quad\quad\quad(2)$
Visual Representations
使用预训练框架 $\operatorname{ResNet} 50$ 获得帖子中图像 $v_i$ 的特征嵌入 $V_{r}^{i}$,最后将其输入一个全连接层,即:
$R_{v}^{i}=\sigma\left(W_{v} * V_{r}^{i}\right) \quad\quad\quad(3)$
4.2 Enhanced Social Graph Feature Learning Inferring Hidden Links
为缓解缺失连接的问题,我们建议来推断社交网络中节点之间的隐藏链接。具体地说,我们将节点嵌入矩阵转换为 $X \in \mathbb{R}^{|V| \times d}$,其中 $d$ 是维数大小。$X$ 中有三种类型的节点,我们使用句子向量作为帖子和评论节点的初始嵌入,并使用用户发布的后节点嵌入的平均值作为初始用户嵌入。
为缓解缺失连接的问题,我们建议来推断社交网络中节点之间的隐藏链接。节点嵌入矩阵为 $X \in \mathbb{R}^{|V| \times d}$ ,
一个用户可以发布多个帖子
使用句子向量作为帖子和评论的初始嵌入 [ 帖子 包含多个 sentance ]
使用帖子嵌入的平均值作为作为初始的用户嵌入帖子 包含文本,使用文本 的嵌入作为帖子的初始嵌入
评论 包含文本,使用文本 的嵌入作为评论的初始嵌入
用户嵌入通过计算帖子嵌入的平均值获得
然后根据节点 $n_{i}$ 和 $n_{j}$ 的余弦相似度计算它们之间的相关性 $\beta_{i j}$
$\beta_{i j}=\frac{x_{i} \cdot x_{j}}{\left\|x_{i}\right\|\left\|x_{j}\right\|} \quad\quad\quad(4)$
其中,$x_{i}$ 和 $x_j$ 是 $n_i$ 和 $n_j$ 的节点嵌入。如果相似度大于 $0.5$,我们推断它们之间存在一个潜在的边,即:
$e_{i j}=\left\{\begin{array}{l}0, \text { if } \beta_{i j}<0.5 \\1, \text { otherwise }\end{array}\right. \quad\quad\quad(5)$
然后利用推断的势边增强原始邻接矩阵 $A \in \mathbb{R}^{|V| \times|V|}$。$a_{i j}$ 表示 $A$ 的元素,其中 $a_{i j}=1$ 表示 $n_{i}$ 和 $n_{j}$ 之间有一条边,否则则表示 $a_{i j}=0$。然后将增强邻接矩阵 $A^{\prime}$ 中的元素 $a_{i j}^{\prime}$ 定义为
$a_{i j}^{\prime}=\left\{\begin{array}{l}0, \text { if } e_{i j}=0 \text { and } a_{i j}=0 \\1, \text { otherwise }\end{array}\right. \quad\quad\quad(6)$
Capturing Multi-aspect Neighborhood Relations
通过GAT 计算节点之间的注意力系数:
$\mathcal{E}_{i}=\left\{e_{i 1}^{\prime}, e_{i 2}^{\prime}, \cdots, e_{i\left|\mathcal{N}_{i}\right|}^{\prime}\right\}$
其中节点$n_i$ 和 $n_j$ 之间的注意力:
$e_{i j}^{\prime}=\operatorname{LeakyRe} L U\left(\hat{a}\left[W x_{i} \| W x_{j}^{\prime}\right]\right)\quad\quad\quad(7)$
注意力机制存在的问题:未经过 softmax 的注意力系数可能出现很大的负权:
$\mathcal{E}_{t}=\{0.7,0.3,-0.1,-0.9\}$
注意力权重经过 softmax 的结果为:
$\mathcal{E}_{t}^{\prime}=\{0.43,0.29,0.20,0.09\}$
然而,“-0.9”可能表示这两个节点向量的处于相反位置。显然这种负相关的关系对于谣言检测很有帮助,如一个人说了与其行为不相关的评论。
受到 QSAN 的启发,本文使用了一种符号注意力机制 Signed GAT,具体地说,对于节点 $n_{i}$,我们将其相邻节点的注意权值 $\mathcal{E}_{i}$ 的反演表示为 $\tilde{\mathcal{E}}_{i}=-\mathcal{E}_{i}$。然后,我们用 softmax 函数计算 $\mathcal{E}_{i}$ 和 $\tilde{\mathcal{E}}_{i}$ 的归一化权值,
为了捕获节点之间的正关系和负关系,我们分别利用 $\mathcal{E}_{i}^{\prime}$ 和 $-\tilde{\mathcal{E}}_{i}^{\prime}$ 得到邻居节点特征的加权和。然后我们将这两个向量连接在一起,通过一个全连接层,得到最终的节点特征。例如,$n_{i}$ 的节点特征可以通过
$\hat{x}_{i}=\sigma\left(W_{n} *\left(\mathcal{E}_{i}^{\prime} * X_{j} \|-\tilde{\mathcal{E}}_{i}^{\prime} * X_{j}\right)\right)\quad\quad\quad(9)$
例子:
import numpy as np
import torch.nn.functional as F
import torch
if __name__ =="__main__":
data = torch.tensor([ 0.2 ,-1 , 1 ,-0.1 ])
out = F.softmax(data,dim=-1)
print("data = ",data.numpy())
print("softmax data = ",out.numpy())
data = torch.tensor([ 0.2 ,-1 , 1 ,-0.1 ])*-1
out = F.softmax(data,dim=-1)
print("-data = ", data.numpy())
print("softmax data = ",out.numpy())
输出:
data = [ 0.2 -1. 1. -0.1]
softmax data = [0.2343263 0.07057773 0.5215028 0.1735932 ]
-data = [-0.2 1. -1. 0.1]
softmax data = [0.16341725 0.5425644 0.0734281 0.22059022]
然后利用 Signed GAT 从增强的图中提取图的结构特征。对于每个节点,我们根据 $\text{Eq.9}$ 更新其嵌入,得到更新后的节点嵌入矩阵 $\hat{X} \in \mathbb{R}^{|V| \times d}$,其中 $|V |$ 为节点数,$d$ 为维数大小。然后采用多头注意机制,从不同的角度捕捉特征。我们将每个头部的更新后的节点嵌入连接在一起,作为整体的图特征:
$\hat{G}=\|_{h=1}^{H} \sigma\left(\hat{X}_{h}\right)\quad\quad\quad(10)$
其中,$H$ 为头的数量。然后,第 $i$ 个帖子的图特征 $R_{g}^{i}$ 对应于 $\hat{G}$ 的第 $i$ 个列。
4.3 Multi-modal Feature Fusing
在本工作中,由于有三种类型的数据,我们采用了具有共同注意方法的层次融合模式[Lu et al.,2019]。为了捕获跨模态关系的不同方面并增强多模态特征,我们提出在自监督损失下强制执行跨模态对齐。
Cross-modal Co-attention Mechanism
${\large Z_{t}^{i}=\left(\|_{h=1}^{H} \operatorname{softmax}\left(\frac{Q_{t}^{i} K_{t}^{i^{T}}}{\sqrt{d}}\right) V_{t}^{i}\right) W_{t}^{O}} \quad\quad\quad(11)$
按照上述多头注意力的方法分别用与图片特征 $R_{v}^{i}$ 和图特征 $R_{g}^{i} $ 得到两者的最终表示 $Z_{v}^{i} $ 和 $Z_{g}^{i}$。
接着使用交叉注意力机制,对于文本和视觉特征,进行如下交叉注意力机制,获得视觉和文本的特征:
$Z_{v t}^{i}=\left(\|_{h=1}^{H} \operatorname{softmax}\left(\frac{Q_{v}^{i} K_{t}^{i}}{\sqrt{d}}\right) V_{t}^{i}\right) W_{v t}^{O}\quad\quad\quad(12)$
Note:$Z_{v t}^{i}$ 代表着 text-visual feature 的融合,同理可以得到 visual-text feature 的融合 $Z_{t v}^{i}$。
Multi-modal Alignment
模型对齐:指增强的源帖图特征和文本特征被转换到相同的特征空间:
$\begin{array}{l}Z_{g}^{i^{\prime}}=W_{g}{ }^{\prime} Z_{g}^{i} \\Z_{t}^{i^{\prime}}=W_{t}^{\prime} Z_{v t}^{i}\end{array}\quad\quad\quad(13)$
然年通过 MSE 计算文本和视觉特征的特征对齐损失:
$\mathcal{L}_{\text {align }}=\frac{1}{n} \sum\limits_{i=1}^{n}\left(Z_{g}^{i^{\prime}}-Z_{t}^{i^{\prime}}\right)^{2}\quad\quad\quad(14)$
然后,我们得到了对齐参考的文本特征 $\tilde{Z}_{t}^{i}$ 和图特征 $\tilde{Z}_{g}^{i}$,它们用于下面的多模态融合。
Fusing the Above Multi-modal Features
再次使用上述的 cross-modal co-attention mechanism 获得三种模态特征 $\tilde{Z}_{t}^{i}$、$\tilde{Z}_{g}^{i}$、$Z_{v}^{i}$ 之间的多模态特征 $\tilde{Z_{t v}^{i}}$、$\tilde{Z_{v t}^{i}}$、$\tilde{Z_{g t}^{i}}$、$\tilde{Z_{t g}^{i}}$、$\tilde{Z_{g v}^{i}}$、$\tilde{Z_{v g}^{i}}$,最后将上述交叉模态特征拼接得到最终的多模态特征:
$Z^{i}=\operatorname{concat}\left(\tilde{Z_{t v}^{i}}, \tilde{Z_{v t}^{i}}, \tilde{Z_{g t}^{i}}, \tilde{Z_{t g}^{i}}, \tilde{Z_{g v}^{i}}, \tilde{Z_{v g}^{i}}\right)\quad\quad\quad(15)$
4.4 Classifcation with Adversarial Training
将帖子 $p_{i}$ 的多模态特征 $Z^{i}$ 输入全连接层,以预测 $p_{i}$ 是否是谣言:
$\hat{y}_{i}=\operatorname{softmax}\left(W_{c} Z^{i}+b\right)$
其中,$\hat{y}_{i}$ 表示 $p_{i}$ 成为谣言的预测概率。然后我们用交叉熵损失函数作为
$\mathcal{L}_{\text {classify }}=-y \log \left(\hat{y}_{i}\right)-(1-y) \log \left(1-\hat{y}_{i}\right)$
总体损失可写如下:
$\mathcal{L}=\lambda_{c} \mathcal{L}_{\text {classify }}+\lambda_{a} \mathcal{L}_{\text {align }}$
其中,$\lambda_{c}$ 和 $\lambda_{a}$ 被用来平衡这两个损失。
5 Experiments
Datasets
- Weibo:微博数据集 ;
- PHEME:Twitter 平台上的数据,包括5 个 breaking news ;

Baselines
- EANN [Wang et al., 2018] is a GAN-based model exploiting both text and image data. It derives eventinvariant features and benefits newly arrived events.
- MVAE [Khattar et al., 2019] uses a bimodal variational autoencoder coupled with a binary classifier for multimodal fake news detection.
- QSAN [Tian et al., 2020] integrates the quantum-driven text encoding and a novel signed attention mechanism for false information detection.
- SAFE [Zhou et al., 2020] jointly exploits multi-modal features and cross-modal similarity to learn the representation of news articles.
- EBGCN [Wei et al., 2021] rethinks the reliability of latent relations in the propagation structure by adopting a Bayesian approach.
- GLAN [Yuan et al., 2019] jointly encodes the local semantic and global structural information and applies a global-local attention network for rumor detection.
Implementation Details
- training:validation:testing = 7:1:2
- 使用 [Yuan et al., 2019] 的 word vectors 初始化 word embedding。
- $H=8$ 代表着 $8$ 头注意力
- 并设置 $\lambda_{c} = 2.15$ 和 $\lambda_{a} = 1.55$
Results
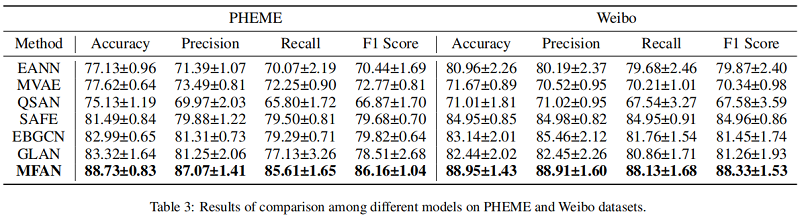
Performance of the Variations
“-w/o V”, “-w/o G”, “-w/o P”, and “-w/o A” 分别代表着不使用 visual information, social graph information,potential links, and modal alignment
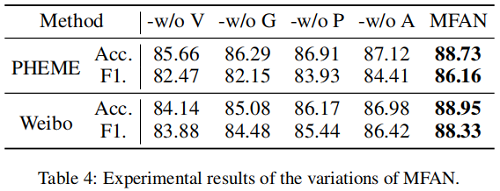
结果显示:
(i) visual modal and graph features are both important for rumor detection;
(ii) the modal alignment can facilitate the multi-modal fusion;
(iii) considering latent links can signifcantly improve;
6 Conclusions
在本文中,我们提出了一个多模态谣言检测框架,它通常包含了三种模态,即文本、图像和社交图。为了改进社会图特征学习,基于GAT增强了图拓扑和邻域聚合过程。我们的框架通过引入跨模态对齐来实现更有效的多模态融合。对中文和英语数据集的评估和比较表明,我们的模型可以优于最先进的多媒体谣言检测基线。
因上求缘,果上努力~~~~ 作者:图神经网络,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16670861.html

