稀疏编码器
提出思路
自编码器最初提出是基于降维的思想,但是当隐层节点比输入节点多时,自编码器就会失去自动学习样本特征的能力,此时就需要对隐层节点进行一定的约束,与降噪自编码器的出发点一样,高维而稀疏的表达是好的,因此提出对隐层节点进行一些稀疏性的限值。稀疏自编码器就是在传统自编码器的基础上通过增加一些稀疏性约束得到的。这个稀疏性是针对自编码器的隐层神经元而言的,通过对隐层神经元的大部分输出进行抑制使网络达到一个稀疏的效果。
算法原理
假设我们只有一个没有带类别标签的训练样本集合 $\left\{x^{(1)}, x^{(2)}, x^{(3)}, \ldots\right\} $ ,其中 $x^{(i)} \in \Re^{n} $ 。自编码神经网络是一种无监督学习算法,它使用了反向传播算法,并让目 标值等于输入值,比如 $y^{(i)}=x^{(i)}$ 。下图是一个自编码神经网络 (图一) 的示例。
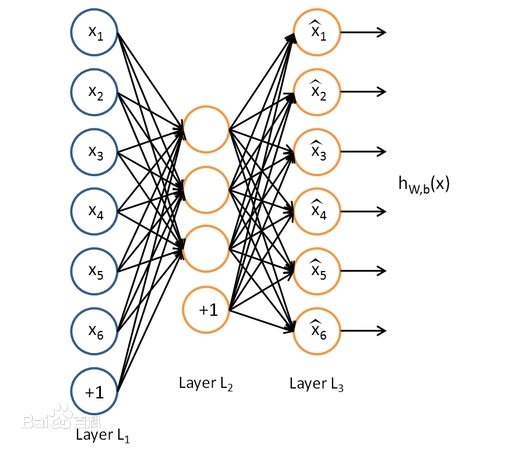
自编码神经网络尝试学习一个 $h_{W, b}(x) \approx x$ 的函数。换句话说,它尝试逼近一个恒 等函数,从而使得输出 $\hat{x}$ 接近于输入 $x$ 。恒等函数虽然看上去不太有学习的意义,但是当 我们为自编码神经网络加入某些限制,比如限定隐藏神经元的数量,我们就可以从输入数 据中发现一些有趣的结构。举例来说,假设某个自编码神经网络的输入 $x$ 是一张 $10 \times 10$ 图像 (共100个像素) 的像素灰度值,于是 $n=100$ ,其隐藏层 $L_{2}$ 中有 50 个隐 藏神经元。注意,输出也是 100 维的 $y \in \mathfrak{R}^{100}$ 。由于只有 50 个隐藏神经元,我们迫使自 编码神经网络去学习输入数据的"'压缩"'表示,也就是说,它必须从50维的隐藏神经元激活度向量 $a^{(2)} \in \Re^{50} $ 中"'重构"'出 100 维的像素灰度值输入 $x$ 。如果网络的输入数据是完全随机的,比如每一个输入 $x_{i} $ 都是一个 跟其它特征完全无关的独立同分布高斯随机变量,那么这一压缩表示将会非常难学习。但是如果输入数据中隐含着一些特定的结 构,比如某些输入特征是彼此相关的,那么这一算法就可以发现输入数据中的这些相关性。事实上,这一简单的自编码神经网络 通常可以学习出一个跟主元分析 (PCA) 结果非常相似的输入数据的低维表示。
注意到 $a_{j}^{(2)}$ 表示隐藏神经元 $j$ 的激活度,但是这一表示方法中并末明确指出哪一个输入 $x$ 带来了这一激活度。所以我们将使 用 $a_{j}^{(2)}(x) $ 来表示在给定输入为 $x $ 情况下,自编码神经网络隐藏神经元 $j$ 的激活度。
进一步,让
$\hat{\rho}_{j}=\frac{1}{m} \sum_{i=1}^{m}\left[a_{j}^{(2)}\left(x^{(i)}\right)\right]$
表示隐藏神经元 $j$ 的平均活跃度 (在训练集上取平均)。我们可以近似的加入一条限制
$\hat{\rho}_{j}=\rho$
这里, $s_{2} $ 是隐藏层中隐藏神经元的数量,而索引 $j $ 依次代表隐藏层中的每一个神经元。如果你对相对樀 ( $KL divergence $ ) 比较熟悉,这一玨罚因子实际上是基于它的。于是惩罚因子也可以被表示为
$\sum \limits_{j=1}^{s_{2}} \mathrm{KL}(\rho \| \hat{\rho}_{j})$
其中 $\mathrm{KL}\left(\rho \| \hat{\rho}_{j}\right)=\rho \log \frac{\rho}{\hat{\rho}_{j}}+(1-\rho) \log \frac{1-\rho}{1-\hat{\rho}_{j}}$ 是一个以 $\rho$ 为均值和一个以 $\hat{\rho}_{j}$ 为均值的两个伯努利随机变量之间的相对 樀。相对樀是一种标准的用来测量两个分布之间差异的方法。(如果你没有见过相对熵,不用担心,所有你需要知道的内容都会 被包含在这份笔记之中。)
这一惩罚因子有如下性质,当 $\hat{\rho}_{j}=\rho 时 \mathrm{KL}\left(\rho \| \hat{\rho}_{j}\right)=0$ ,并且随着 $ \hat{\rho}_{j}$ 与 $\rho $ 之间的 差异增大而单调递增。举例来说,在图二中,我们设定 $ \rho=0.2$ 并且画出了相对熵值 $ \mathrm{KL}\left(\rho \| \hat{\rho}_{j}\right)$ 随着 $\hat{\rho}_{j} $ 变化的变化 (图二)。
我们可以看出,相对熵在 $\hat{\rho}_{j}=\rho$ 时达到它的最小值 $ 0$ ,而当 $\hat{\rho}_{j}$ 靠近 $0 $ 或者 $1$ 的时候, 相对熵则变得非常大 (其实是趋向于 $\infty$ )。所以,最小化这一惩罚因子具有使得 $\hat{\rho}_{j}$ 靠近 $\rho$ 的效果。
我们的总体代价函数可以表示为
$J_{\text {sparse }}(W, b)=J(W, b)+\beta \sum_{j=1}^{s_{2}} \mathrm{KL}\left(\rho \| \hat{\rho}_{j}\right)$
其中 $J(W, b)$ 如之前所定义,而 $ \beta$ 控制稀旈性晸罚因子的权重。 $\hat{\rho}_{j} $ 项则也 (间接地) 取决于 $ W, b$ ,因为它是隐藏神经元 $j$ 的平均激活度,而隐藏层神经元的激活度取决于 $W, b$ 。
为了对相对樀进行导数计算,我们可以使用一个易于实现的技巧,这只需要在你的程序中稍作改动即可。具体来说,前面在 后向传播算法中计算第二层 $(l=2)$ 更新的时候我们已经计算了
$\delta_{i}^{(2)}=\left(\sum_{j=1}^{s_{2}} W_{j i}^{(2)} \delta_{j}^{(3)}\right) f^{\prime}\left(z_{i}^{(2)}\right)$
我们将其换成
$\delta_{i}^{(2)}=\left(\left(\sum_{j=1}^{s_{2}} W_{j i}^{(2)} \delta_{j}^{(3)}\right)+\beta\left(-\frac{\rho}{\hat{\rho}_{i}}+\frac{1-\rho}{1-\hat{\rho}_{i}}\right)\right) f^{\prime}\left(z_{i}^{(2)}\right)$
就可以了。
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/15717423.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号