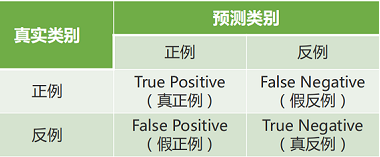
性能度量
-
-
- 错误率:分错样本占样本总数的比例
- 精度:分对样本占样本总数的比率
-

准确率 (Accuracy )
$ACC = \frac{T P+T N}{T P+T N+F P+F N}$
预测正确的结果占总样本的百分比
y_pred = [0, 2, 1, 2]
y_true = [0, 1, 2, 3]
print(accuracy_score(y_true, y_pred)) # 0.25
4个样本,就第一个预测正确,所以准确率为 0.25。
查准率 ( Precision )
$ P= \frac{T P}{TP+F P}$
即:对每一类 (好瓜)/(好瓜加坏瓜)
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
对于第 0 类,y_true 两个 0,y_pred 三个 0, y_pred 三 个 0 都预测正确 2 个,所以查准率为2/3;
对于第 1 类,y_true 两个 1,y_pred 两个 1, y_pred 两 个 1 都预测错误,所以查准率为0;
对于第 2 类,y_true 两个 2,y_pred 一个 2, y_pred 一 个 2 都预测错误,所以查准率为0;
查全率/召回率/敏感度 ( Recall/Sensitivity )
$\frac{T P}{T P+F N} $
-
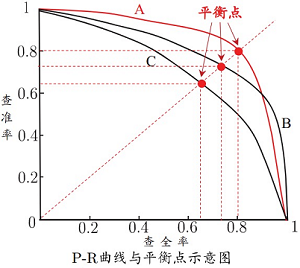
- 若一个学习算法的PR曲线被另一个学习算法的曲线完全“包住”,则可认为后者的性能优于前者,如A优于C;
- 若两个学习算法的PR曲线发生交叉(如A和B),则难以判断孰优孰劣,只能在具体的查准率和查全率条件下进行比较;
- 可通过比较P-R曲线下的面积(PR-AUC)
- 利用平衡点(即P=R时的取值)
- 利用F1度量
$ \beta=1$: 标准F1
$\beta>1 $: 偏重查全率(逃犯信息检索)
$ \beta<1$ : 偏重查准率(商品推荐系统)
是先对每一个类统计指标值,然后在对所有类求算术平均值。
$\begin{aligned}macro-P &=\frac{1}{n} \sum \limits _{i=1}^{n} P_{i} \\macro -R &=\frac{1}{n} \sum \limits _{i=1}^{n} R_{i} \\macro -F1 &=\frac{2 \times macro-P \times macro-R}{macro-P+macro-R}\end{aligned}$
-
-
- l Macro-averaged gives equal weight to each class
- l Micro-averaged gives equal weight to each per-instance classification decision
- l Macro-averaging is a good choice when you get a sense of effectiveness on small classes
- l Micro-averaging is a good choice on the large classes because large classes dominate small classes in micro-averaging
- l Macro-averaging evaluates the system performance overall across the sets of data, can not get any specific decision with it
- l Micro-average can be a useful measure when the dataset varies in size
-
真正率 (TPR ) = 灵敏度/召回率 = $\mathrm{TP} /(\mathrm{TP}+\mathrm{FN}) $ 正例中有多少样本被检测出
假正率 (FPR ) = 1- 特异度 = $\mathrm{FP} /(\mathrm{FP}+\mathrm{TN}) $ 负例中有多少样本被错误覆盖


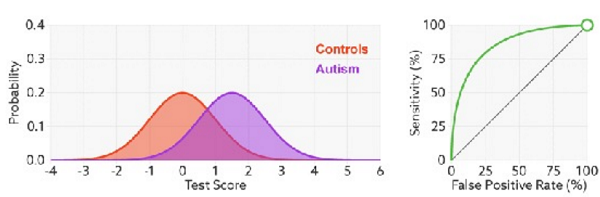
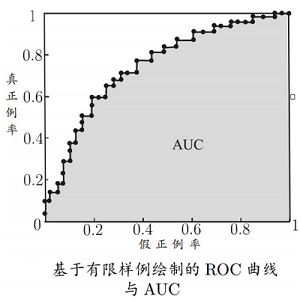
假设ROC曲线由 $\left\{\left(x_{i}, y_{i}\right)\right\}_{i=1}^{m}$ 的点按序连接而 形成 $\left(x_{1}=0, x_{m}=1\right)$ 则 $A \cup C$ 可估算为 :
$\mathrm{AUC}=\frac{1}{2} \sum_{i=1}^{m-1}\left(x_{i+1}-x_{i}\right) \cdot\left(y_{i}+y_{i+1}\right)$
AUC衡量了样本预测的排序质量。
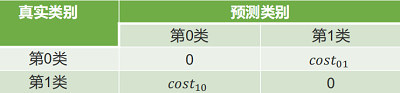
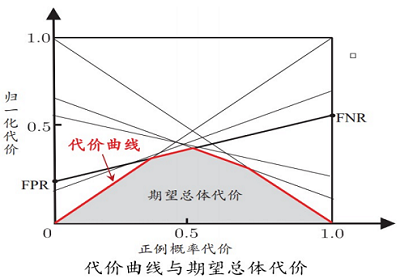
在非均等代价下,不再最小化错误次数,而是最小化“总体代价”,则“代价敏感”错误率相应的为:
$P(+) \operatorname{cost}=\frac{p \times \cos t_{01}}{p \times \operatorname{cost}_{01}+(1-p) \times \operatorname{cost}_{10}}$
纵轴是取值为 $[0,1] $ 的归一化代价
$\operatorname{cost}_{n o r m}=\frac{\text { FNR } \times p \times \operatorname{cost}_{01}+\text { FPR } \times(1-p) \times \operatorname{cost}_{10}}{p \times \operatorname{cost}_{01}+(1-p) \times \operatorname{cost}_{10}}$

因上求缘,果上努力~~~~ 作者:图神经网络,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/15632673.html

