概率论——常用分布
伯努利试验
伯努利试验(Bernoulli experiment)是在同样的条件下重复地、相互独立地进行的一种随机试验,其特点是该随机试验只有两种可能结果:发生或者不发生。
我们假设该项试验独立重复地进行了 $n$ 次,那么就称这一系列重复独立的随机试验为 $n$ 重伯努利试验,或称为伯努利概型。单个伯努利试验是没有多大意义的,然而,当我们反复进行伯努利试验,去观察这些试验有多少是成功的,多少是失败的,事情就变得有意义了,这些累计记录包含了很多潜在的非常有用的信息。
如果无穷随机变量序列 $X_{1}, X_{2}, \ldots$ 是独立同分布 $(i. i. d . )$ 的,而且每个随机变量 $X_{i}$ 都服从参数为 $\mathrm{p}$ 的伯努利分布, 那么 随机变量 $X_{1}, X_{2}, \ldots$ 就形成参数为 $p$ 的一系列伯努利试验。同样,如果 $n$ 个随机变量 $X_{1}, X_{2}, \ldots, X_{n}$ 独立同分布,并且都服从参数为 $p$ 的伯努利分布,则随机变量 $X_{1}, X_{2}, \ldots, X_{n}$ 形成参数为 $p$ 的 $n$ 重伯努利试验。
下面举几个例子加以说明,假定重复抛掷一枚均匀硬币,如果在第 $i$ 次抛掷中出现正面,令 $X_{i}=1$ ;如果出现反面$X_{i}=0$,那么,随机变量 $X_{1}, X_{2}, \ldots$ 就形成参数为 $p=\frac{1}{2}$ 的一系列伯努利试验,同样,假定由一个特定机器生产的零件中 $10 \%$ 是有缺陷的,随机抽取 $n$ 个进行观测,如果第 1 个零件有缺陷,令 $X_{i}=1$ ; 如果没有缺陷,令 $X_{i}=0, i=1,2, \ldots, n$ , 那么,随机变量 $X_{1}, X_{2}, \ldots, X_{n} $ 就形成参数为 $p=\frac{1}{10}$ 的 $n$ 重伯努利试验。
离散分布
二项分布
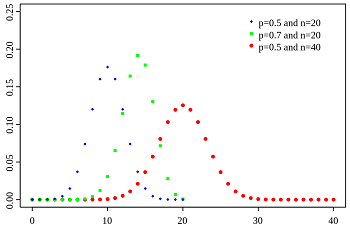
定义:在 $n$ 次独立重复的伯努利试验中,设每次试验中事件 $A$ 发生的概率为 $p$。用 $X$ 表示 $n$ 重伯努利试验中事件 $A$ 发生的次数,则 $X$ 的可能取值为 $0,1,…,n$ ,且对每一个 $k$($0≤k≤n$),事件 ${X=k}$ 即为 “ $n$ 次试验中事件 $A$ 恰好发生 $k$ 次”,随机变量 $X$ 的离散概率分布即为二项分布(Binomial Distribution)。
记 $X$ 为 $n$ 重伯努利试验中成功的事件 (记为 $A$ ) 的次数,则 $X=0,1,2, \cdots, n$ 。 $X$ 服从二项分布,记 $p$ 为事件 $A$ 发生的概率, $X$ 的分布列为:
$P\{X=k\}=\left(\begin{array}{l}n \\k\end{array}\right) p^{k}(1-p)^{n-k}, \quad k=0,1, \cdots, n$
记做
$X \sim b(n, p)$
或:$X \sim B(n, p)$
符号“~”读作“服从于”,该记号表示随机变量 $X$ 服从参数为 $n,p$ 的二项分布。
数学期望:$np$
方差:$np(1-p)$
举例:
1. 设射手命中率为 $0.8$ ,则射击 $n$ 次, 命中的次数 $X \sim b(n, 0.8)$ .
2. 已知人群中色盲率为 $p$ , 在人群中随机调查50个人,则其中色盲患者 $ X \sim b(50, p)$ .
3. 某药品的有效率为 $ 0.9$ , 今有 $10$ 人服用,则服药有效的人数 $ X \sim b(10,0.9)$ .
4.......
两点分布
两点分布:是一种当 $n=1$ 时的特殊的二项分布,又名 $0-1$分布,伯努利分布,用来描述一次伯努利试验中成功的次数 $X $,其中$X=0,1$ 。$X$ 服从两点分布, 分布列为:
$P(X=x)=p^{x}(1-p)^{1-x}, \quad x=0,1 $
或表示为:
$\begin{array}{c|c|c}\mathrm{X} & 0 & 1 \\\hline P & 1-p & p\end{array}$
其中 $p=P(X=1)$ 为事件成功的概率。
举例:
1. 小明投篮命中率为 $ 0.8$ ,投篮一次,其命中的次数 $ X \sim b(1,0.8)$ ;
2. 彩票中奖率为 $ 0.0001$ , 小明购买一张彩票, 其中奖的次数 $ X \sim b(1,0.0001) $;
3. 不会做的单项选择题做对的概率为 $ 0.25$ ,随机选择一个选项, 做对的次数 $ X \sim b(1,0.25) $;
4. $ \ldots \ldots $
两点分布是特殊的二项分布, 在二项分布数学期望和方差的公式中取 $n=1$ 得到两点分布:
数学期望: $p$
方差: $p(1-p)$
二项分布与两点分布的关系:若有一列独立同分布于 $ b(1, p)$ 的随机变量序列 $ \left\{X_{i}\right\}_{i=1}^{n}$ , 则其和:
$X_{1}+X_{2}+\cdots+X_{n}=\sum_{i=1}^{n} X_{i} \sim b(n, p)$
这个结论表明两点分布具有可加性,且对于服从 $ b(n, p)$ 的随机变量 $ X$ , 可看做由 $ n$ 个独立 同分布于 $ b(1, p)$ 的随机变量 $ X_{i}$ 的和。
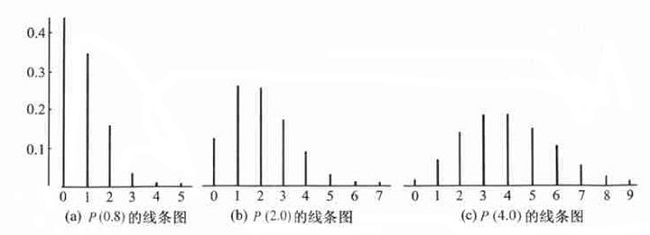
泊松分布
Poisson分布,是一种统计与概率学里常见到的离散概率分布,由法国数学家西莫恩·德尼·泊松(Siméon-Denis Poisson)在1838年时发表。
泊松分布的概率函数为:
$P(X=k)=\frac{\lambda^{k}}{k !} \mathrm{e}^{-\lambda}, \quad k=0,1,2, \cdots$
泊松分布的参数 $\lambda$ 是单位时间(或单位面积)内随机事件的平均发生次数。泊松分布适合于描述单位时间内随机事件发生的次数。
记 $X \sim P(\lambda)$,常与单位时间、单位面积、单位体积上的计数过程相联系。
数学期望: $\lambda$
方差: $\lambda$
这里数学期望为 $ \lambda$ 是指 $ X$ 的均值为 $ \lambda$ 。譬如对于应用举例 1,某段时间内,来到某商场的顾客数平均而言是 $\lambda$ 。其他的应用类似。
举例:
1. 某时间段内,来到某商场的顾客数;
2. 单位时间内,某网站的点击量;
3. 一平方米内玻璃上的气泡数;
4. $ \ldots \ldots $
均匀分布
若随机变量 $X$ 的密度函数为:
$p(x)=\left\{\begin{array}{lc}\frac{1}{b-a}, & a<x<b \\0, & \text { 其他. }\end{array}\right.$
称 $ X$ 服从区间 $ (a, b)$ 上的均匀分布,记作 $ X \sim U(a, b) $,其分布函数:
$F(x)=\left\{\begin{array}{ll}0, & x<a \\\frac{x-a}{b-a}, & a \leq x<b \\1, & x \geq b\end{array}\right.$
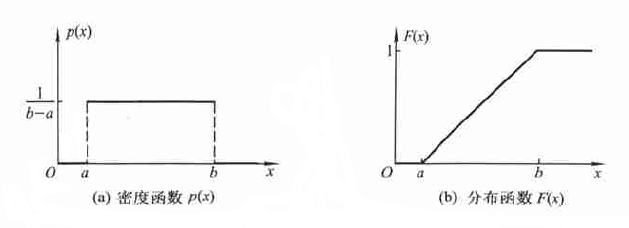
均匀分布又称作平顶分布(因其概率密度为常值函数)。
数学期望: $\frac{a+b}{2} $
方差: $ \frac{(b-a)^{2}}{12}$
超几何分布
有 $N$ 件产品,其中有 $M$ 件不合格品。若从中不放回地随机抽取 $n$ 件,则其中含有的不合格品的件数 $X$ 服从超几何分布,分布列为:
$P(X=k)=\frac{C_{M}^{k} C_{N-M}^{n-k}}{C_{N}^{n}}=\frac{\left(\begin{array}{c}M \\k\end{array}\right)\left(\begin{array}{c}N-M \\n-k\end{array}\right)}{\left(\begin{array}{l}N \\n\end{array}\right)}, \quad k=0,1, \cdots, r$。
记为 $X \sim h(n, N, M)$。其中 $r=\min \{M, n\}$,且 $M \leqslant N, n \leqslant N$ 。$n, N, M$ 均为正整数。
举例:从有 10 件不合格品的 100 件产品中随机抽取 5 件,则抽取的产品中不合格品数 $X \sim h(5,100,10) $。
数学期望:$n \bullet \frac{M}{N}$
方差:$D(X)=\frac{n M}{N}\left(1-\frac{M}{N}\right) \frac{N-n}{N-1}$
超几何分布和二项分布的联系
(1) 在超几何分布中,当 $N \rightarrow+\infty$ 时, $\frac{M}{N} \rightarrow P$ (二项分布中的 $\mathrm{p}$) 。
(2) 当 $ N \rightarrow+\infty$ 时,超几何分布的数学期望
$E X=\frac{n M}{N} \rightarrow n p=E X$
(3) 当 $ N \rightarrow+\infty$ 时,超几何分布的方差 $ D X=n p(1-p)$ (二项分布的方差) 。
(4) 当 $ N \rightarrow+\infty$ 时,超几何分布近似为二项分布。
几何分布
在伯努利试验序列中,记每次试验中事件 $A$ 发生的概率为 $p$,如果 $X$ 为事件 $A$ 首次出现时的试验次数。详细地说,是:前 $k-1$ 次皆失败,第 $k$ 次成功的概率。则 $X=1,2, \cdots$ 。$X$ 服从几何分布,分布列为:
$P(X=k)=(1-p)^{k-1} p, \quad k=1,2, \cdots $
记作 $ X \sim G e(p) $ 。
举例:
1. 某产品的不合格率为 0.05 , 首次查到不合格品的检查次数 $ X \sim G e(0.05) $
2. 某射手的命中率为 0.8 , 首次命中的射击次数 $ X \sim G e(0.8) $
3. 掷一颗骰子,首次出现六点的投郑次数 $ X \sim G e\left(\frac{1}{6}\right) $
4. .....
数学期望: $ \frac{1}{p} $
方差: $ \frac{1-p}{p^{2}} $
几何分布的无记忆性:
设 $X \sim G e(p)$ ,对任意正整数 $m, n$ ,有:
$P(X>m+n \mid X>m)=P(X>n)$
该性质表明,在前 $m$ 次试验中 $A$ 没有出现的条件下,则在接下去的 $n$ 次试验中 $A$ 仍末出现 的概率只与 $n$ 有关,而与以前的 $m$ 次试验无关,似乎忘记了前 $m$ 次试验结果, 这就是无记忆 性。
负二项分布
在伯努利试验序列中,记每次试验中事件 $A $ 发生的概率为 $p$ ,如果 $X$ 为事件 $A$ 第 $r$ 次出 现时的试验次数,则 $X$ 的可能取值为 $r, r+1, \cdots, r+m, \cdots$ , 称 $X$ 服从负二项分布或巴斯卡分布,其分布列为:
$P(X=k)=\left(\begin{array}{l}k-1 \\r-1\end{array}\right) p^{r}(1-p)^{k-r}, \quad k=r, r+1, \cdots$
记作: $X \sim N b(r, p)$ , 当 $r=1$ 时即为几何分布,即几何分布是特殊的负二项分布。从二项分布和负二项分布的定义中看出,二项分布是伯努利试验次数 ($n$) 固定,事件 $A$ 成功的次数 $X$ 在 $0 \sim n$ 中取值;而负二项分布是事件 $A$ 成功的次数 ( $r$ ) 固定,伯努利实验次数 $X$ 在 $r, r+1, \cdots$ 中取值,可见负二项分布的 "负" 字的由来。
数学期望: $\frac{r}{p} $
方差: $ \frac{r(1-p)}{p^{2}}$
从负二项分布和几何分布的数学期望和方差的关系可知,类比二项分布与两点分布的关系,可以得 到下面的结论:
若有一列独立同分布于 $ G e(p)$ 的随机变量序列 $ \left\{X_{i}\right\}_{i=1}^{n}$ , 则其和:
$X_{1}+X_{2}+\cdots+X_{r}=\sum \limits _{i=1}^{r} X_{i} \sim N b(r, p)$
这并不是说明几何分布具有可加性,因为可加性要求服从该类分布的随机变量的和仍服从该类分布,但是服从几何分布的随机变量的和服从负二项分布,这个概念要特别注意。上述结论只能说明 对于服从 $ Nb(r, p)$ 的随机变量 $ X$ ,可看做由 $ r$ 个独立同分布于 $ G e(p)$ 的随机变量 $ X_{i}$ 的和。
常用连续分布
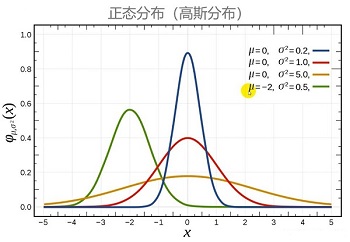
正态分布
正态分布(Normal distribution),也称“常态分布”,又名高斯分布(Gaussian distribution),最早由棣莫弗(Abraham de Moivre)在求二项分布的渐近公式中得到。C.F.高斯在研究测量误差时从另一个角度导出了它。P.S.拉普拉斯和高斯研究了它的性质。
若随机变量 $X$ 的密度函数为:
$p(x)=\frac{1}{\sqrt{2 \pi} \sigma} \mathrm{e}^{-\frac{(x-\mu)^{2}}{2 \sigma^{2}}}, \quad-\infty<x<\infty$
则称 $X$ 服从正态分布,称 $X$ 为正态变量。记 $X \sim N\left(\mu, \sigma^{2}\right) $。其中 $\mu$ 为位置参数,用于控制曲线在 $x$ 轴上的位置; $\sigma$ 为尺度参数,用于控制曲线的形状。
正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人们又经常称之为钟形曲线。
分布函数:
$F(x)=\int_{-\infty}^{x} p(t) \mathrm{d} t=\int_{-\infty}^{x} \frac{1}{\sqrt{2 \pi} \sigma} \mathrm{e}^{-\frac{(t-\mu)^{2}}{2 \sigma^{2}}} \mathrm{~d} t$
数学期望:$\mu$
方差: $\sigma^{2} $
称 $ \mu=0, \sigma^{2}=1$ 时的正态分布为标准正态分布,其密度函数和分布函数分别为:
$\begin{array}{l}\varphi(x)=\frac{1}{\sqrt{2 \pi}} \mathrm{e}^{-\frac{x^{2}}{2}} \\\Phi(x)=\int_{-\infty}^{x} \varphi(t) \mathrm{d} t=\int_{-\infty}^{x} \frac{1}{\sqrt{2 \pi}} \mathrm{e}^{-\frac{t^{2}}{2}} \mathrm{~d} t\end{array}$
任何一个正态变量均可以通过标准化转化为标准正态变量,即若 $X \sim N\left(\mu, \sigma^{2}\right) $,则:
$X^{*}=\frac{X-\mu}{\sigma} \sim N(0,1)$
其中 $ X^{*}$ 为标准正志变量。
性质:
若 $ X \sim N(0,1) $ :
$\begin{array}{l}\Phi(-a)=1-\Phi(a) \\P(X>a)=1-\Phi(a) \\P(a<x<b)=\Phi(b)-\Phi(a) \\P(|X|<c)=2 \Phi(c)-1, \quad(c \geq 0)\end{array}$
若 $X \sim N\left(\mu, \sigma^{2}\right)$:
$\begin{array}{l}P(X \leq c)=\Phi\left(\frac{a-\mu}{\sigma}\right) \\P(a<x \leq b)=\Phi\left(\frac{b-\mu}{\sigma}\right)-\Phi\left(\frac{a-\mu}{\sigma}\right)\end{array}$
正态分布的 $ 3 \sigma$ 原则:
$\begin{aligned}P(|X-\mu|<k \sigma) &=\Phi(k)-\Phi(-k) \\&=2 \Phi(k)-1 \\&=\left\{\begin{array}{ll}0.6826, & k=1 \\0.9545, & k=2 \\0.9973, & k=3\end{array}\right.\end{aligned}$
均匀分布
若随机变量 $X$ 的密度函数为:
$p(x)=\left\{\begin{array}{lc}\frac{1}{b-a}, & a<x<b \\0, & \text { 其他. }\end{array}\right.$
称 $ X$ 服从区间 $ (a, b) $ 上的均匀分布,记作 $ X \sim U(a, b)$ , 其分布函数:
$F(x)=\left\{\begin{array}{ll}0, & x<a \\\frac{x-a}{b-a}, & a \leq x<b \\1, & x \geq b\end{array}\right.$
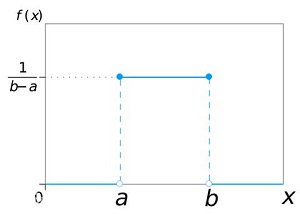
均匀分布又称作平顶分布(因其概率密度为常值函数)。
数学期望: $\frac{a+b}{2} $
方差:$\frac{(b-a)^{2}}{12}$
指数分布
若随机变量 $X$ 的密度函数为:
$p(x)=\left\{\begin{array}{cc}\lambda \mathrm{e}^{-\lambda x}, & x \geq 0 \\0, & x<0\end{array}\right.$
则称 $ X$ 服从参数为 $ \lambda$ 的指数分布,记作 $ X \sim \operatorname{Exp}(\lambda) $ 。指数分布的分布函数为:
$F(x)=\left\{\begin{array}{cl}1-\mathrm{e}^{\lambda x}, & x \geq 0 \\0, & x<0\end{array}\right.$
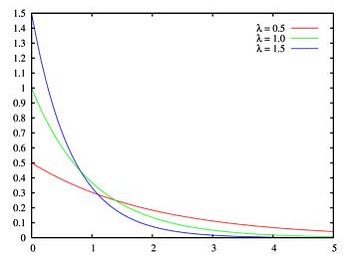
指数分布是一种偏态分布,指数分布随机变量只可能取非负实数。指数分布常被用作各种“寿命”分布,譬如电子元器件的寿命、动物的寿命、电话的通话时间、随机服务系统中的服务时间等都可假定服从指数分布。指数分布在可靠性与排队论中有着广泛的应用.。
数学期望: $\frac{1}{\lambda} $
方差: $ \frac{1}{\lambda^{2}}$
指数分布的无记忆性
若随机变量 $ X \sim \operatorname{Exp}(\lambda)$ , 则对任意的 $ t>0, s>0$ , 有:
$P(X>s+t \mid X>s)=P(X>t) $
证明:
因为 $ X \sim \operatorname{Exp}(\lambda)$ , 所以 $ P(X \geq s)=\mathrm{e}^{-\lambda s},(s>0) $。又因为
$\{X>s+t\} \subseteq\{X>s\} $
由条件概率可得:
$P(X>s+t \mid X>s)=\frac{P(X>s+t)}{P(X>s)}=\frac{\mathrm{e}^{-\lambda(s+t)}}{\mathrm{e}^{-\lambda t}}=\mathrm{e}^{-\lambda t}=P(X>t)$
证毕。
伽玛分布
若随机变量 $X$ 的密度函数为:
$p(x)=\left\{\begin{array}{cl}\frac{\lambda^{a}}{\Gamma(\alpha)} x^{a-1} \mathrm{e}^{-\lambda x}, & x \geqslant 0 \\0, & x<0\end{array}\right.$
称 $ \mathrm{X}$ 服从伽玛分布, 记作 $ X \sim G a(\alpha, \lambda)$ 。其中 $ \alpha>0$ 为形状参数,$ \lambda>0$ 为尺度参数。
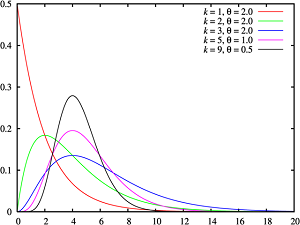
数学期望: $\frac{\alpha}{\lambda} $
方差: $\frac{\alpha}{\lambda^{2}} $
伽玛函数的特例:
1. $\alpha=1$ 时的伽玛分布为指数分布: $G a(1, \lambda)=\operatorname{Exp}(\lambda)$ ,
2.称 $\alpha=\frac{n}{2}$, $\lambda=\frac{1}{2}$ 的伽玛分布为自由度为 $n$ 的 $\chi^{2}$ (卡方) 分布,记作 $\chi^{2}(n)$ :
$G a\left(\frac{n}{2}, \frac{1}{2}\right)=\chi^{2}(n)$
因卡方分布是特殊的伽玛分布,故不难求得卡方分布的:
数学期望: $ n $
方差: $ 2 n$
卡方分布的唯一参数 $n$ 称为它的自由度, 具体含义在之后的数理统计中会给出。
贝塔分布
先给出贝塔函数:
$\mathrm{B}(a, b)=\int_{0}^{1} x^{a-1}(1-x)^{b-1} d x$
其中参数 $a>0, b>0$ 。
贝塔函数具有以下性质:
1. $B(a, b)=B(b, a) $
2.贝塔函数与伽玛函数有如下关系:
$\mathrm{B}(a, b)=\frac{\Gamma(a) \Gamma(b)}{\Gamma(a+b)}$
贝塔分布:
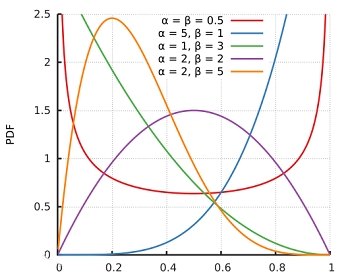
若随机变量 $X$ 的密度函数为:
$p(x)=\left\{\begin{array}{cc}\frac{\Gamma(a) \Gamma(b)}{\Gamma(a+b)} x^{a-1}(1-x)^{b-1}, & 0<x<1 \\0, & \text { 其他. }\end{array}\right.$
则称 $ X$ 服从贝塔分布, 记作 $X \sim B e(a, b)$ , 其中 $a>0, b>0$ 都是形状奈数。
数学期望: $\frac{a(a+1)}{(a+b)(a+b+1)} $
方差: $ \frac{a b}{(a+b)^{2}(a+b+1)}$
参考
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/15363005.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号