论文解读(LLE)《Nonlinear Dimensionality Reduction by Locally Linear Embedding》以及论文通俗解释
论文题目:《Nonlinear Dimensionality Reduction by Locally Linear Embedding 》
发表时间:Science 2000
论文地址:Download
tips:原论文:一篇report ,解释的不够清楚,博主查阅众多资料,以及参考交大于剑老师教材总结。
简介
局部线性嵌入(Locally Linear Embedding,简称LLE)重要的降维方法。
传统的 PCA,LDA 等方法是关注样本方差的降维方法,LLE 关注于降维时保持样本局部的线性特征,由于LLE在降维时保持了样本的局部特征,所以广泛用于图像图像识别,高维数据可视化等领域。
流形学习
LLE 是流形学习(Manifold Learning)的一种。
流形学习是一大类基于流形的框架。我们可以认为 LLE 中的流形是一个不闭合的曲面,且流形曲面数据分布比较均匀,比较稠密。LLE 算法是将流形从高维到低维的降维过程,在降维过程希望流形在高维的一些特征可以得到保留。
一个形象的流形降维过程如下图。我们有一块卷起来的布,我们希望将其展开到一个二维平面,我们希望展开后的布能够在局部保持布结构的特征,其实也就是将其展开的过程,就想两个人将其拉开一样。
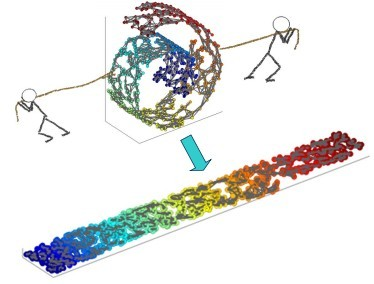
对于降维问题,以前的方法是基于多维标度(MDS),计算试图保持数据点之间的 成对距离 或 广义差异的嵌入,这些距离是沿着直线测量的,在更具权威性的 MDS 用法中,如 Isomap,沿着限制于观测数据的流形表示的最短路径。如等距映射(ISOMAP)算法希望在降维后保持样本之间的测地距离而不是欧式距离,因为测地距离更能反映样本之间在流形中的真实距离。
在这里,我们采用一种不同的方法,称为局部线性嵌入(LLE),这种方法不需要估计广泛分离的数据点之间的成对距离。

等距映射(ISOMAP)算法需要找所有样本全局最优解,当数据量很大,样本维度很高时,计算非常的耗时,鉴于这个问题,LLE 通过放弃所有样本全局最优的降维,只是通过保证局部最优来降维。同时假设样本集在局部是满足线性关系的,进一步减少的降维的计算量。
LLE算法思想
LLE 假设数据在较小局部是线性的,即:某一数据可由它邻域中几个样本线性表示。如有一个样本$x_1$,我们在它原始高维邻域里用 KNN 思想找到和它最近的三个样本 $x_2,x_3,x_4$,然后假设$x_1$可以由 $x_2,x_3,x_4$ 线性表示,即:
$x_{1}=w_{12} x_{2}+w_{13} x_{3}+w_{14} x_{4}$
其中,$w_{12}, w_{13}, w_{14}$为权重系数。在通过 LLE 降维后,我们希望 $x_1$ 在低维空间对应的投影 $x_1'$ 以及 $x_2,x_3,x_4$ 对应的投影 $x_2',x_3',x_4'$ 也尽量保持线性关系,即
$x_{1}^{\prime} \approx w_{12} x_{2}^{\prime}+w_{13} x_{3}^{\prime}+w_{14} x_{4}^{\prime}$
我们希望投影前后线性关系的权重系数 $w_{12}, w_{13}, w_{14}$ 是尽量不变或改变最小。
从上可看出,线性关系只在样本附近起作用,远离样本的数据对局部线性关系没有影响,因此降维复杂度降低很多。
LLE算法推导
Part 1
首先要确定邻域大小的选择,即需要多少个邻域样本来线性表示某样本。假设这个值为 $k$ ,可以通过和 KNN 一样的思想,采用距离度量如:欧式距离,来选择某样本的 $k$ 个最近邻。
在寻找某样本 $x_i$ 的 $k$ 个最近邻之后,就需要找到 $x_i$ 和 这 $k$ 个最近邻之间的线性关系,即找到线性关系的权重系数。显然这是一个回归问题。
我们假设有 $ m$ 个 $n$ 维样本 $\{x_1,x_2,...,x_m\}$ ,我们可以用均方差作为回归问题的损失函数:
$J(w)=\sum \limits _{i=1}^{m}\left\|x_{i}-\sum \limits_{j=1}^{k} w_{i j} x_{j}\right\|_{2}^{2}$
一般会对权重系数 $w_{ij}$ 做归一化的限制(保证 $W$ 的平移不变性),即权重系数需满足:
$\sum \limits _{j=1}^{k} w_{i j}=1$
对于不在样本 $x_i$ 邻域内的样本 $x_j$,令对应的 $w_{ij} = 0$。
对于 $J(W)$ ,我们需要求出权重系数,可以采用拉格朗日乘法来求解,这里先对 $J(W)$ 矩阵化:
$\begin{aligned}J(W) &=\sum \limits _{i=1}^{m}\left\|x_{i}-\sum \limits_{j=1}^{k} w_{i j} x_{j}\right\|_{2}^{2} \\&=\sum \limits_{i=1}^{m}\left\|\sum \limits_{j=1}^{k} w_{i j} x_{i}-\sum \limits_{j=1}^{k} w_{i j} x_{j}\right\|_{2}^{2} \\&=\sum \limits_{i=1}^{m}\left\|\sum \limits_{j=1}^{k} w_{i j}\left(x_{i}-x_{j}\right)\right\|_{2}^{2} \\&=\sum \limits_{i=1}^{m}\left\|\left(x_{i}-x_{j}\right) W_{i}\right\|_{2}^{2} \\&=\sum \limits_{i=1}^{m} W_{i}^{T}\left(x_{i}-x_{j}\right)^{T}\left(x_{i}-x_{j}\right) W_{i}\end{aligned}$
其中 $W_i =(w_{i1}, w_{i2},...w_{ik})$ 。
令矩阵 $Z_i=(x_i-x_j)^T(x_i-x_j)$ ,则 $J(W)$ 进一步简化为 $J(W) = \sum\limits_{i=1}^{m} W_i^TZ_iW_i$ 。对于权重约束,可以矩阵化为:
$\sum \limits _{j=1}^{k} w_{i j}=W_{i}^{T} 1_{k}=1$
现在我们将矩阵化的 $J(W)$ 以及权重约束 用拉格朗日子乘法合为一个优化目标:
$L(W)=\sum \limits _{i=1}^{m} W_{i}^{T} Z_{i} W_{i}+\lambda\left(W_{i}^{T} 1_{k}-1\right)$
对 $W$ 求导并令其值为0,得到
$2 Z_{i} W_{i}+\lambda 1_{k}=0$
即
$W_{i}=\lambda^{\prime} Z_{i}^{-1} 1_{k}$
其中 $\lambda' = -\frac{1}{2}\lambda$ 为一个常数。利用 $W_i^T1_k = 1$,对 $W_i$ 归一化,那么最终的权重系数 $W_i$ 为:
$W_{i}=\frac{Z_{i}^{-1} 1_{k}}{1_{k}^{T} Z_{i}^{-1} 1_{k}}$
Part 2
现在得到了高维的权重系数,我们希望这些权重系数对应的线性关系在降维后的低维一样得到保持。假设我们的 $n$ 维样本集 $\{x_1,x_2,...,x_m\}$ 在低维的 $d$ 维度对应投影为 $\{y_1,y_2,...,y_m\}$ ,我们希望保持线性关系,也就是希望对应的均方差损失函数最小,即最小化损失函数 $J(Y)$ 如下:
$J(y)=\sum \limits _{i=1}^{m}\left\|y_{i}-\sum \limits _{j=1}^{k} w_{i j} y_{j}\right\|_{2}^{2}$
可以看到这个式子和高维的损失函数几乎相同,唯一的区别是高维的式子中,高维数据已知,目标是求最小值对应的权重系数 $W$,而我们在低维是权重系数 $W$ 已知,求对应的低维数据。
为了得到标准化的低维数据,一般也会加入约束条件如下:
$\sum \limits _{i=1}^{m} y_{i}=0 ; \quad \frac{1}{m} \sum \limits _{i=1}^{m} y_{i} y_{i}^{T}=I$
首先我们将目标损失函数矩阵化:
$\begin{aligned}J(Y) &=\sum \limits _{i=1}^{m}\left\|y_{i}-\sum \limits_{j=1}^{k} w_{i j} y_{j}\right\|_{2}^{2} \\&=\sum \limits_{i=1}^{m}\left\|Y I_{i}-Y W_{i}\right\|_{2}^{2} \\&=\operatorname{tr}\left(Y^{T}(I-W)^{T}(I-W) Y\right)\end{aligned}$
如果我们令 $M=(I-W)^T(I-W)$ ,则优化函数转变为最小化下式:$J(Y) = tr(Y^TMY)$ ,$tr$ 为迹函数。约束函数矩阵化为:$Y^TY=mI$ 。
谱聚类和 $PCA$ 的优化和这里的优化过程几乎一样。最小化 $J(Y)$ 对应的 $Y$ 就是 $M$ 的最小的 $d$ 个特征值所对应的 $d$ 个特征向量组成的矩阵。当然我们也可以通过拉格朗日函数来得到这个:
$L(Y)=\operatorname{tr}\left(Y^{T} M Y\right)+\lambda\left(Y^{T} Y-m I\right)$
其中 $Y=\left(y_{ 1}, y_{ 2}, \ldots y_{k}\right)^T$ 。
对 $Y$ 求导并令其为 $0$ ,我们得到 $2MY + 2\lambda Y =0$ ,即 $MY = \lambda Y$ ,要得到最小的 $d$ 维数据集,就需要求出矩阵 $M$ 最小的 $d$ 个特征值所对应的 $d$ 个特征向量组成的矩阵 $Y=(y_1,y_2,...y_d)$ 即可。
一般的,由于 $M$ 的最小特征值为 $0$ 不能反应数据特征,此时对应的特征向量为全 $1$ 。我们通常选择 $M$ 的第 $ 2$ 个到第 $d+1$ 个最小的特征值对应的特征向量 $M=(y_2,y_3,...y_{d+1})$ 来得到最终的 $Y$。为什么 $M$ 的最小特征值为 $0$ 呢?这是因为 $W^Te =e$,得到 $|W^T-I|e =0$,由于$e \neq 0$,所以只有 $W^T-I =0$,即 $(I-W)^T=0$,两边同时右乘 $I-W$,即可得到 $(I-W)^T(I-W)e =0e$,即 $M$ 的最小特征值为 $0$。
LLE算法流程
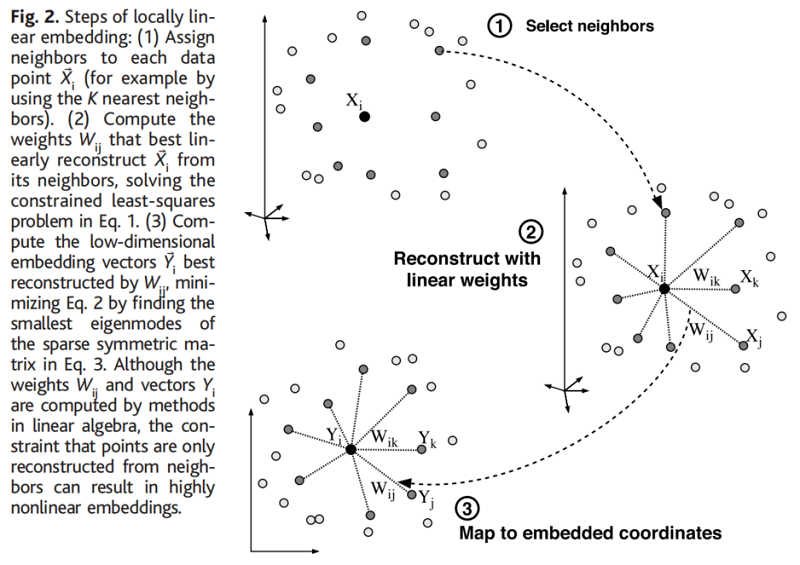
从图中可以看出,LLE 算法主要分为三步,第一步是求 $K$ 近邻的过程,这个过程使用了和 KNN 算法一样的求最近邻的方法。第二步,就是对每个样本求它在邻域里的 $K$ 个近邻的线性关系,得到线性关系权重系数 $W$。第三步就是利用权重系数来在低维里重构样本数据。
具体过程如下:
输入:样本集 $D=\{x_1,x_2,...,x_m\}$,最近邻数 $k$,降维到的维数 $d$
输出: 低维样本集矩阵 $D'$
1) for i 1 to m,按欧式距离作为度量,计算和 $x_i$ 最近的的 $k$ 个最近邻 $(x_{i1}, x_{i2}, ...,x_{ik},)$
2) for i 1 to m,求出局部协方差矩阵 $Z_i=(x_i-x_j)^T(x_i-x_j)$,并求出对应的权重系数向量:
$W_{i}=\frac{Z_{i}^{-1} 1_{k}}{1_{k}^{T} Z_{i}^{-1} 1_{k}}$
3) 由权重系数向量 $W_i$ 组成权重系数矩阵 $W$,计算矩阵 $M=(I-W)^T(I-W)$
4) 计算矩阵 $M$ 的前 $d+1$ 个特征值,并计算这 $d+1$ 个特征值对应的特征向量 $\{y_1,y_2,...y_{d+1}\}$。
5)由第二个特征向量到第 $d+1$ 个特征向量所张成的矩阵即为输出低维样本集矩阵 $D' = (y_2,y_3,...y_{d+1})$
LLE总结
LLE是广泛使用的图形图像降维方法,它实现简单,但是对数据的流形分布特征有严格的要求。比如不能是闭合流形,不能是稀疏的数据集,不能是分布不均匀的数据集等等,这限制了它的应用。下面总结下LLE算法的优缺点。
LLE算法的主要优点有:
1)可以学习任意维的局部线性的低维流形
2)算法归结为稀疏矩阵特征分解,计算复杂度相对较小,实现容易。
LLE算法的主要缺点有:
1)算法所学习的流形只能是不闭合的,且样本集是稠密均匀的。
2)算法对最近邻样本数的选择敏感,不同的最近邻数对最后的降维结果有很大影响。
『总结不易,加个关注呗!』

因上求缘,果上努力~~~~ 作者:图神经网络,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/15581523.html

