论文解读(GraphSMOTE)《GraphSMOTE: Imbalanced Node Classification on Graphs with Graph Neural Networks》
论文信息
论文标题:GraphSMOTE: Imbalanced Node Classification on Graphs with Graph Neural Networks
论文作者:Tianxiang Zhao, Xiang Zhang, Suhang Wang
论文来源:2021, WSDM
论文地址:download
论文代码:download
1 Introduction
节点分类受限与不同类的节点数量不平衡,本文提出过采样方法解决这个问题。
图中类不平衡的例子:
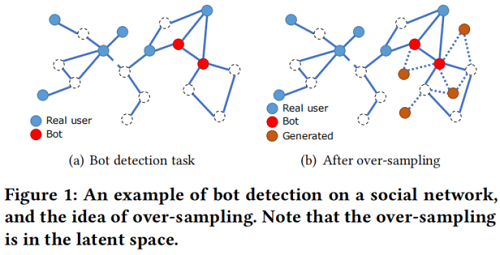
图中:每个蓝色节点表示一个真实用户,每个红色节点表示一个假用户,边表示关系。任务是预测未标记的用户(虚线圈)是真实的还是假的。这些类在本质上是不平衡的,因为假用户通常还不到所有用户的1%。半监督设置进一步放大了类不平衡问题,因为我们只给出了有限的标记数据,这使得标记的少数样本的数量非常小。
在不平衡的节点分类中,多数类主导着损失函数,使得训练后的 GNNs 对这些类过度分类,无法准确预测样本。
目前解决类不平衡问题的方法可以分为:
-
- data-level approaches(数据级方法)
- algorithm-level approaches(算法级方法)
- hybrid approaches(混合方法)
数据级方法寻求使类分布更加平衡,使用过采样(over-sampling)或降采样(down-sampling)技术 [8,26];算法级方法通常对不同的类[11,22,44]引入不同的错误分类惩罚或先验概率;混合方法[9,23]将这两者结合起来。
以前的算法并不容易适用于图。
-
- 首先,对产生的新样本,很难生成边关系。主流过采样技术[26]利用目标示例与其最近邻之间的插值来生成新的训练示例。然而,插值不适合于边,因为它们通常是离散的和稀疏的,插值可以破坏拓扑结构。
- 第二,产生的新样本可能质量较低。节点属性是高维的,直接对其进行插值很容易生成域外的例子,对训练分类器不利。
2 Related work:Class Imbalance Problem
2.1 data-level method
通过过采样和下采样的方法调整类结构。
过采样的一般形式是直接复制现有样本,带来的问题是没有引入额外信息,容易导致过拟合问题。
SMOTE[8] 通过生成新样本来解决这个问题,在少数类和最近邻的样本之间执行插值,在此基础上的方法:
-
- Borderline-SMOTE [15] 将过采样限制在类边界附近的样本;
- Safe-Level-SMOTE [7]使用多数类邻居计算每个插值的安全方向,以使生成的新样本更安全;
- Cluster-based Over-sampling [17] 首先将样本聚为不同的组,而不是单独的过样本,考虑到输入空间中经常存在小区域;
下采样丢弃多数类中的一些样本,也可使类保持平衡,但代价是丢失一些信息。为此,提出只删除冗余的样本,如 [3,20]。
2.2 hybrid method
Cost sensitive learning [22,44] 通常构造一个成本矩阵,为不同的类分配不同的错误分类惩罚。效果类似于普通的的过采样。[28] 提出了一种近似于 $F$ 测量的方法,它可以通过梯度传播直接进行优化。
2.3 algorithm-level method
它结合了来自上述一个或两个类别的多个算法。[23] 使用一组分类器,每个分类器都在多数类和少数类的一个子集上进行训练。[9] 结合了 boosting 与SMOTE,[16] 结合了过采样与成本敏感学习。[33] 引入了三种成本敏感的增强方法,它们迭代地更新每个类的影响以及 AdaBoost参数。
3 Problem definition
在本文中,我们使用 $\mathcal{G}=\{\mathcal{V}, \mathrm{A}, \mathrm{F}\}$ 来表示一个属性网络,其中 $\mathcal{V}=\left\{v_{1}, \ldots, v_{n}\right\}$ 是一组 $n$ 节点。$\mathrm{A} \in \mathbb{R}^{n \times n}$ 为 $\mathcal{G}$ 的邻接矩阵, $\mathrm{F} \in \mathbb{R}^{n \times d}$ 表示节点属性矩阵,其中 $\mathrm{F}[j,:] \in \mathbb{R}^{1 \times d}$ 为节点 $j$ 的节点属性,$𝑑$ 为节点属性的维数。$\mathrm{Y} \in \mathbb{R}^{n}$ 是 $\mathcal{G}$ 中节点的类信息。
在训练过程中,只有 $Y$ 的一个子集 $\mathcal{V}_{L}$ 可用,其中包含节点子集 $\mathcal{V}_{L}$ 的标签。总共有 $m$ 类,$\left\{C_{1}, \ldots, C_{m}\right\} $。$\left|C_{i}\right|$ 是第 $i$ 类的大小,指的是属于该类的样本数量。我们使用不平衡率 $\frac{\min _{i}\left(\left|C_{i}\right|\right)}{\max _{i}\left(\left|C_{i}\right|\right)}$ 来衡量类不平衡的程度。在不平衡设置下,$\mathrm{Y}_{L}$ 的不平衡比较小。
给定节点类不平衡的 $\mathcal{G}$,以及节点 $\mathcal{V}_{L}$子集的标签,目标是学习一个节点分类器 $f$,可适用于多数类和少数类,即:
$f(\mathcal{V}, \mathbf{A}, \mathbf{F}) \rightarrow \mathbf{Y}\quad\quad\quad(1)$
4 Method
框架如下:
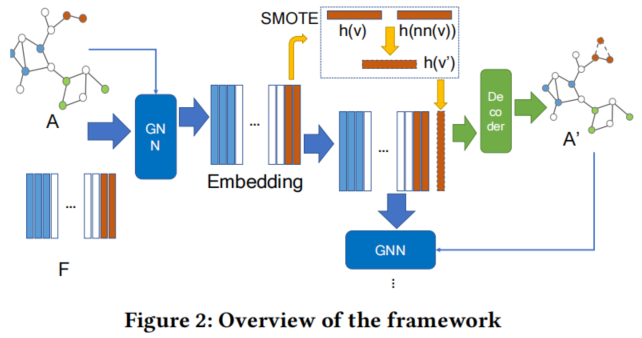
GraphSMOTE 的组成部分:
-
- a GNNbased feature extractor;
- Synthetic Node Generation;
- Edge Generator;
- GNN Classifier;
4.1 Feature Extractor
SMOTE 用于原始节点特征空间,带来的问题是:
-
- 原始特征空间可能是稀疏和高维的,且特征空间不好;
- 未考虑图的结构,可能会导致次优的合成节点;
本文提出的过采样方法同时考虑了节点表示和拓扑结构,并且遵循了同质性假设。本文研究中使用 GraphSage 作为主干模型结构来提取特征:
$\mathbf{h}_{v}^{1}=\sigma\left(\mathbf{W}^{1} \cdot \operatorname{CONCAT}(\mathbf{F}[v,:], \mathbf{F} \cdot \mathbf{A}[:, v])\right)\quad\quad\quad(2)$
其中,
-
- $F$ 表示输入特征矩阵,$\mathbf{F}[v,:]$ 表示节点 $v$ 的特征;
- $\mathrm{A}[:, v]$ 为邻接矩阵中的第 $v$ 列;
- $\mathbf{h}_{v}^{1}$ 为节点 $v$ 的嵌入;
- $\mathbf{W}^{1}$ 为权值参数;
- $\sigma$ 为 ReLU等激活函数;
4.2 Synthetic Node Generation
对少数类节点采用 SMOTE 算法思想:对目标少数类的样本与嵌入空间中属于同一类的最近邻样本进行插值。
设 $\mathbf{h}_{v}^{1}$ 为一个带标记的少数类节点,标记为 $Y_{v}$。第一步是找到与 $\mathbf{h}_{v}^{1}$ 在同一个类中的最近的标记节点,即:
$n n(v)=\underset{u}{\operatorname{argmin}}\left\|\mathbf{h}_{u}^{1}-\mathbf{h}_{v}^{1}\right\|, \quad \text { s.t. } \quad \mathbf{Y}_{u}=\mathbf{Y}_{v}\quad\quad\quad(3)$
其中,$n n(v)$ 是指同一类中 $v$ 的最近邻,可以生成合成节点为:
$\mathbf{h}_{v^{\prime}}^{1}=(1-\delta) \cdot \mathbf{h}_{v}^{1}+\delta \cdot \mathbf{h}_{n n(v)}^{1}\quad\quad\quad(4)$
其中,$\delta$ 为一个随机变量,在 $[0,1]$ 范围内呈均匀分布。由于 $\mathbf{h}_{v}^{1}$ 和 $\mathbf{h}_{n n(v)}^{1}$ 属于同一个类,且非常接近,因此生成的合成节点 $\mathbf{h}_{v^{\prime}}^{1}$ 也应属同一个类。
4.3 Edge Generator
边生成器是一个加权内积:
$\mathbf{E}_{v, u}=\operatorname{softmax}\left(\sigma\left(\mathbf{h}_{v}^{1} \cdot \mathbf{S} \cdot \mathbf{h}_{u}^{1}\right)\right)\quad\quad\quad(5)$
其中,$\mathbf{E}_{v, u}$ 为节点 $v$ 和 $u$ 之间的预测关系信息,$\mathrm{S}$ 为捕获节点间相互作用的参数矩阵。
边生成器的损失函数为:
$\mathcal{L}_{e d g e}=\|\mathbf{E}-\mathbf{A}\|_{F}^{2}\quad\quad\quad(6)$
此时,并没有合成节点,而是学习一个好的参数矩阵 $S$ 。利用边生成器,本文尝试了两种策略:
第一种,该生成器只使用边重建来进行优化,而合成节点 $v^{\prime}$ 的边是通过设置一个阈值 $\eta$ 生成:
$\tilde{\mathrm{A}}\left[v^{\prime}, u\right]=\left\{\begin{array}{ll}1, & \text { if } \mathbf{E}_{v^{\prime}, u}>\eta \\0, & \text { otherwise }\end{array}\right.$
其中,$\tilde{\mathrm{A}}$ 是过采样后的邻接矩阵,通过在 $A$ 中插入新的节点和边,并将其发送给分类器。
第二种,对于合成节点 $v^{\prime}$,使用软边而不是二进制边:
$\tilde{\mathbf{A}}\left[v^{\prime}, u\right]=\mathbf{E}_{v^{\prime}, u}$
在这种情况下,$\tilde{A}$ 上的梯度可以从分类器中传播,因此可以同时使用边缘预测损失和节点分类损失对生成器进行优化。
4.4 GNN Classifier
设 $\tilde{\mathbf{H}}^{1}$ 为将 $\mathbf{H}^{1}$ 与合成节点的嵌入连接起来的增广节点表示集,$\tilde{V}_{L}$ 为将合成节点合并到 $\tilde{V}_{L}$ 中的增广标记集。
对于当前的增强图 $\tilde{\mathcal{G}}= \{\tilde{\mathrm{A}}, \tilde{\mathbf{H}}\}$ 与标记节点集 $\tilde{V}_{L}$。在 $\tilde{G}$ 中,不同类的数据大小变得平衡,并且一个无偏的GNN分类器将可以在这上面进行训练。
本文采用另一个 GraphSage 块,在 $\tilde{G}$ 上附加一个线性层进行节点分类,如下:
$\mathbf{h}_{v}^{2}=\sigma\left(\mathbf{W}^{2} \cdot \operatorname{CONCAT}\left(\mathbf{h}_{v}^{1}, \tilde{\mathbf{H}}^{1} \cdot \tilde{\mathbf{A}}[:, v]\right)\right)\quad\quad\quad(9)$
$\mathbf{P}_{v}=\operatorname{softmax}\left(\sigma\left(\mathbf{W}^{c} \cdot \operatorname{CONCAT}\left(\mathbf{h}_{v}^{2}, \mathbf{H}^{2} \cdot \tilde{\mathbf{A}}[:, v]\right)\right)\right)\quad\quad\quad(10)$
式中,$\mathbf{P}_{v}$ 是节点 $v$ 在类标签上的概率分布,利用交叉熵损失进行优化,如下:
$\mathcal{L}_{n o d e}=\sum\limits _{u \in \tilde{V}_{L}} \sum\limits_{c}\left(1\left(Y_{u}==c\right) \cdot \log \left(\mathrm{P}_{v}[c]\right)\right.\quad\quad\quad(11)$
在测试过程中,将节点 $v$ 的预测类设置为概率最高的类 $\mathrm{Y}_{v}^{\prime}$。
$\mathbf{Y}_{v}^{\prime}=\underset{c}{\operatorname{argmax}} \mathbf{P}_{v, c}\quad\quad\quad(12)$
4.5 Optimization Objective
GraphSMOTE 的最终目标函数可以写成:
$\underset{\theta, \phi, \varphi}{\text{min }} \mathcal{L}_{\text {node }}+\lambda \cdot \mathcal{L}_{e d g e}\quad\quad\quad(13)$
其中,$ \theta,$、$\phi$、$\varphi$ 分别为特征提取器、边缘生成器和节点分类器的参数。由于模型的性能依赖于嵌入空间和生成的边的质量,为了使训练短语更加稳定,我们还尝试了使用 $\mathcal{L}_{e d g e}$ 进行训练前的特征提取器和边生成器。
4.6 Training Algorithm
完整算法如 Algorithm 1 :

5 Experiment
数据集
baseline
- Over-sampling:重复少数节点,$n_s$ 代表重复的少数节点数量,在每次训练迭代中,$\mathcal{V}$ 被过采样以包含 $n+n_{s}$ 节点,和 $\mathrm{A} \in \mathbb{R}^{\left(n+n_{s}\right) \times\left(n+n_{s}\right)}$。
- Re-weight [41]:一种成本敏感的方法,给少数样本分配较高的损失权重,以缓解多数类主导损失函数的问题。
- SMOTE [8]: 合成少数过采样技术通过插值一个少数样本及其同类的最近邻来生成合成少数样本。对于新生成的节点,将其边被设置为与目标节点相同。
- Embed-SMOTE [1]:SMOTE 的扩展,在中间嵌入层而不是输入域执行过采样。我们将其设置为最后一个GNN层的输出,因此不需要生成边。
- $\text { GraphSMOTE }_{T}$:边生成器仅使用边预测任务中的损失进行训练。
- $\text { GraphSMOTE }_{O}$: 预测边缘被设置为连续,以便从基于gnn的分类器计算和传播梯度。利用边缘生成任务和节点分类任务的训练信号,将边缘生成器与其他组件一起进行训练;
- $\text { GraphSMOTE }_{preT}$:是 $\text { GraphSMOTE }_{T}$ 的扩展,对特征提取器和边缘生成器进行预训练,然后对 $\text{Eq.13}$ 进行微调。 在微调过程中,边缘生成器的优化仅使用 $\mathcal{L}_{\text {edges }}$ ;
- $\text { GraphSMOTE }_{preO}$:是 $\text { GraphSMOTE }_{O}$ 的扩展,一个训练前的过程也会在微调之前进行,比如 $\text { GraphSMOTE }_{preT}$。
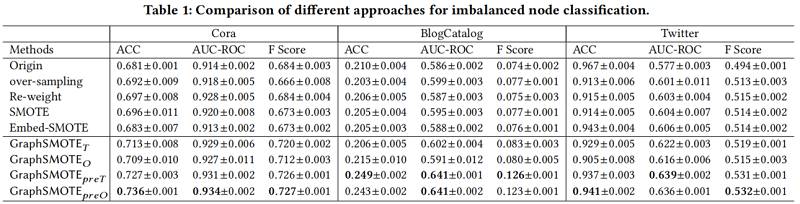
不平衡的节点分类
过采样量的影响
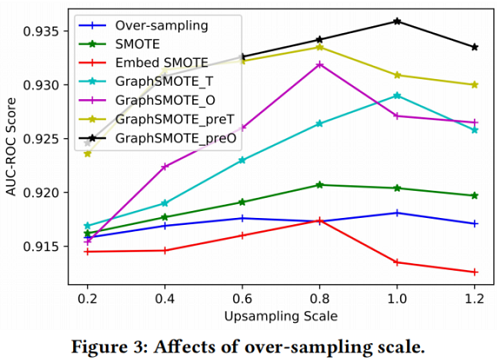
设置不平平衡率为 $0.5$,过采样的尺度为 $\{0.2,0.4,0.6,0.8,1.0,1.2\}$。
不平衡比的影响
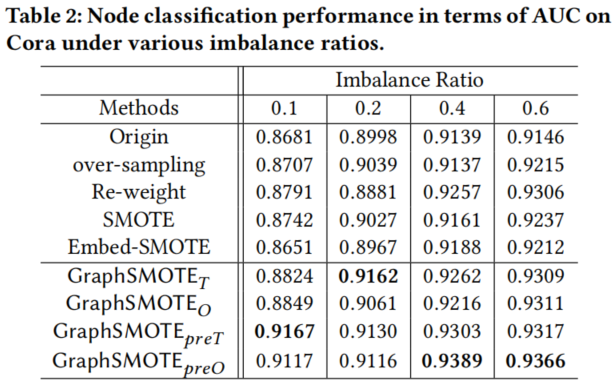
设置过采样的尺度为 $1$ ,不平衡率为 $\{0.1,0.2,0.4,0.6\}$。
基础模型的影响
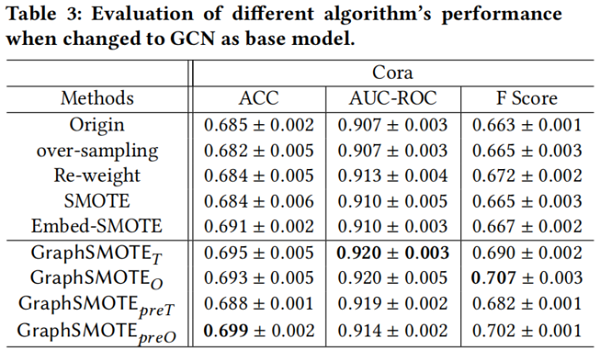
基础模型一个采用 GCN,一个采用 GraphSAGE。
参数敏感性分析
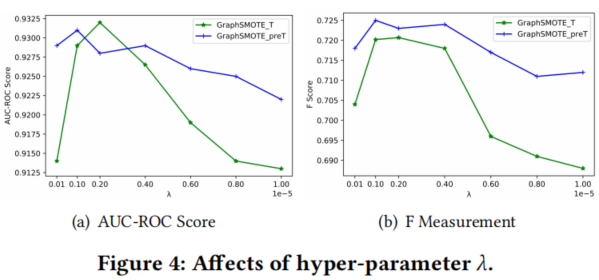
6 Conclusion
图中节点的类不平衡问题广泛存在于现实世界的任务中,如假用户检测、网页分类、恶意机器检测等。这个问题会显著影响分类器在这些少数类上的性能,但在以前的工作中没有被考虑。因此,在本工作中,我们研究了这个不平衡的节点分类任务。具体来说,我们提出了一个新的框架GraphSMOTE,它将以前的i.i.d数据的过采样算法扩展到这个图设置。具体地说,GraphSMOTE构造了一个具有特征提取器的中间嵌入空间,并在此基础上同时训练一个边缘生成器和一个基于gnn的节点分类器。在一个人工数据集和两个真实数据集上进行的实验证明了它的有效性,即大幅度地优于所有其他基线。进行消融研究是为了了解GraphSMOTE在各种场景下的性能。并进行了参数敏感性分析,以了解GraphSMOTE对超参数的敏感性。
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16336770.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号