论文解读(GraphDA)《Data Augmentation for Deep Graph Learning: A Survey》
论文信息
论文标题:Data Augmentation for Deep Graph Learning: A Survey
论文作者:Kaize Ding, Zhe Xu, Hanghang Tong, Huan Liu
论文来源:2022, arXiv
论文地址:download
DGL 存在的两个问题:
-
- 次优图问题:图中包含不确定、冗余、错误和缺失的节点特征或图结构边。
-
- 有限标签问题:标签数据成本高,目前大部分 DGL 方法是基于监督和半监督,扩展性不足。
图数据增强可以分为:
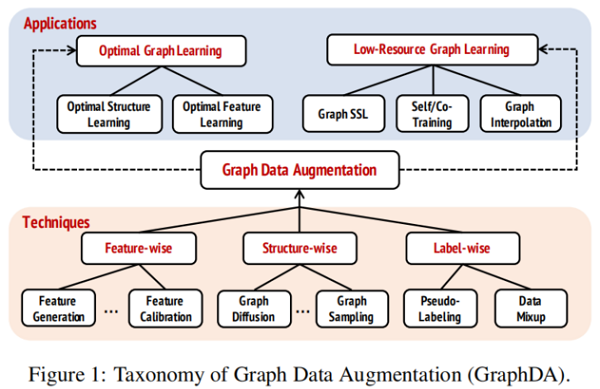
1 Techniques of Graph Data Augmentation
定义:$\mathcal{G}=(\mathbf{A}, \mathbf{X})$, $\mathbf{A} \in\{0,1\}^{n \times n}$, $\mathbf{X} \in \mathbb{R}^{n \times d}$, $\mathbf{y} \in \mathbb{R}^{n}$
GraphDA 在于找到一个映射函数 $f_{\theta}: \mathcal{G} \rightarrow \tilde{\mathcal{G}}=(\tilde{\mathbf{A}}, \tilde{\mathbf{X}})$ 来丰富图信息。
基于属性图的 GraphDA 可以分为:
-
- feature-wise
- structure-wise
- label-wise
根据优化目标可以分为:
-
- task-independent:$\underset{\theta}{\text{min }} \mathcal{L}_{a u g}\left(\left\{\mathcal{G}_{i}\right\},\left\{f_{\theta}\left(\mathcal{G}_{i}\right)\right\}\right)$
- task-dependent:$\underset{\theta, \phi}{\text{min }} \mathcal{L}_{\text {all }}\left(\left\{\mathcal{G}_{i}\right\},\left\{f_{\theta}\left(\mathcal{G}_{i}\right)\right\}, \phi\right)$
$\mathcal{L}_{a u g}(\cdot, \cdot)$, $\mathcal{L}_{a l l}(\cdot, \cdot, \cdot)$ 分别代表只对数据增强任务进行优化和联合数据增强任务及下游任务进行优化。
1.1 Feature-wise Augmentation
特征级增强策略
-
- feature generation
- feature perturbation
- feature calibration/denoising
1.1.1 Feature Generation
在所有的特征增强方法中,只有特征生成方法改变特征尺寸。
与原始特征无关,例如,将拓扑信息编码成特征,例如节点索引。之后将生成的节点特征用于下游任务或者与原有节点进行级拼接生成新的特征 $\{\tilde{\mathbf{X}}, \mathbf{X}\} $。(task-independent)
与原始特征有关(Mixup 或者 生成模型),例如,[1] 通过生成模型来增加节点特征,生成模型的输入是目标节点的局部邻域信息,并将生成器的优化归纳到公式中。(task-dependent)
1.1.2 Feature Perturbation
两个主要的策略: feature shuffling 和 feature masking。
-
-
feature shuffling :特征矩阵 $X$ 的第 $i$ 行表示第 $i$ 个节点的节点特征,因此对节点特征矩阵的行进行变换等价于得到一个具有相同拓扑但排列过的节点的备选图。由于只对节点特征进行打乱,保留拓扑结构,会导致上述两个分布之间的差异,在多视图学习中生成负样本。(task-independent )
-
feature masking :核心操作是将节点特征矩阵 $X$ 中的一部分元设置为 $0$,该思想广泛应用于对比学习。(task-independent )
-
除上述工作外,还有对抗训练的方法来扰动节点特征,该领域属于图上的对抗攻击和对抗防御,可以参考 [2]。
1.1.3 Feature Calibration/Denoising
由于图数据不可避免的存在噪声数据及感知器精度的问题,给定的节点特征对于下游任务不是最优的。
此时,出现考虑对节点特征进行较小的校准,在一定程度上存在优势,同时也保留了大部分初始节点属性。例如 [3] 计算特定目标函数的梯度和节点特征矩阵,并基于计算的梯度校准节点特征矩阵。
噪声特征的一个特例是部分特征丢失,其对应的解决方案是特征推断 [4][5]。由于难以将拓扑信息融入推断模型种,所以在图结构上还没有好好的研究,相关的代表作有 GCNMF [6] 和特征传播 [7] 。前者用高斯混合模型表示缺失的数据;后者基于热扩散方程将特征从已知特征扩散到未知特征。
1.2 Structure-wise Augmentation
分为四种方法:
-
-
edge addition/dropping
-
node addition/dropping
-
graph diffusion
-
graph sampling
-
1.2.1 Edge Addition/Dropping
即 保留原始节点顺序,对邻接矩阵种的元进行改写。
基于图稀疏性(graph sparsification)的图结构优化方法 [8、9]
1.2.2 Node Addition/Dropping
添加节点需要做:
-
- 在给定的邻接矩阵 $A$ 中插入一行和一列;
- 在给定的节点特征矩阵 $X$ 中插入一行;
- 根据特定的下游任务设置节点标签向量 $y$;
节点的更改关联图结构和节点标签往往更加复杂,一个典型的例子:通过在给定图中插入超节点来改善整个图的传播/连通性
1.2.3 Graph Diffusion
图扩散作为一种结构增强策略,图扩散通过提供底层结构的全局视图来生成增广图。图扩散通过计算权重将节点与它们的间接连接的邻居节点连接,将全局拓扑信息注入到给定的图邻接中。图扩散可以表示为:
$\mathbf{S}=\sum\limits _{k=0}^{\infty} \gamma_{k} \mathbf{T}^{k}\quad\quad\quad(2)$
-
- $\mathbf{T} \in \mathbb{R}^{N \times N}$ 是由邻接矩阵 $A$ 推导出的广义转移矩阵;
- $\theta$ 是决定全局-局部信息比率的加权系数;
- $\sum_{k=0}^{\infty} \gamma_{k}=1$,$\gamma_{k} \in[0,1]$;
- $\lambda_{i} \in[0,1]$,$\lambda_{i}$ 为 $T$ 的特征值,保证收敛;
1.2.4 Graph Sampling
图采样或者子图采样可以表示为:
$\tilde{\mathcal{G}}=\operatorname{SAMPLE}(\mathcal{G}) \quad\quad\quad(5)$
$\operatorname{SAMPLE}$ 可以是基于顶点的采样[16],基于边的采样 [17] ,遍历抽样(traversal-based sampling)[18],其他先进的方法,如Metropolis-Hastings sampling [19]。
1.2.5 Graph Generation
图生成之前与现在均是 task-independent ,代表性的工作包括 GraphRNN [20] 和 NetGAN [21],其中,前者以自回归的方式建模一个图,而后者使用 Wasserstein 生成对抗性网络目标训练一个生成器。
此外,task-dependent 的图生成也起着至关重要的作用。LDS[22]联合学习边离散概率分布和节点分类器的参数。图粗化(graph coarsening)[23] 和图凝结(graph condensation)[24] 的问题也可以归为这个领域,其目标是从初始大图生成精细的图。前者更注重寻找从原始节点到聚合节点的满射映射,后者从头开始生成压缩图。
1.3 Label-wise Augmentation
由于图上缺乏人工标注的标签,标签级增强是 GraphDA 另一个重要研究方向。可以分为两类:
-
- pseudo labeling
- data mixup
1.3.1 Pseudo-Labeling
伪标记是一种半监督学习机制,基于对未标记数据的预测,目的是获得一个(或几个)增强标记集。
在有标注数据 $D^{L}$ 上训练 Teacher Model,将模型作用于 $D^{U}$ 来生成伪标签 $D^{P}$ , 最终使用混合标签 $D^{L} \cup D^{P}$ 来训练 Student Model。在这个意义上,标签信号可以通过学习到的教师模型“传播”到未标记的数据样本。重复迭代直到通过 Teacher Model 和 Student Model 收敛。一般而言,Pseudo-Labeling 的关键是通过选择末标注数据中的哪个样 本子集 $D^{P}$ 或在每轮中重新加权 Pseudo-Labeling 实例来降低标注噪声。
深度神经网络的模型容易出错地拟合和记忆标签噪声,而置信度低的伪标签往往存在严重的标签噪声,对伪标记算法的成功有很大的威胁。一般来说,伪标记的关键是通过选择未标记数据中的样本子集 $D^{P}$ 或对每一轮中的伪标记实例进行重新加权来减轻标签噪声。
1.3.2 Data Mixup
除了利用未标记数据,还可以构造虚拟样本,称为 Mixup[25],它直接插值训练样本。
$\begin{array}{l}\tilde{\mathbf{x}}=\lambda \mathbf{x}_{i}+(1-\lambda) \mathbf{x}_{j} \\\tilde{\mathbf{y}}=\lambda \mathbf{y}_{i}+(1-\lambda) \mathbf{y}_{j}\end{array} \quad\quad\quad(6)$
其中,$\left(\mathbf{x}_{i}, \mathbf{y}_{i}\right)$ 和 $\left(\mathbf{x}_{j}, \mathbf{x}_{j}\right)$ 是从训练集中随机抽取的两个标记样本,和 $\lambda \in[0,1]$。
通过这种方式,混合方法通过结合特征向量的线性插值应该导致相关目标的线性插值来扩展训练分布。类似地,Manifold mixup[26] 对从两个训练样本中学习到的中间表示进行混合。
2 Applications of Graph Data Augmentationin Deep Graph Learning
在本节中,将回顾并讨论如何利用 GraphDA 技术来解决两个具有代表性的DGL问题,即 optimal graph learning 和 low-resourcegraph learning。
2.1 GraphDA for Optimal Graph Learning
可以分为:
-
- Optimal Structure Learning
- Optimal Feature Learning
2.1.1 Optimal Structure Learning
Optimal Structure Learning 分为三类:
- computing node similarities via metric learning (i.e., metric-basedmethods)
基于度量方法的核心思想是通过不同的度量函数估计节点相似性,代表性方法为 GAUG[27],AdaEdge[28],IDGL[29]。
GAUG[27],它基于给定的图拓扑训练一个边预测器。此外,这些度量函数可以通过下游任务的训练进行迭代更新。例如,AdaEdge[28] 基于分类结果迭代地添加或删除图拓扑中的边,并在更新的图上训练 GNNs 分类器,以克服过平滑问题。IDGL[29] 与 AdaEdge 有类似的想法,但基于学习到的节点嵌入更新了图拓扑,以增强下游模型的鲁棒性。
- optimizing adjacency matrices as learnable parameters (i.e., optimization-based methods)
通常,图拓扑的可微启发式被集成到优化目标中 [30][31][32]。例如,TO-GNN[30]采用标签平滑度,Pro-GNN[31] 采用特征平滑度和拓扑稀疏性。除了图拓扑约束,Gasoline[32]通过验证节点上的评估性能(如分类损失)的反馈更新初始图。
- learning probabilistic distributions of graph structure (i.e., probabilistic modeling methods)
概率建模方法假设图是从某些分布中采样的,并且这些分布的参数是可学习的。
例如,LDS[22] 通过采样独立的参数化的伯努利分布,并根据分类损失的反馈学习模型,对每对节点之间的边缘进行建模。由于建模每对节点的计算成本往往很高,因此一个有效的解决方案是估计现有边上的丢弃概率。 NeuralSparse [32] 和 PTDNet[33] 遵循这一策略。前者将边下降概率建模为连接到目标节点的边上的分类分布,后者将每条现有的边建模为伯努利分布。他们都基于 Gumbel-Max 技巧制定了他们的具体实例。此外,Stochastic Block Model(SBM)技术有助于表示随机图,从而实现观测图。Bayesian-GCNN[34] 和GEN [35] 都制定了基于SBM的最优图分布。前者根据观察到的初始图和相应的节点标签推断出最优SBM;后者基于根据GNNs层的隐藏表示构造的一组 kNN 图来推断出最优分布。
2.1.2 Optimal Feature Learning
与结构优化相比,图特征优化的研究还处于起步阶段。
为了处理缺失的节点特征,一种次优初始节点特征的特殊情况,特征传播 [37] 基于热扩散方程将特征从已知特征扩散到未知特征;换句话说,它用目标节点邻域的聚合特征替换缺失的节点特征。GCNMF[38] 明确地将缺失的节点特征表示为高斯混合模型,并以端到端方式学习具有下游任务的模型参数。
2.2 GraphDA for Low-Resource Graph Learning
GraphDA作为解决图数据稀缺问题最有效的解决方案之一,在以下 low-resource graph learning 领域引起了广泛关注。
2.2.1 Graph Self-Supervised Learning
近年来,数据增强技术被广泛应用于图自监督学习(SSL)中。受自动编码器思想的启发,图生成建模方法对输入图进行数据增强,然后通过从增强图中恢复特征/结构信息来学习模型。对于一个输入图,节点和/或边的特征被零或某些 token 所掩盖。然后,目标是通过 GNNs 根据未掩蔽的信息恢复掩蔽的特征/结构。
例如,GPT-GNN[39] 提出了一个自回归框架来对输入图进行重构。给定一个节点和边被随机掩蔽的图,GPT-GNN一次生成一个掩蔽节点及其边,并优化当前迭代中生成的节点和边的可能性。[40] 定义了 Graph Completion pretext,旨在根据目标节点的邻居特征和连接来恢复目标节点的掩蔽特征。Denoising Link Reconstruction [41] 随机删除现有的边以获得扰动图,并尝试使用通过交叉熵损失训练的基于成对相似度的解码器来恢复被丢弃的连接。GraphBert [42] 利用节点特征重建和图结构恢复来对图变压器模型进行预训练。
2.2.2 Graph Self/Co-Training
为了缓解数据量的问题,一个有效的解决方案是利用未标记的数据来增加稀缺的标记数据。
self-training [43] 基于有限标记数据训练的 Teacher Model 将标签归因到未标记数据上,在训练数据有限时已成为解决半监督节点分类问题的流行范式。
在这些方法中,[44] 首先结合 GCN 和 self-training 来扩大监督信号。CGCN [45] 通过将变分图自动编码器与高斯混合模型相结合来生成伪标签。此外,M3S[46]提出了多阶段的 self-training ,并利用聚类方法来消除可能不正确的伪标签。类似的观点也可以在 [47] 中找到。此外,最近的研究[48;49]也尝试解耦GNN层中的转换和传播操作,并采用标签传播作为教师模型,进一步增强伪标签的生成。
与 Self-training 类似,Co-training [50] 也被研究用未标记的数据来增强训练集。它在两个视图上分别使用初始标记数据学习两个分类器,并允许它们为彼此标记未标记数据,以增加训练数据。[51]开发了一种新的多视图半监督学习方法Co-GCN,该方法将GCN和协同训练统一到一个框架中。
2.2.3 Graph Interpolation
另一种增强训练数据的方法是使用基于插值的数据增强,如 Mixup[Zhang等人,2018]。虽然与不同于包含网格或线性序列格式的图像或自然句子不同,图具有任意的结构和拓扑,因此使用基于插值的数据增强不适用。虽然我们可以通过插值特征和相应的标签来创建额外的节点,但仍然不清楚这些新节点是如何通过合成边连接到原始节点的,从而保留整个图的结构。同时,由于图形数据的级联效应,即使是简单地从图中删除或添加一条边,也会极大地改变其语义意义。
为了解决这些挑战,GraphMix[Verma等人,2021]将流形混合[Verma等人,2019]应用于图节点分类,联合训练全连接网络和具有共享参数的GNN,用于半监督学习中的图节点分类。类似地,[Wangetal.,2021]也遵循流形混合方法,将嵌入空间中的节点和图的输入特征进行插值作为数据增强。这些方法利用一种简单的方法来避免处理输入空间中的任意结构来混合一个图对,通过混合从gnn中学习到的图表示。GraphMixup[Wuetal.,2021]通过构建语义关系空间,并使用两个基于上下文的边缘预测器进行语义级特征混合,有效地解决类不平衡节点分类任务。为了解决流形入侵的问题,[Guo和Mao,2021]提出了一种输入级混合的方法来增加图分类的训练数据。图移植[Parketal.,2022]是另一种输入级混合图增强方法,它可以在保留局部结构的同时,通过用源子图替换目标子图来混合两个不同结构的图。
扩充训练数据的另一种方法是使用基于内插的数据扩充,例如 Mixup,图上的 Mixup 有一系列代表性工作[52-56]。
3 Future Directions
3.1 Data Augmentation beyond Simple Graphs
前面提到的大多数工作都在同质图上开发的增强策略,其中边缘倾向于连接具有相同属性(如标签、特征)的节点。然而,异质性(即非协调性)也普遍存在于异性恋约会网络等网络中。许多现有的关于异亲性图的增强方法都侧重于提高给定图的协调性或降低/减少现有的非协调性边]。对异亲性图的节点特征、标签和不存在的边缘的增强仍未得到充分的研究。
此外,现有的GraphDA工作主要是为普通图或属性图开发的,而针对其他类型的图(如异构图、超图、多重图)的原则增强方法仍在很大程度上未得到探索。这些复杂的图为增强提供了更广泛的设计空间,但也对现有的GraphDA方法的有效性提出了极大的挑战,这对未来的探索至关重要。
3.2 Data Augmentation for Graph Imbalanced Training
图的数据本身是不平衡的,它遵循幂律分布。例如,在基准测试的Pubmed数据集上,节点被标记为三个类,但少数类只包含总节点的5.25%。这种不平衡的数据将导致下游任务特别是分类任务的次优性能,其中有效的解决方案之一是增加少数任务以缓解不平衡。对这个问题提出了一些初步的尝试。GraphSMOTE [57] 通过混合少数节点来增加少数节点;GraphMixup[58]构建了增强少数节点的语义关系空间。然而,关于这一主题的许多挑战仍未得到充分的探索。例如,如果少数节点的大小非常小,例如每个类的few-shot 甚至1次,那么如何从多数类转移知识来增加少数类是值得研究的。
3.3 Learnable and Generalizable Graph Augmentation
与图像不同的是,由于图形的非欧几里德性质和数据样本之间的依赖性,为图形设计有效且保留语义的数据增强技术具有挑战性。大多数图数据增强方法在输入图上采用任意增强,这可能会意外地改变图的结构和语义模式,导致性能下降[59] 。例如,扰动一个分子图的结构可能会产生一个具有完全不同性质的分子。因此,提出了必要的一个有原则的无噪声图增强函数。同时,由于不同的图具有不同的性质,因此如何使增强方法在不同的数据集上可泛化。此外,由于不同的图通常具有不同的图属性,因此在不从头学习任意图的情况下开发可推广的数据增强对于提高GraphDA方法的实际使用非常重要。
4 Conclusion
在本文中,我们提出了一个前瞻性的结构化的图形数据增强(GraphDA)。为了检查GraphDA的性质,我们给出了一个正式的公式和一个分类法,以促进理解这个新出现的研究问题。具体来说,我们根据目标增强模式将GraphDA方法分为三类,即特征增强、结构增强和标签增强。我们进一步回顾了GraphDA方法在解决两个以数据为中心的DGL问题(即最优图学习和低资源图学习)方面的应用,并讨论了流行的基于GraphDA的算法。最后,我们概述了当前的挑战以及未来在该领域的研究的机会。
Reference
1、Local augmentation for graph neural networks. arXiv , 2021.
2、Adversarial attack and defense on graph data: A survey. arXiv , 2018.
3、Graph sanitation with application to node classification. arXiv preprint arXiv 2021.
4、On the unreasonable effectiveness of feature propagation in learning on graphs with missing node features. arXiv, 2021.
5、Graph convolutional networks for graphs containing missing features. FGCS, 2021.
6、Graph convolutional networks for graphs containing missing features. FGCS, 2021
7、On the unreasonable effectiveness of feature propagation in learning on graphs with missingnode features. arXiv, 2021
8、Robust graph representation learning via neural sparsification. In ICML, 2020.
9、Learning to drop: Robust graph neural network via topological denoising. In WSDM, 2021.
10、Neural message passing for quantum chemistry. In ICML, 2017.
11、Graphsmote: Imbalanced node classification on graphs with graph neural networks. In WSDM, 2021.
12、Graph contrastive learning with augmentations. In NeurIPS,2020.
13、Graph contrastive learning automated. In ICML, 2021.
14、Graph contrastive learning with adaptive augmentation. In TheWebConf, 2021.
15、Graph information bottleneck for subgraph recognition. In ICLR, 2020.
16、Sub-graph contrast for scalable self-supervised graph representation learning. In ICDM, 2020.
17、Robust graph representation learning via neural sparsification. In ICML, 2020.
18、Graph contrastive coding for graph neural network pre-training. In KDD, 2020
19、Metropolis-hastings data augmentation for graph neural networks. NeurIPS, 2021.
20、Graphrnn: Generating realistic graphs with deep auto-regressive models. In ICML, 2018.
21、Netgan:Generating graphs via random walks. In ICML, 2018.
22、Learning discrete structures for graph neural networks. In ICML, 2019.
23、Graph coarsening with neural networks. In ICLR, 2021.
24、Graph condensation for graph neural networks
25、mixup: Beyond empirical risk minimization. In ICLR, 2018.
26、Manifold mixup: Better representations by interpolating hidden states. In ICML, 2019.
27、Data augmentation for graph neural networks. In AAAI, 2021.
28、Measuring and relieving the over-smoothing problem for graph neural networks from the topological view. In AAAI, 2020.
29、Iterative deep graph learning for graph neural networks: Better and robust node embeddings. NeurIPS, 2020.
30、Topology optimization based graph convolutional network. In IJCAI, 2019.
31、Graph structure learning for robust graph neural networks. In KDD, 2020.
32、 Robust graph representation learning via neural sparsification. In ICML, 2020.
33、Learning to drop: Robust graph neural network via topological denoising. In WSDM, 2021.
34、Bayesian graph convolutional neural networks for semi-supervised classification. In AAAI, 2019.
35、Graph sparsification via meta-learning. DLG@AAAI,2021.
36、Graph neural networks with adaptive residual. NeurIPS, 2021.
37、On the unreasonable effectiveness of feature propagation in learning on graphs with missing node features
38、Graph convolutional networks for graphs containing missing features. FGCS, 2021.
39、Gpt-gnn: Generative pre-training of graph neural networks. In KDD, 2020.
40、When does self-supervision help graph convolutional networks? In ICML, 2020.
41、Pre-training graph neural networks for generic structural feature extraction. arXiv, 2019.
42、Graph-bert: Only attention is needed for learning graph representations. arXiv preprint arXiv:, 2020.
43、Unsupervised word sense disambiguation rivaling supervised methods. In ACL, 1995.
44、Deeper insights into graph convolutional networks for semi-supervised learning. In AAAI, 2018.
45、Collaborative graph convolutional networks: Unsupervised learning meets semi-supervised learning. In AAAI, 2020.
46、Multi-stage self-supervised learning for graph convolutional networks on graphs with few labeled nodes. In AAAI, 2020.
47、Nrgnn: Learning a label noise-resistant graph neural network on sparsely and noisily labeled graphs. In KDD, 2021.
48、 On the equivalence of decoupled graph convolution network and label propagation. In TheWebConf, 2021.
49、Meta propagation networks for graph few-shot semi-supervised learning. In AAAI, 2022.
50、Combining labeled and unlabeled data with co-training. In COLT, 1998.
51、Co-gcn for multi-view semi-supervised learning. In AAAI, 2020.
52、Graphmix: Improved training of gnns for semi-supervised learning. In AAAI, 2021.
53、Mixup for node and graph classification. In TheWebConf, 2021.
54、Graphmixup: Improving class-imbalanced node classification on graphs by self-supervised context prediction. arXiv preprint arXiv, 2021.
55、Intrusion-free graph mixup. arXiv preprint arXiv:2110.09344, 2021.
56、Graph transplant: Node saliency-guided graph mixup with local structure preservation. In AAAI, 2022.
57、Graphsmote: Imbalanced node classification on graphs with graph neural networks. In WSDM, 2021.
58、Graphmixup: Improving class-imbalanced node classification on graphs by self-supervised context prediction. arXiv preprint arXiv, 2021.
59、Metropolis-hastings data augmentation for graph neural networks. NeurIPS, 2021.
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16327211.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号