论文解读(DAEGC)《Attributed Graph Clustering: A Deep Attentional Embedding Approach》
论文信息
论文标题:Attributed Graph Clustering: A Deep Attentional Embedding Approach
论文作者:Chun Wang, Shirui Pan, Ruiqi Hu, Guodong Long, Jing Jiang, Chengqi Zhang
论文来源:2019, IJCAI
论文地址:download
论文代码:download
1 Introduction
研究现状:目前的图表示学习方法都是两阶段方法,且融合结构和属性信息的机制并不完美。
本文模型与传统的 $\text{two-step}$ 方法的比较如 Figure 1 所示:
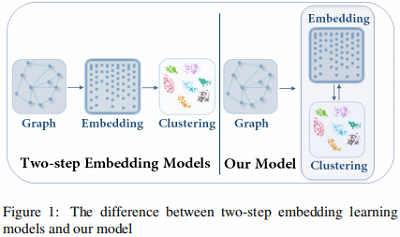
- 本文模型是将 节点表示 和 聚类 放在一个统一的框架中学习。
- $\text{Two-step}$ 方法则是先学习 $\text{node embedding}$,然后进行聚类。
2 Method
总体框架:
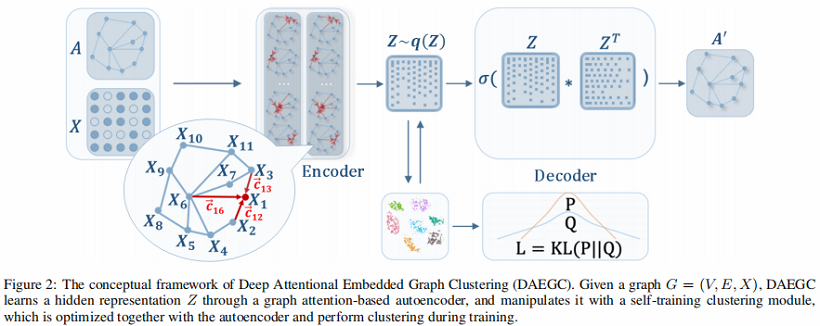
组成部分:
-
- Graph Attentional Autoencoder
- Self-training Clustering
2.1 Graph Attentional Autoencoder
2.1.1 GAT encoder
首先:衡量 $\text{node}$ $i$ 的邻居 $N_i$ 对于节点 $i$ 的影响,采用图注意力机制:
$z_{i}^{l+1}=\sigma\left(\sum\limits _{j \in N_{i}} \alpha_{i j} W z_{j}^{l}\right)\quad\quad\quad(1)$
其中:$\alpha_{i j}$ is the attention coefficient that indicates the importance of neighbor node $j$ to node $i$ ;
对于注意力系数 $\alpha_{i j}$ 主要参考两个方面:
- 属性值(attribute values) ;
- 拓扑距离( topological distance );
Aspact 1:属性值
注意力系数 $\alpha_{i j}$ 可以表示为 由 $x_i$ 和 $x_j$ 拼接形成的单层前馈神经网络:
$c_{i j}=\vec{a}^{T}\left[W x_{i} \| W x_{j}\right]\quad \quad \quad(2)$
其中:
-
- $\vec{a} \in R^{2 m^{\prime}}$ 是权重向量;
Aspact 2:拓扑距离
考虑节点高阶邻居信息(指 $ \text{t-order} $ 邻居),得到 $\text{proximity matrix} $ :
$M=\left(B+B^{2}+\cdots+B^{t}\right) / t\quad \quad\quad(3)$
其中:
-
- $B$ 是转移矩阵(transition matrix),当 $e_{i j} \in E$ 有边相连,那么 $B_{i j}=1 / d_{i}$ ,否则 $B_{i j}=0$ 。
- $M_{i j}$ 表示 $\text{node}$ $i$ 和 $\text{node}$ $j$ 的 $t$ 阶内的拓扑相关性。如果 $\text{node}$ $i$ 和 $\text{node}$ $j$ 存在邻居关系($t$ 阶之内),那么 $M_{i j}>0 $。
对节点 $i$ 的领域做标准化,采用 $\text{softmax function}$ :
${\large \alpha_{i j}=\operatorname{softmax}_{j}\left(c_{i j}\right)=\frac{\exp \left(c_{i j}\right)}{\sum_{r \in N_{i}} \exp \left(c_{i r}\right)}} \quad \quad \quad(4)$
将 $\text{Eq.2}$ 中 $c_{ij}$ 及 $\text{Eq.3}$ 中的 $M_{ij}$ 带入 $\text{Eq.4}$,那么 $\text{attention}$ 系数可以表示为:
${\large \alpha_{i j}=\frac{\exp \left(\delta M_{i j}\left(\vec{a}^{T}\left[W x_{i} \| W x_{j}\right]\right)\right)}{\sum_{r \in N_{i}} \exp \left(\delta M_{i r}\left(\vec{a}^{T}\left[W x_{i} \| W x_{r}\right]\right)\right)}} \quad\quad\quad(5)$
其中,激活函数 $\delta$ 采用 $LeakyReLU$ ;
本文堆叠 $2$ 个 $\text{graph attention layers}$ :
$z_{i}^{(1)}=\sigma\left(\sum \limits _{j \in N_{i}} \alpha_{i j} W^{(0)} x_{j}\right)\quad \quad \quad (6)$
$z_{i}^{(2)}=\sigma\left(\sum\limits _{j \in N_{i}} \alpha_{i j} W^{(1)} z_{j}^{(1)}\right)\quad \quad\quad(7)$
通过上述图注意力编码器,得到最终的 $z_{i}=z_{i}^{(2)}$ 。
2.1.2 Inner product decoder
解码器为 $\text{Inner product decoder}$ ,用于重构图:
其中:
-
- $\hat{A}$ 是重建后的图结构矩阵;
2.1.3 Reconstruction loss
最小化 $A$ 和 $\hat{A}$ 的重构错误:
$L_{r}=\sum\limits _{i=1}^{n} \operatorname{loss}\left(A_{i, j}, \hat{A}_{i j}\right)\quad\quad \quad (9)$
2.2 Self-optimizing Embedding
除优化重构误差外,还将 隐表示 输入一个自优化聚类模块,该模块最小化以下目标:
$L_{c}=K L(P \| Q)=\sum\limits_{i} \sum\limits _{u} p_{i u} \log \frac{p_{i u}}{q_{i u}}\quad\quad\quad(10)$
其中:
-
- $q_{iu}$度量隐表示 $z_{i}$ 和聚类中心 $\mu_{u}$ 之间的相似性,本文通过 Student's t-distribution 度量;
- $p_{iu}$ 代表目标分布;
${\large q_{i u}=\frac{\left(1+\left\|z_{i}-\mu_{u}\right\|^{2}\right)^{-1}}{\sum\limits _{k}\left(1+\left\|z_{i}-\mu_{k}\right\|^{2}\right)^{-1}}} \quad\quad\quad(11)$
${\large p_{i u}=\frac{q_{i u}^{2} / \sum_{i} q_{i u}}{\sum_{k}\left(q_{i k}^{2} / \sum_{i} q_{i k}\right)}}\quad \quad\quad(12) $
聚类损失迫使当前分布 $Q$ 接近目标分布 $P$。
算法概述
-
- 首先使用没有用 selfoptimize clustering part 的自编码器获得初始 embedding ;
- 其次为计算 Eq.11 ,先使用 $k-means$ 获得初始聚类中心 $\mu$
- 然后根据 $L_c$ 使用 SGD 进行优化更新 $\mu$ 和 $z$ 。
需要注意的是 :$P$ 每 $5$ 个 iteration 更新一次,$Q$ 每个 iteration 更新一次。
算法步骤:

2.3 Joint Embedding and Clustering Optimization
联合优化 自编码器的重构损失 和 聚类损失,总目标函数为:
$L=L_{r}+\gamma L_{c}\quad \quad\quad (13)$
其中:
-
- $L_{r}$ 代表着重构损失;
- $L_{c} $ 代表着聚类损失 ;
最终 $v_{i}$ 的 软标签 通过 $Q$ 获得:
$s_{i}=\arg \underset{u}{\text{max}} \; q_{i u}\quad \quad\quad(14)$
3 Experiments
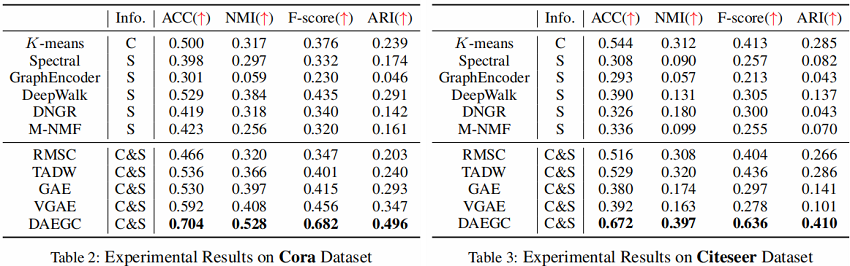
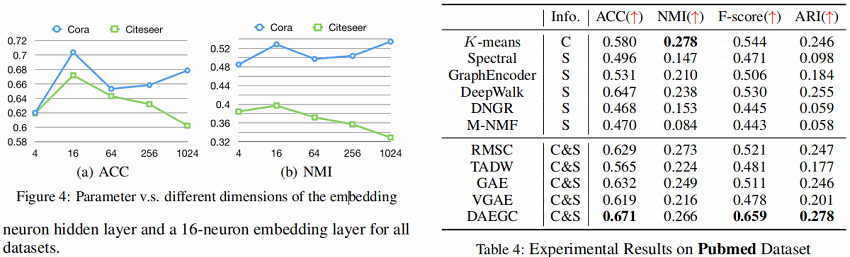

4 Conclusion
贡献:
- 使用考虑了长距离结构信息图注意力网络的编码器;
- 采用内积重构邻接矩阵做;
修改历史
2022-02-19 创建文章
2022-06-09 修订文章
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/15908418.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号