论文解读(MSN)《Masked Siamese Networks for Label-Effificient Learning》
论文信息
论文标题:Masked Siamese Networks for Label-Effificient Learning
论文作者:Mahmoud Assran, Mathilde Caron......
论文来源:2022,arXiv
论文地址:download
论文代码:download
1 Introduction
在 Siamese Network 的基础上使用 Mask Patch 策略,并添加原型监督的方式。
2 Method
整体框架:
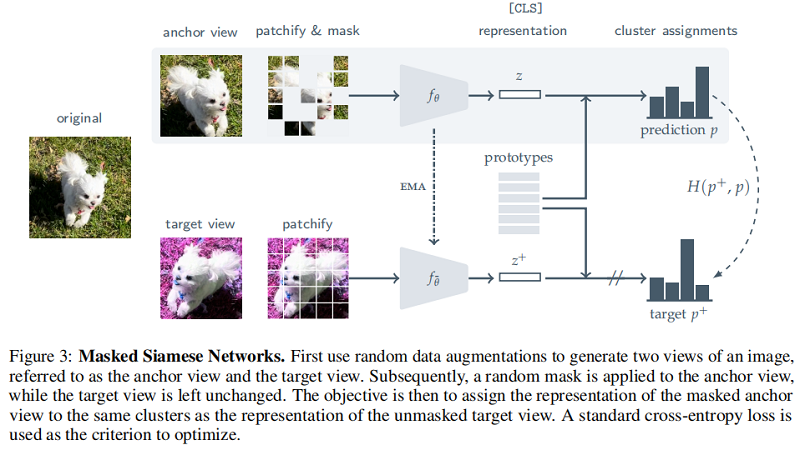
输入视图在每次预训练迭代中,我们采样一小批 $B \geq 1$ 图像。对于一个索引 $i \in[B]$,让 $\mathbf{x}_{i}$ 表示小批处理中的第 $i$ 幅图像。对于每个图像 $\mathbf{x}_{i}$,我们首先应用一组随机的数据增强来生成一个目标视图,表示为 $\mathbf{x}_{i}^{+}$,和 $M \geq 1$ 锚定视图,表示为 $\mathbf{x}_{i, 1}, \mathbf{x}_{i, 2}, \ldots, \mathbf{x}_{i, M}$。
Patchify and Mask
将小批量中的样本变为 $N \times N$ 的 patches ,接着对上述数据增强的 anchor views 生成相应的带 mask patchs 的 $\hat{\mathbf{x}}_{i, m}$,$\hat{\mathbf{x}}_{i}^{+}$ 代表着没有 mask patch 的 target patches。由于 mask patch 策略,$\hat{\mathbf{x}}_{i, m}$ 的长度和 $\hat{\mathbf{x}}_{i}^{+}$ 不同,所以本文提出两种 mask patch 策略,如 Figure 4。

编码器给定一个参数化的 anchor encoder ,表示 $f_{\theta}(\cdot)$,让 $z_{i, m} \in \mathbb{R}^{d}$ 表示从 masked) anchor view $\hat{\mathbf{x}}_{i, \underline{m}}$ 计算出的表示。类似地,给定一个参数化的 target encoder $f_{\bar{\theta}}(\cdot)$,具有潜在的不同的参数集 $\bar{\theta}$,让 $z_{i}^{+} \in \mathbb{R}^{d}$ 表示从模式化的 target view $\hat{\mathbf{x}}_{i}^{+}$ 计算出的表示。在 msn 中,target encoder 的参数 $\bar{\theta}$ 通过 anchor encoder 参数的指数移动平均进行更新。我们将网络的输出作为对应于[CLS]令牌的表示。
假设 $\mathbf{q} \in \mathbb{R}^{K \times d}$ ($K>1$)代表着可学习的原型,利用 anchor representation $z_{i, m}$ 和 $\mathbf{q} \in \mathbb{R}^{K \times d}$ 计算相应原型分配 $p_{i, m}$。
$p_{i, m}:=\operatorname{softmax}\left(\frac{z_{i, m} \cdot \mathbf{q}}{\tau}\right)$
同样,target representation $z_{i}^{+} $ 也计算相应原型分配 $p_{i}^{+} \in \Delta_{K}$ 。
当锚点预测 $p_{i, m}$ 与目标预测 $p_{i}^{+}$ 不同时,我们进行惩罚。我们使用一个标准的交叉熵损失 $H\left(p_{i}^{+}, p_{i, m}\right)$ 来强制执行这个准则。
我们还加入了平均熵最大化 (ME-MAX) 正则化器,以鼓励模型利用完整的原型集。表示所有锚点视图的平均预测
$\bar{p}:=\frac{1}{M B} \sum\limits _{i=1}^{B} \sum\limits_{m=1}^{M} p_{i, m} .$
总损失如下:
$\frac{1}{M B} \sum\limits_{i=1}^{B} \sum\limits _{m=1}^{M} H\left(p_{i}^{+}, p_{i, m}\right)-\lambda H(\bar{p})$
因上求缘,果上努力~~~~ 作者:图神经网络,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16517577.html

