谣言检测——《社会网络谣言检测综述》
论文信息
论文标题:社会网络谣言检测综述
论文作者:高玉君,梁 刚,蒋方婷,许 春,杨 进,陈俊任,王 浩
论文来源:2020,电子学报
论文地址:download
论文代码:download
1 介绍
- 首先,对谣言定义进行阐述,并描述当前谣言检测的问题及检测过程;
- 其次,介绍不同数据获取方式并分析其利弊,同时对比谣言检测中不同的数据标注方法;
- 第三,根据谣言检测技术的发展对现有的人工、机器学习和深度学习的谣言检测方法进行分析对比;
- 第四,通过实验在相同公开数据集下对当前主流算法进行实证评估;
- 最后,对社会网络谣言检测技术面临的挑战进行归纳并总结。
- 人工检测方法;[8-11]
- 基于机器学习的检测方法;[12-13]
- 基于深度学习的检测方法;[14、6]
- 人工检测方法准确率高,但具有明显的滞后性,无法适应社会网络中海量数据;
- 机器学习方法将社会网络谣言问题看作有监督学习中的二分类问题,自动化程度高,有效地弥补了人工检测方法的不足,但基于机器学习的谣言检测方法依赖于人工提取与选择特征,耗费大量的人力、物力与时间,且得到的特征向量鲁棒性也不够健壮;
- 深度学习方法则比机器学习方法中通过特征工程得到的特征数据对原数据具有更好、更本质的表征性,从而能实现更好的分类效果;
社会网络谣言检测分类:
- 谣言检测;
- 谣言跟踪;
- 谣言立场分类;
- 谣言准确性分类;
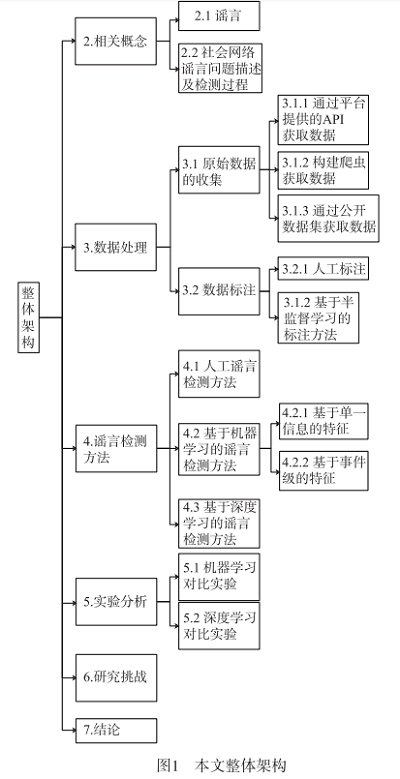
2 相关概念
2.1 谣言
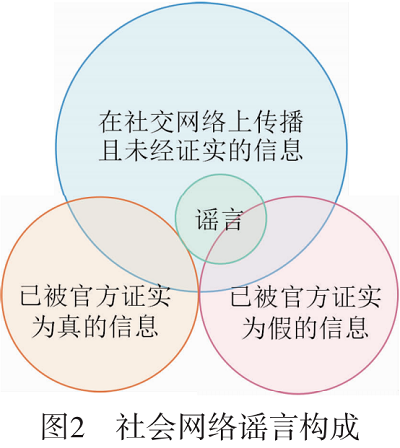
本文将社会网络谣言定义为一种在社会网络上传播且未经验证,或已被官方证实为假,并在社会网络中流传的信息。社会网络谣言的构成如图 2 所示,其特点是:发布门槛低、互动性强、散播速度快、散播方式和散播途径多样等。
2.2 社会网络谣言问题描述及检测过程
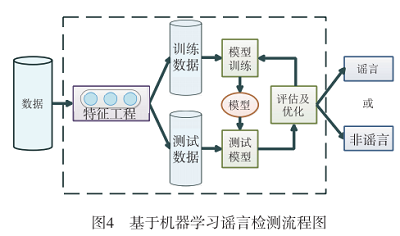
当前主流方法将社会网络谣言检测问题看作是有监督学习中的二分类问题,该问题的形式化定义如 下: 给定社会网络中每条推文的集合 $P=\left\{p_{1}, p_{2}, p_{3}, \cdots\right. , \left.p_{i}\right\}$ 和一个类别标签集合 $L=\left\{l_{1}, l_{2}\right\}$ ,其中, $p_{i}$ 代表一条 推文, $l_{1}$, $l_{2}$ 分别代表谣言和非谣言这两个类别标签。社会媒体谣言检测的任务是要学习一个分类模型 $M$ , 将推文 $p_{i}$ 映射成一个类别标签 $l_{j}$ , 即 $M: p_{i} \rightarrow l_{j}$ ,模型的输人是 一个包含有若干条微博的事件, 输出是该事件对应的谣言或非谣言标签。
社会网络谣言检测过程通常包含:数据处理、特征选择与提取、模型训练与谣言检测四个阶段。
- 数据处理包括原始数据的收集与数据标注,数据收集的作用主要有两项:第一,用于构建模型训练的数据集;第二,对社会网络进行监控,获取待检测的社会网络信息。数据标注则是根据问题及需求的不同对数据进行不同的标注。
- 特征选择与特征提取是从收集的原始数据中选择与构造出最能代表数据的特征向量集合。对于机器学习方法而言,特征选择与提取的重要程度甚至超过了模型选择的重要性。因此现有基于机器学习方法的重要工作是以找到更有效的特征作为提升谣言检测准确率为主要思路。基于深度学习的谣言检测具有很强的特征学习能力,其无需对特征进行人工提取即可得到比传统机器学习更高维、复杂、抽象的特征数据.
- 模型训练是指根据具体的问题场景从已有的分类模型中选择模型,并根据模型在训练数据集上的分类表现调整参数以找到一个最优模型的过程。对于社会网络谣言问题,如何在充满噪音、且不均衡的海量数据信息中训练出准确率高的分类器是当前社会网络谣言检测问题面临的最大挑战。
- 谣言检测则是根据模型训练中得到的谣言分类器对社会网络中传播的信息进行信息真实性的鉴别。
3 数据处理
数据处理是社会网络谣言自动检测技术的基础,包括原始数据收集与数据标注两个阶段。本节将对数据收集与数据标注的方法及其存在的问题进行总结与分析。
3.1 原始数据的收集
原始数据的收集是谣言检测工作的第一步。社会网络中充斥着各种各样的信息使得获取庞大的数据集成为可能。如表 1所示,目前社会网络的收集方式主要有三种:通过社会网络平台提供的 API 获得,用户自己构建通用爬虫获得以及直接获取第三方提供的公开数据集。
3.1.1 通过平台提供的 API 获取数据
基于平台提供的 API 获取数据的方法优点是简单快捷,但其缺点也十分突出:
(1)受限于社会网络平台的保护策略,通过平台 API 获取的数据在数据爬取速度及爬取数量上都受到严格控制,无法满足用户研究的需求。
(2)收集的数据具有较强的先验性,利用 API 收集数据存在一个先决条件:需要用户提供搜索关键字,根据搜索关键字收集微博中对应用户或是对应事件的信息。所以基于 API 的数据收集方法在社会网络谣言问题中只适用于收集模型训练中的数据集,而无法有效用于实时监控数据的收集。
3.1.2 构建爬虫获取数据
(1)受限于法律;
(2)技术复杂度高;
3.1.3 通过公开数据集获取数据
公开数据集在一定程度将研究者从琐碎繁重的数据收集工作中解放出来,让研究者集中精力在谣言检测方法的研究。但是公开数据集存在的弊端也显而易见:
(1)公开数据集中的数据也是通过 API 或是爬虫获取得到的,所以 API 或是爬虫获取数据的问题在公开数据集中依然存在。
(2)收集的数据可能无法满足用户的实际需求,公开数据是数据提供者根据自己的知识背景与经验收集的数据,在收集时无法做到面面俱到,从而满足所有用户的需求。
3.2 数据标注
- 数据标注分为:
- 人工标注
- 基于半监督学习标注
3.2.1 人工标注
人工标注方法是指专人对收集的初始数据的类别(谣言或正常信息)进行标记。为了避免认知的偏差,现有的人工标注方法通常会聘请两人及以上标注者对数据内容同时进行标注,并从初始数据集中选择标注结果相同的项作为最终训练数据集的候选项。人工标注方法简单直接,但该方法耗费了大量的人力、物力与时间,而且标注的质量依赖于标注者的知识背景与经验。
3.2.2 基于半监督学习的标注方法
针对人工标注方法的问题,Wu等人首次在社会网络谣言检测问题中引入基于半监督学习的自动标注方法,在人工标注少量数据的条件下,引入了一种叫做CERT( Crosstopic Emerging Rumor deTection)的框架,该框架联合聚类数据、选择特征和训练分类器实现数据的分类。基于半监督学习的自动标注方法简单且易实现,在一定程度上缓解了人工标注方法存在的问题,但该方法的先决条件太强,需要研究者能准确地估计数据分布信息。但在实际工作中,研究者很难事先对数据做出准确的模型估计。因此社会网络谣言检测问题中,人工标注方法依然占主导地位。
4 谣言检测方法
- 谣言检测方法分为:
- 人工谣言检测方法;
- 基于机器学习的谣言检测方法;
- 基于深度学习的谣言检;
4.1 人工谣言检测方法
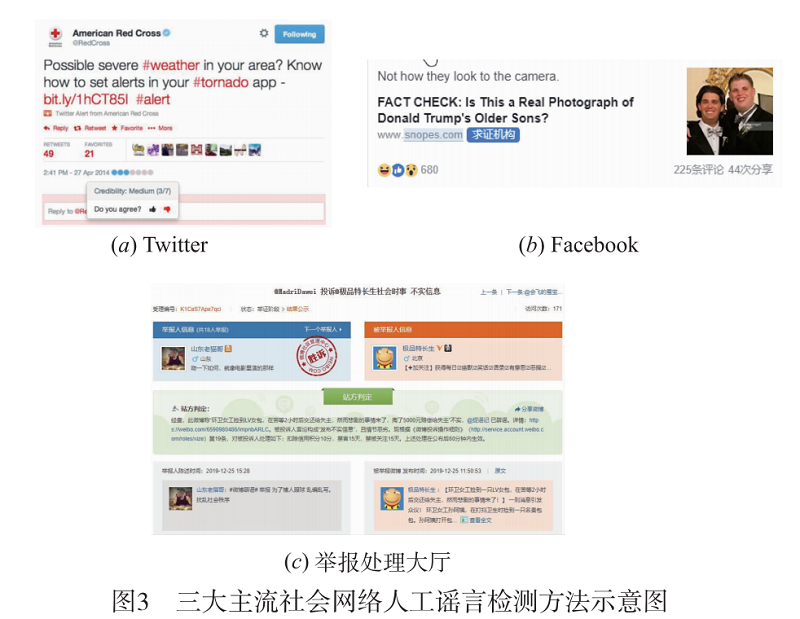
人工谣言检测方法是当前社会网络平台主流的谣言检测方式,平台将社会网络中的可疑信息交给经验丰富的编辑或是行业专家,利用编辑和专家的领域知识和经验对信息的真实性进行甄别.当前的主流社会网络平台,如 Twitter、Facebook与新浪微博,在其平台上都是采用人工的谣言检测方法。
- Twitter采用众包方法对平台上的信息的真实性进行鉴别。Twitter设计了一种信息真实性判别算法,该算法能根据 Twitter上用户对信息的评价计算平台上每一条信息的真实度。
- Facebook采用人工标注与权威媒体证实相结合的方法对 Facebook上的传播信息的真实性进行判别。Facebook用户一旦在 Facebook上发现可疑信息,可通过平台的接口提交其发现的可疑信息,被举报的信息其后通过权威媒体(比如 FactCheck。或 Snopes.com)提供的 API 提交给该媒体的编辑,由权威媒体的编辑与专家对消息的真实性进行甄别。
- 新浪微博平台提供了两种不实信息检测方法,第一种是“微博辟谣”,“微博辟谣”是微博平台上的一个公众号, 该公众号定期发布平台上发现的不实信息,凡是关注了该公众号的微博用户第一时间可以了解到微博平台中不实信息的传播情况。第二种方法是“举报处理大 厅”,该方法同样采用众包方法,微博用户通过“举报处理大厅”提供的接口向平台举报可疑的信息,微博平台的专家对举报的信息进行鉴别,并在平台上公布鉴别结果。
图 3 展示三大社交网络平台使用的谣言检测方法;
4.2 基于机器学习的谣言检测方法
对于基于机器学习的谣言检测方法而言, 如何选 择与提取出显著的特征来表征数据对谣言检测的效果至关重要。早在 1999 年, Waikato 大学 Mark A Hall 就在其博士论文《Correlation-based Feature Selection for Machine Learning》中指出: “选择与提取有效的特征对于分类算法非常重要,其重要性在某种程度上甚至超过了分类模型的选择”。因此基于机器学习的谣言检测方法在某种程度上可以说是一种基于特征工 程的方法。
有的用于检测社会网络谣言的特征提取 方式主要包括:
(1)基于单一信息的特征提取方式,通过提取单条数据的特征来处理数据;
(2)基于事件级特征提取方式,通过挖掘数据之间层次性关系来提取数据之间的潜在联系。
本节将分析基于单一信息的特征与基于事件级特征两种特征提取方式并描述其谣言检测的过程。
4.2.1 基于单一信息的特征
基于单一信息的特征提取方式是早期谣言检测中最常使用的方法,根据特征提取复杂度的不同,可分为显式特征 ( explicit feature) 与隐式特征 ( implicit feature)。
(1)显式特征
显式特征指的是通过直接选取即可获得的特征, 包括消息文本的长度、用户的个人信息、粉丝数以及转 发数等,表 2为各种显式特征及其特征描述。

对于机器学习方法而言,单纯地通过文本,用户以及传播特征[8,21,27,41,42]等进行信息真实性的鉴别是一件非常困难的事情。因此,研究者们引 入一种动态的、潜在的隐式特征,用以提取数据之间的隐含关系。
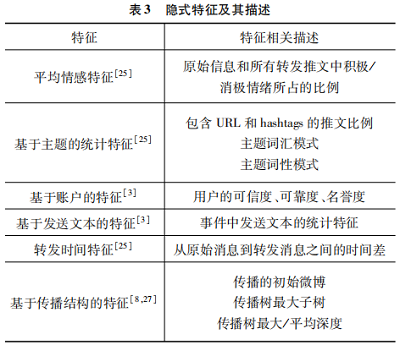
(2)隐式特征
隐式特征指的是无法直接获取, 需通过关联分析 或数值计算得到的一种潜在特征, 如平均情感特征、用 户可信度以及质疑率等, 如表 3 所示。
$\mathrm{Guo}^{[3]}$ 等人提取 了基于账户的特征 (Account-Based Features),包含从用 户简介和用户行为中提取用户可信度, 可靠性和名誉等隐含信息。Wu 等人提出主题类型特征(Topic Type Feature)、用户类型的特征(User Type Feature)、平均情感特征(Avg Sentiment Feature) 以及转发时间特征( Repost Time Feature),通过狄利克雷分布 (Latent Dirichlet Allocation,LDA) ${ }^{[43,44]}$ 提取消息的主题,该主题在消息中的概率分布可通过式 (1)求得:
$p\left(\beta_{1: K}, \theta_{1: D}, z_{1: D}, w_{1: D}\right) =\prod_{i=1}^{K} p\left(\beta_{i}\right) \prod_{d=1}^{D} p\left(\theta_{d}\right)\left(\prod_{n=1}^{N} p\left(z_{d, n} \mid \theta_{d}\right) p\left(w_{d, n} \mid \beta_{1 ; K}, z_{d, n}\right)\right)$
其中, $\beta_{1: K}$ 表示 $1$ 到 $K$ 的所有主题,$\beta_{i}$ 表示第 $i$ 个主题词 的分布,$\theta_{d}$ 表示第 $d$ 个消息中主题所占的比例, $z_{d, n}$ 表示 第 $d$ 个消息中第 $n$ 个词的主题,$w_{d, n}$ 表示第 $d$ 个消息中第 $n$个词。
除得到推文的主题类型之外,他们还考虑发帖者 是否是已被验证的用户,并通过基于词汇的平均情绪得分来判断情绪词与谣言之间的关联,并考虑原始消息和转发消息之间的时间间隔因素。通过基于随机游走图核(Random Walk Graph Kernel)的 SVM 检测算法在随机选取的微博数据上得到 91.3% 的准确率。在社会网络传播的信息其实隐藏着用户的某种行为,Mendoza等人[45]在研究智利大地震时 Twitter 中的推文变化情况发现:相较于真实信息,谣言更容易引起受众的质疑。由此 Liang 等人[46]提出了一种基于用户行为特征的谣言检测方法,他们通过收集的微博数据发现:造谣者相较于正常信息发布者,为了逃避可能承担的惩罚以 及为了快速传播谣言信息,其用户行为与普通用户存 在着较大的行为差异,用户在阅读正常信息与阅读谣言信息时也存在着较大的行为差异。在此基础上, Liang 等人[47]还提出了包括质疑率,单位时间发文数在内共计10条特征用于社会网络谣言的实验。其中,质疑率表示用户所质疑的评论在所有评论中所占的比例。实验结果表明,该方法相较于传统的基于文本、用户与传播结构特征方法,查准率与查全率的提高均超过了 15%。
基于单一信息的特征提取方式虽简单,但存在以下不足 :
(1) 依赖人工进行特征的选择,耗费人力物力的同时,得到特征向量的鲁棒性较差。
(2) 选取的特征主要集中在从原始消息和转发消 息中提取大量的词汇和语义特征,并从标记的数据中学习模型 [8,21],难以全面系统地概括谣言的特点。
(3) 加人用户特征虽引人了消息之间的关系且构造机器学习的特征向量也相对方便,但忽略了消息传输的内部图形结构以及该结构下用户之间的差异 [25]。同时,仅依赖于社交媒体平台提供的用户信息,无法真正有效地对不同平台用户发布的信息进行检测。
4.2.2 基于事件级的特征
仅仅提取单一信息的特征往往忽略了谣言之间的 联系,而基于事件级特征可通过其层次性结构反映出谣言之间的潜在关联。本节将基于事件级的特征定义为用户、消息、子事件、事件之间的层次关系特征。如图 5所示.

该层次结构是由用户层、消息层、子事件层以及事件层组成的多类型网络结构。其中,事件层为 $E=\left\{e_{1}\right. , \left.e_{2}, e_{3}, \cdots, e_{k}\right\}$ , 指在特定时间、特定地点包含一定关键词 的事件集合; 子事件层为 $S=\left\{s_{k, 1}, s_{k, 2}, s_{k, 3}, \cdots, s_{k, n}\right\}$,指 每个事件中子主题的集合;消息层为 $M=\left\{m_{n, 1}, m_{n, 2}\right. , \left.m_{n, 3}, \cdots, m_{n, i}\right\}$ , 指用户发出的原贴以及转发贴的集合。层内链接反映同一层级内实体之间的关系, 而层间链 接则反映了不同层级之间的关系。2012 年,Gupta 等 人[49] 提出了一种基于事件图优化(Event Graph-based Optimization) 的可信度分析方法。根据事件重要程度的 不同赋予不同的分数, 同时, 通过对新事件层次化关系 之间使用正则化更新事件可信度得分来增强基本的可信度分析。在数百万条推文的数据集上,参考 Castillo 等 人 [8] 用四种机器学习算法进行实验,得到高于文献 [8] 方法 14 % 的准确率,说明基于事件的层次化结构优于 基本的基于单条推文的可信度分析方法。此后, Sun 等 人 [24] 引人一种新的基于多媒体的特征 (MultimediaBased Feature),加入了图片的特征, 并根据该项特征来判断微博信息中包含的图片是否是过去图片。采用朴素贝叶斯、贝叶斯网络、神经网络以及决策树对新特征进行验证,发现该特征在贝叶斯网络中可获得 85 % 的 准确率。由于不同主题事件中不同层级或层内消息在谣言检测中的潜在联系也是不同的,因此,Jin 等人 [50]
首次引人子事件层, 提出了一种分级传播模型( Hierarchical Propagation Model), 用以对从消息级到事件级新闻可信度进行评估。 该模型由事件、子事件和消息组成 三层可信度网络,并利用这些实体之间的语义和社会关系建立联系,同时将该网络的可信度传播过程表示为图的优化问题,用以求出迭代算法的全局最优解。 在两个数据集该模型的准确率提高了 6%以上,F-score[51] 提高了16%以上。
结合谣言的层次结构虽然可弥补基于单条推文特征的一些不足,但其本质还是通过人工选择并提取特 征。因此,仍存在机器学习中特征提取的通病:
(1)难以获得高维、复杂、抽象的特征数据。
(2)试图用一套通用的特征集合表征社会网络不同平台不同语言中的全部信息,训练出来的谣言分类器容易陷入“过拟合”状态 [52],模型准确度不高。
(3)所有的实验都在研究者自己选择的数据集上进行实验,并不能有效地体现出新提出的特征在不同平台不同数据集下对谣言检测的作用。
4.3 基于深度学习的谣言检测方法
由于传统机器学习的谣言检测方法依赖特征工程需要耗费大量的人力、物力与时间来选择合适的特征向量,因此, 研究者们尝试在社会谣言问题检测中引人深度学习的方法。深度学习具有很强的特征 学习能力, 其模型学习的特征比传统机器学习算法中通过特征工程得到的特征数据对原数据具有更好的, 更本质的代表性,从而能实现更好的分类效果[14]。本节以基于深度学习的谣言检测技术的发展 为线索,深人分析并总结了现有的基于深度学习的谣言检测方法。
微博中的信息是一种与时间密切相关的时序数据,而循环神 经网 络 ( Recurrent Neural Network, $\mathrm{RNN}$) [53,54] 在时间序列和句子等变长序列信息建模方面显示出了强大的功能。2016 年, $\mathrm{Ma}$ 等人 [55] 首次将循环神经网络引人到谣言检测中, 通过对文本序列数 据进行时间维度上的建模分析得到谣言上下文信息随时间变化的隐式特征。加人长短期记忆 ( Long-ShortTerm Memory, LSTM ) [56,57] 以及门控循环单元 ( Gated Recurrent Unit, GRU) [58] 等额外的隐藏层,解决了在长序列训练过程中, 随着 RNN 层数的加深而造成的梯度消失与梯度爆炸问题 [59,60] , 从而提高谣言检测的准确度。在微博数据集上,加人双层 GRU 的循环神经网络准确率为88.1%,在 Twitter 数据集上,其准确率高达 91.0%,都 超过了基 础 tanh RNN 与加 入 一 层 LSTM/GRU 的谣言检测准确率。
图 6为基于循环神经网络的谣言检测的流程图。
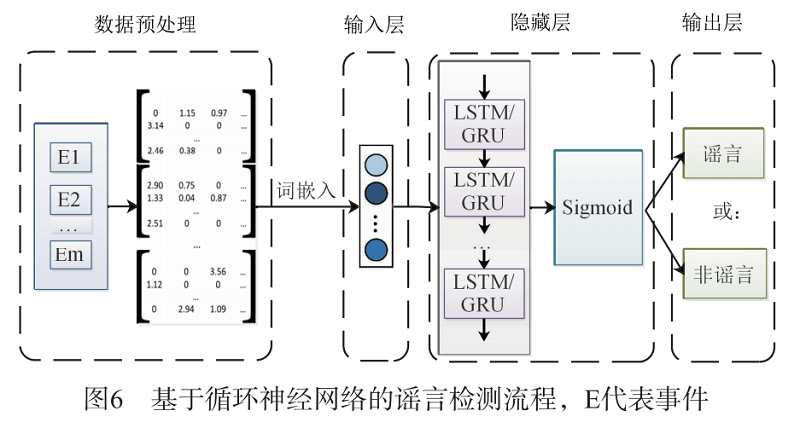
首先,针对每个事件收集相关帖子,对输入的事件文本数据得到 tf-idf 值矩阵,再将高维的词袋模型向量通过词嵌入的方式转成低维空间的向量表示,得到输入值。然后,将该值输入到 RNN 模型中,通过循环神经网络捕获文本序列的相关语义特征,由于基础的隐藏层没有门控单元,在 $t$ 时刻向前反向传播的过程中,存在梯度消失(大部分情况 下)或者梯度爆炸的情况,使得该结构难以捕捉长距离依赖,为缓解基础模型带来的缺陷,在隐藏层加入门控单元 LSTM/GRU,通过门(gate)机制控制隐藏层 中的信息流动,保留了文本间的语义信息,以提高谣言检测的准确度。最后,通过 Sigmoid 激活函数输出分类标签,预测是否是谣言。
然而,在谣言爆发的初期,无法获取足够的标记 数据用来训练模型,因此,为能够尽早地检测出社会网络中的谣言,Chen 等人[52]提出结合循环神经网络和变分自编码器(Variational Auto Encoder)[61]的无监督学习模型来学习社会网络用户的网络行为,由于正常数据与异常数据在降维过程中存在着显著的差异[62],因此利用模型得到输出值和输入的目标值之间的误差与指定阈值进行比较,判断其是否是谣言。其中,RNN 与自编码器(Auto Encoder,AE)的结合模 型如图 7所示。
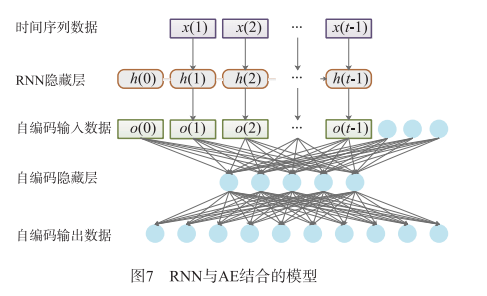
该模型主要分成两个模块进行层次训练,分别为 RNN 模块和 AE 模块。首先将收集到的不同时间节点的微博数据进行清洗后,建立特征工程,通过微博内容提取是否有图片,是否有转发,是否是积极态度等 15 个特征, 传入 RNN 模块,并在时间维度上进行训练;然后将该模 块的输出结合发博时间,发博来源等其余特征送入 AE 模块,通过 AE 实现无监督的异常检测,通过一系列的矩 阵映射将输出重构成与输入形状相同的结构;最后,使用欧几里得范式计算 AE 模块输入的目标值和输出值之间的误差,并与设定的阈值比较,从而判断该推文是否是谣言。该模型实现了单隐藏层和多隐藏层结构,两层模型的准确率分别为 92.49% 和 89.16%。但该模型只在新浪微博的谣言数据下进行实验,并不能很好地验证出其在不同平台数据下的适应性。因此,Wen 等人[23]设计了一个基于神经网络的模型,该模型采用了跨语言、跨平台的有限元分析方法,利用不同平台和语言之间的信息相似性和一致性来验证谣言。Ajao等人[63]利用卷积神经网络(Convolutional Neural Networks, CNN)和长短期循环神经网络模型(Long-Short Term Recurrent Neural Network Models)来检测并分类 Twitter 上发布的虚假新闻。该方法无需任何人工提取外部特征的步骤即可直观地识别与谣言相关的特征。
传统的基于深度学习的谣言检测方法摆脱了人工 构建特征工程的方式。然而, 天然的端到端结构难以把 握谣言信息中的关键成分, 模型训练缺乏可控性,训练时间长且模型复杂。 因而引人注意力机制 (Attention Mechanism [30,64] 进行谣言检测。注意力机制最早提出于视觉图像 [65] 领域,该方法借鉴了人类的注意力思维方式,模仿人类对图片不同地方的观察侧重点,用以对图像不同位置施加不同的权重,从而决定更重要的部分,并提高该部分的权重,降低噪声部分的权重。 2014 年, Bahdanau 等人 [66] 首次将注意力机制引人自然语言处理领域,该工作首先通过对 Encoder 部分的输人和隐 藏状态值经过循环神经网络进行编码,从而输出中间向量,再由 Decoder 部分将中间向量借助另一个循环神经网络解码成输出向量。
基于注意力机制在谣言检测领域的应用,Chen 等人 [11] 提出一种基于注意力机制的循环神经网络 模型 CallAtRumors(Call Attention to Rumors),加人注 意力机制从重复、不断变化的推文中提取出隐式与 显式的谣言特征,用于对社会网络信息序列中选择 关注度高的信息进行检测,在模型训练中,采用交叉熵损失函数和双重随机正则化 [67] 相结合的方法,对输人字矩阵的每个元素进行校正,其损失函数如式 (2) 所示 :
$L=-\sum_{t=1}^{\tau} \sum_{i=1}^{c} y_{t, i} \log y_{t, i}^{\prime}+\lambda \sum_{i=1}^{K}\left(1-\sum_{t=1}^{\tau} a_{t, i}\right)^{2}+\gamma \varphi^{2} $
其中, $y_{i}$ 表示独热标签向量 (one hot label vector),$y_{i}^{\prime}$ 表示 在 $t$ 时刻的二分类概率向量, $\tau$ 表示总时间, $C$ 表示输出类的数目,其数值为 $2$ (表示谣言或非谣言 ),$ \lambda$ 表示注意力分配系数, $\gamma$ 表示权值系数, $\varphi$ 代表所有模型参数。
该模型在 Twitter 与新浪微博上分别取得 88.63 % 和 87.10 % 准确率。Jin 等人 [1] 在此基础上加人图片这 一特征,使用循环神经网络来学习文本和社会背景( social context)相结合的表示;使用卷积神经网络训练提取图像的视觉特征;使用注意力机制对视觉特征和共 同的文本/社会背景特征分配不同权重.融合了文本、 图像和社会背景特征对 Twitter 和新浪微博数据集进行 谣言检 测,但 其 在 两 个 数 据 集 上 的 准 确 率 分 别 为78.8%和68.2%,难以保证谣言检测的效果。因此,Guo 等人[3]提出了一种结合社会信息(social information)的 层次神经网络(HSA-BLSTM)方法用于谣言检测。首先建立了表示学习的层次双向长短时记忆模型(Hierarchical Bi-directional Long Short-term Memory Model),然 后通过注意力机制将社会背景整合到网络中,最后在新浪微博和 Twitter 中进行实验,分别取得94.3%和 84.4%的准确率。与 Guo 等人[3]类似,Liao 等人[68]通过采用两层带有注意力机制的双向 GRU 网络从微博内容和时间层面分别获取微博序列的隐藏层表示和时间 段序列的隐藏层表示,从而在事件的特征表示中融入了时间段内各微博间的时序信息。此外,还针对各个时 间段提取了局部用户特征及文本潜在特征,并将这些 特征融入到时间段中,进一步捕获这些特征随时间变 化的隐藏层状态值,最终得到 96.8%的谣言检测准确率。但该方法依赖人工对事件进行时间段划分,在花费人力及时间的基础上还可能带来信息的丢失。为通过区别原贴和转发贴来检测谣言,Xu等人[69]考虑原帖内容、转发帖的扩散情况以及用户信息三方面,提出一个融合神经谣言检测(Merged Neural Rumor Detection, MNRD)模型,通过基于内容的注意力机制的原贴编码 和基于扩散的注意力机制的转发编码分别学习从原贴 和转发中提取高层次的特征表示,通过用户特征编码 器对用户信息进行编码,以获取用户可靠性和社会影 响力,结合这些特征对谣言进行检测。在新浪微博数据 集上取得 94.4%的准确率。
基于注意力机制的循环神经网络模型不仅具有很强的特征学习能力,同时能捕获谣言中的重要语义成分,但其仍存在以下不足: (1)对数据的需求量大,当样本数据较少时,训练出来的分类器仍存在分类偏倚[70]问题。 (2)模型训练周期更长,训练出的模型可解释性差。(3)需要 GPU 来高效优化矩阵运算,对 GPU 的要求较高。
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16650417.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号