论文解读(MERIT)《Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning》
论文信息
论文标题:Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning
论文作者:Ming Jin, Yizhen Zheng, Yuan-Fang Li, Chen Gong, Chuan Zhou, Shirui Pan
论文来源:2021, IJCAI
论文地址:download
论文代码:download
1 Introduction
创新:融合交叉视图对比和交叉网络对比。
2 Method
算法图示如下:
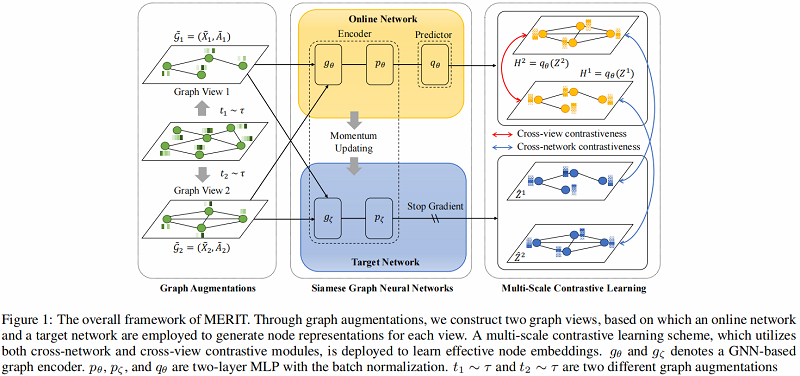
模型组成部分:
-
- Graph augmentations
- Cross-network contrastive learning
- Cross-view contrastive learning
2.1 Graph Augmentations
- Graph Diffusion (GD)
$S=\sum\limits _{k=0}^{\infty} \theta_{k} T^{k} \in \mathbb{R}^{N \times N}\quad\quad\quad(1)$
这里采用 PPR kernel:
$S=\alpha\left(I-(1-\alpha) D^{-1 / 2} A D^{-1 / 2}\right)^{-1}\quad\quad\quad(2)$
- Edge Modification (EM)
给定修改比例 $P$ ,先随机删除 $P/2$ 的边,再随机添加$P/2$ 的边。(添加和删除服从均匀分布)
- Subsampling (SS)
在邻接矩阵中随机选择一个节点索引作为分割点,然后使用它对原始图进行裁剪,创建一个固定大小的子图作为增广图视图。
- Node Feature Masking (NFM)
给定特征矩阵 $X$ 和增强比 $P$,我们在 $X$ 中随机选择节点特征维数的 $P$ 部分,然后用 $0$ 掩码它们。
在本文中,将 SS、EM 和 NFM 应用于第一个视图,并将 SS+GD+NFM 应用于第二个视图。
2.2 Cross-Network Contrastive Learning
MERIT 引入了一个孪生网络架构,它由两个相同的编码器(即 $g_{\theta}$, $p_{\theta}$, $g_{\zeta}$ 和 $p_{\zeta}$)组成,在 online encoder 上有一个额外的预测器$q_{\theta}$,如 Figure 1 所示。
这种对比性的学习过程如 Figure 2(a) 所示:

其中:
-
- $H^{1}=q_{\theta}\left(Z^{1}\right)$
- $Z^{1}=p_{\theta}\left(g_{\theta}\left(\tilde{X}_{1}, \tilde{A}_{1}\right)\right)$
- $Z^{2}=p_{\theta}\left(g_{\theta}\left(\tilde{X}_{2}, \tilde{A}_{2}\right)\right)$
- $\hat{Z}^{1}=p_{\zeta}\left(g_{\zeta}\left(\tilde{X}_{1}, \tilde{A}_{1}\right)\right)$
- $\hat{Z}^{2}=p_{\zeta}\left(g_{\zeta}\left(\tilde{X}_{2}, \tilde{A}_{2}\right)\right)$
参数更新策略(动量更新机制):
$\zeta^{t}=m \cdot \zeta^{t-1}+(1-m) \cdot \theta^{t}\quad\quad\quad(3)$
其中,$m$、$\zeta$、$\theta$ 分别为动量参数、target network 参数和 online network 参数。
损失函数如下:
$\mathcal{L}_{c n}=\frac{1}{2 N} \sum\limits _{i=1}^{N}\left(\mathcal{L}_{c n}^{1}\left(v_{i}\right)+\mathcal{L}_{c n}^{2}\left(v_{i}\right)\right)\quad\quad\quad(6)$
其中:
$\mathcal{L}_{c n}^{1}\left(v_{i}\right)=-\log {\large \frac{\exp \left(\operatorname{sim}\left(h_{v_{i}}^{1}, \hat{z}_{v_{i}}^{2}\right)\right)}{\sum_{j=1}^{N} \exp \left(\operatorname{sim}\left(h_{v_{i}}^{1}, \hat{z}_{v_{j}}^{2}\right)\right)}}\quad\quad\quad(4) $
$\mathcal{L}_{c n}^{2}\left(v_{i}\right)=-\log {\large \frac{\exp \left(\operatorname{sim}\left(h_{v_{i}}^{2}, \hat{z}_{v_{i}}^{1}\right)\right)}{\sum_{j=1}^{N} \exp \left(\operatorname{sim}\left(h_{v_{i}}^{2}, \hat{z}_{v_{j}}^{1}\right)\right)}}\quad\quad\quad(5) $
2.3 Cross-View Contrastive Learning
损失函数:
$\mathcal{L}_{c v}^{k}\left(v_{i}\right)=\mathcal{L}_{\text {intra }}^{k}\left(v_{i}\right)+\mathcal{L}_{\text {inter }}^{k}\left(v_{i}\right), \quad k \in\{1,2\}\quad\quad\quad(10)$
其中:
$\mathcal{L}_{c v}=\frac{1}{2 N} \sum\limits _{i=1}^{N}\left(\mathcal{L}_{c v}^{1}\left(v_{i}\right)+\mathcal{L}_{c v}^{2}\left(v_{i}\right)\right)\quad\quad\quad(9)$
$\mathcal{L}_{\text {inter }}^{1}\left(v_{i}\right)=-\log {\large \frac{\exp \left(\operatorname{sim}\left(h_{v_{i}}^{1}, h_{v_{i}}^{2}\right)\right)}{\sum_{j=1}^{N} \exp \left(\operatorname{sim}\left(h_{v_{i}}^{1}, h_{v_{j}}^{2}\right)\right)}}\quad\quad\quad(7) $
$\begin{aligned}\mathcal{L}_{i n t r a}^{1}\left(v_{i}\right) &=-\log \frac{\exp \left(\operatorname{sim}\left(h_{v_{i}}^{1}, h_{v_{i}}^{2}\right)\right)}{\exp \left(\operatorname{sim}\left(h_{v_{i}}^{1}, h_{v_{i}}^{2}\right)\right)+\Phi} \\\Phi &=\sum\limits_{j=1}^{N} \mathbb{1}_{i \neq j} \exp \left(\operatorname{sim}\left(h_{v_{i}}^{1}, h_{v_{j}}^{1}\right)\right)\end{aligned}\quad\quad\quad(8)$
2.4 Model Training
$\mathcal{L}=\beta \mathcal{L}_{c v}+(1-\beta) \mathcal{L}_{c n}\quad\quad\quad(11)$
3 Experiment
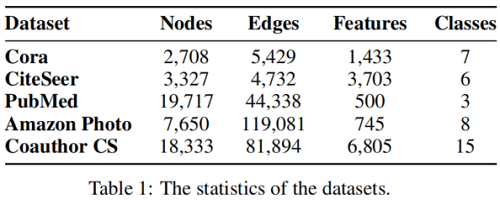
数据集
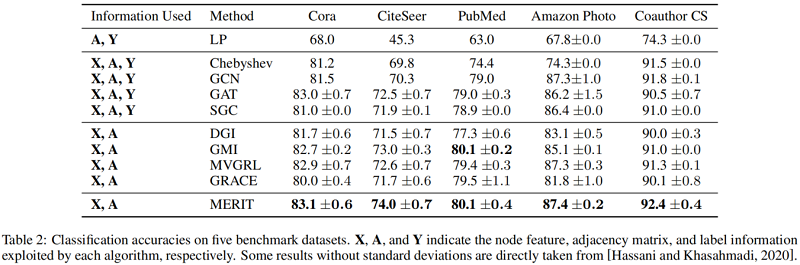
基线实验
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/16196841.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号