论文解读(GMAE)《Graph Masked Autoencoders with Transformers》
论文信息
论文标题:Graph Masked Autoencoders with Transformers
论文作者:Sixiao Zhang, Hongxu Chen, Haoran Yang, Xiangguo Sun, Philip S. Yu, Guandong Xu
论文来源:2022, ArXiv
论文地址:download
论文代码:download
1 Introduction
提出目的:
-
- 深层 Tramsformer 的困难;
- 指数级的内存消耗;
2 Related work
2.1 Graph Representation Learning
Model 目标:
$f\left(A, X_{V}, X_{E}\right)=H_{o}$
其中:
-
- $X_{V} \in \mathbb{R}^{n_{V} \times d_{V}} $ 代表这节点特征;
- $X_{E} \in \mathbb{R}^{n_{E} \times d_{E}}$ 代表着边特征;
- $A \in \mathbb{R}^{n_{V} \times n_{V}}$ 代表着邻接矩阵;
2.2 Graph Transformers
Definition
可学习权重矩阵:
-
- $W_{Q} \in \mathbb{R}^{d \times d_{q}}$
- $W_{K} \in \mathbb{R}^{d \times d_{k}}$
- $W_{V} \in \mathbb{R}^{d \times d_{v}}$
通常:$d_{q}=d_{k}$
首先计算三个矩阵:
$Q=H W_{Q},K=H W_{K},V=H W_{V}\quad\quad\quad(2)$
然后将点积应用于具有所有键的查询,以获得该值的权重。最终的输出矩阵是由
$\operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}} V\right)\quad\quad\quad(2)$
得到的输出矩阵是一个大小为 $n \times d_{v}$ 的矩阵,其中每一行表示对应实例的输出表示。
然后使用 $2$ 层前馈网络(FFN)对节点表示 $x$ 进行投影,提高模型质量:
$F F N(x)=\max \left(0, x W_{1}+b_{1}\right) W_{2}+b_{2}\quad\quad\quad(4)$
3 Method
主要框架如下:
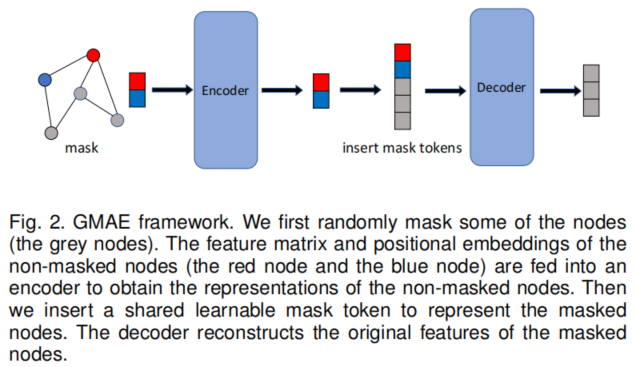
主干模型是 Graphormer。
步骤:
-
- i) Randomly mask nodes in the input graph.
- ii) Feed the non-masked nodes into the encoder and obtain the embeddings of them.
- iii) Use a shared learnable mask token to represent the embeddings of the masked nodes and insert them into the output of the encoder.
- iv) Feed the embedding matrix with inserted mask tokens into the decoder to reconstruct the features of the masked nodes.
对于 Transformer 中的 Positional embeddings 设计,本文同样遵循 Graphormer 中的 Positional embeddings 设置,其中需要知道的是node degrees、shortest path distances、the edge features。
本实验中的 Encoder 是16 层,而 Decoder 是 2 层。
4 Experiment
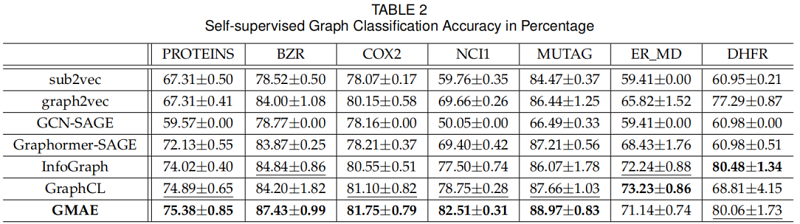
数据集

图分类
修改历史
2022-06-16 创建文章
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16381344.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号