手动实现前馈神经网络解决 二分类 任务
1 导入实验需要的包
import numpy as np
import torch
from torch import nn
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from torch.utils.data import TensorDataset,DataLoader
2 创建数据
num_example,num_input = 10000,200
x1 = torch.normal(-2,1,size = (num_example,num_input))
y1 = torch.ones((num_example,1))
x2 = torch.normal(2,1,size = (num_example,num_input))
y2 = torch.zeros((num_example,1))
x = torch.cat((x1,x2),dim = 0)
y = torch.cat((y1,y2),dim = 0)
train_x,test_x,train_y,test_y =train_test_split(x,y,shuffle = True,stratify = y,random_state= 1,test_size=0.3)
print(train_x.shape)
print(test_x.shape)
3 加载数据
batch_size = 50
train_dataset = TensorDataset(train_x,train_y)
train_iter = DataLoader(
dataset = train_dataset,
shuffle = True,
batch_size = batch_size,
num_workers = 0
)
test_dataset = TensorDataset(test_x,test_y)
test_iter = DataLoader(
dataset = test_dataset,
shuffle = True,
batch_size = batch_size,
num_workers = 0
)
# print(np.unique(y))
# np.sum([ele.data==1 for ele in train_y.flatten() ])
# np.sum([ele.data==0 for ele in train_y.flatten() ])
4 初始化参数
num_hidden,num_output = 256,1
torch.set_default_tensor_type = torch.float32
# w1 = torch.tensor(torch.normal(0,0.001,size = (num_hidden,num_input))).type(torch.float32)
w1 = torch.tensor(torch.normal(0,0.001,size = (num_hidden,num_input))).type(torch.FloatTensor)
b1 = torch.ones(1)
# b1 = torch.ones(1,dtype = torch.float32)
print(w1.dtype)
print(b1.dtype)
w2 = torch.tensor(torch.normal(0,0.001,size = (num_output,num_hidden)),dtype = torch.float32)
b2 = torch.ones(1)
params = [w1,w2,b1,b2]
for param in params:
param.requires_grad_(requires_grad=True)
5 定义激活函数、模型、优化器、损失函数
def ReLU(x):
return torch.max(x,other = torch.tensor(0.0))
loss = nn.BCEWithLogitsLoss()
# loss = nn.BCELoss()
def net(x):
H1 = ReLU(torch.matmul(x,w1.t())+b1)
H2 = torch.matmul(H1,w2.t())+b2
return H2
def SGD(params,lr):
param.data -= lr*param.grad/batch_size
6 定义训练模型
def train(net ,train_iter,test_iter,lr,num_epochs,params):
train_l,test_l = [],[]
for epoch in range(num_epochs):
train_l_sum,n = 0,0
for x,y in train_iter:
n += y.shape[0]
y_pred = net(x)
l = loss(y_pred,y)
train_l_sum += l.item()
if params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_()
l.backward()
SGD(params,lr)
train_l.append(train_l_sum/n)
test_l_sum,n = 0,0
for x,y in test_iter:
n += y.shape[0]
y_pred = net(x)
l = loss(y_pred,y)
test_l_sum += l.item()
test_l.append(test_l_sum/n)
print('epoch %d, train_loss %.6f,test_loss %.6f'%(epoch+1, train_l[epoch],test_l[epoch]))
return train_l,test_l
7 训练
lr,num_epochs = 0.01,100
train_loss,test_loss =train(net ,train_iter,test_iter,lr,num_epochs,params)
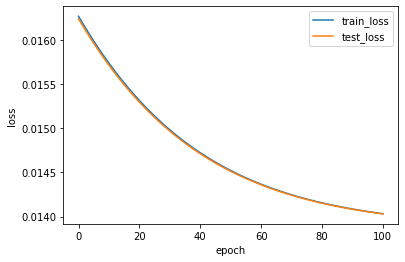
8 可视化
x = np.linspace(0,len(train_loss),len(train_loss))
plt.plot(x,train_loss,label="train_loss",linewidth=1.5)
plt.plot(x,test_loss,label="test_loss",linewidth=1.5)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend()
plt.show()
因上求缘,果上努力~~~~ 作者:图神经网络,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/15971254.html

