论文解读(BYOL)《Bootstrap Your Own Latent A New Approach to Self-Supervised Learning》
论文信息
论文标题:Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
论文作者:Jean-Bastien Grill, Florian Strub, Florent Altché....
论文来源:2020,NIPS
论文地址:download
论文代码:download
1 介绍
BYOL 的特点:
-
- 不需要 negative pairs;
- 对不同的 batch size大小和数据增强方法适应性强;
使用 BYOL 的效果:使用标准的 ResNet 达到 74.3% top-1 的准确率和使用large ResNet 达到 79.6% top-1的准确率。
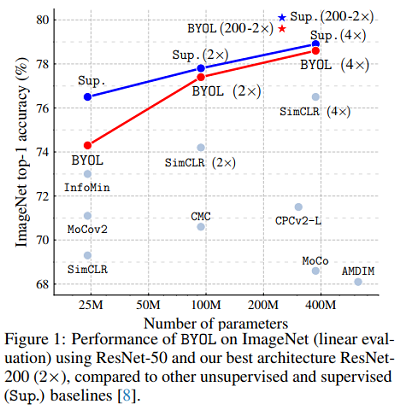
贡献:
- 引入了一种自监督的表示学习方法BYOL,在不使用负对的情况下,在ImageNet上的线性评估协议下获得最先进的结果。
- 在半监督 和 transfer基准测试中,我们所学的表现优于最先进的水平。
- BYOL对批量和图像增强集的变化更有弹性。当仅使用随机裁剪作为图像增强时,BYOL的性能下降比强对比基线 SimCLR小得多。
2 BYOL框架
BYOL框架图:

如下图 2 所示,BYOL 由两个网络组成,一个称为online network,另一个称为 target network 。online network由三部分构成:encoder $f_{\theta}$, projector $g_{\theta} $ 和 predictor $q_{\theta}$;target network 和 online network 有相似的结构,唯一的不同就是它少了一个 predictor,它的 encoder 和 projector 分别用 $f_{\xi}$ 和 $ g_{\xi }$ 表示。
两个网络训练方式:
-
- online network 的参数 $\theta$ 用梯度下降更新;
- target network 的参数 $\xi$ 不通过梯度下降来更新,而是由 $\theta$ 的指数移动平均($\xi \leftarrow \tau \xi+(1-\tau) \theta$)来更新。
- 即 $\begin{array}{l} \theta \leftarrow \text { optimizer }\left(\theta, \nabla_{\theta} \mathcal{L}_{\theta, \xi}^{\mathrm{BYOL}}, \eta\right) \\ \xi \leftarrow \tau \xi+(1-\tau) \theta \end{array}$
online network 在执行梯度下降更新时, 计算 loss:
$\mathcal{L}_{\theta, \xi}^{B Y O L}=\mathcal{L}_{\theta, \xi}+\widetilde{\mathcal{L}}_{\theta, \xi} $
其中 $ \mathcal{L}_{\theta, \xi}=2-2 \cdot \frac{\left\langle q_{\theta}\left(z_{\theta}\right), z_{\xi}^{\prime}\right\rangle}{\left\|q_{\theta}\left(z_{\theta}\right)\right\|_{2} \cdot\left\|z_{\xi}^{\prime}\right\|_{2}}$ 。 $\widetilde{\mathcal{L}}_{\theta, \xi}$ 是 $ \mathcal{L}_{\theta, \xi}$ 的对称形式:$ \mathcal{L}$ 的输入是 $ t$ 的 prediction 和 $ t^{\prime}$ 的 projection; $\widetilde{\mathcal{L}}$ 的输入是 $ t^{\prime} $ 的prediction 和 $ t$ 的 projection,相当于交叉预测对方的 projection 。
算法流程:

3 启发
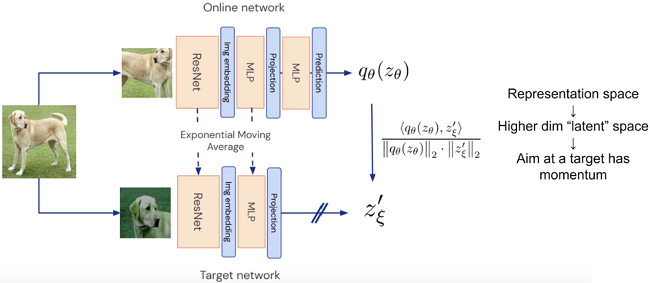
联系GAN,两个网络学到的表示要尽可能相同,但总互相干扰(动量法)。
4 实验
4.1 Linear evaluation on ImageNet
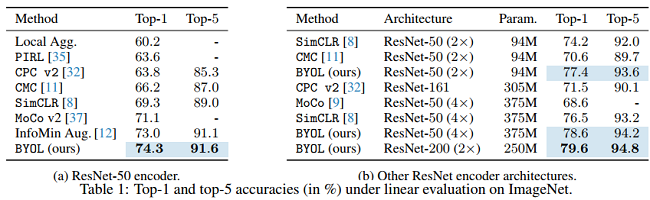
对比之前的自监督方法,BYOL(采用 ResNet encoder (1 $\times$))效果更好,在 Top-1 上达74.3的准确率,在 Top-5 上达 91.6 的准确率。更换 encoder 框架后效果依然很好。
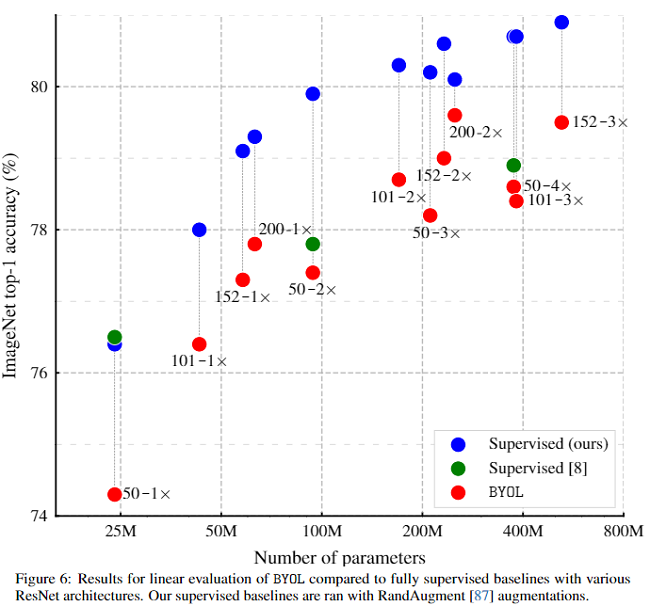
显然无监督方法 BYOL 的效果要比自监督的 BYOL 效果要差,但是比大部分其他监督方法要好。
4.2 Semi-supervised training on ImageNet
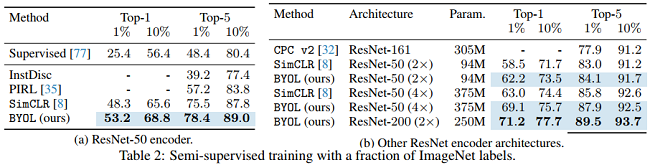
在获得表示后,使用训练集上的 label 对BYOL's representation 进行微调。
(a) 可以看到 BYOL 在 Top-1 和 Top-5上的效果比InstDisc、PIRL、SimCLR效果要好。
(b) 可以看到采用不同的 Encoder Architecture 效果依然显著。
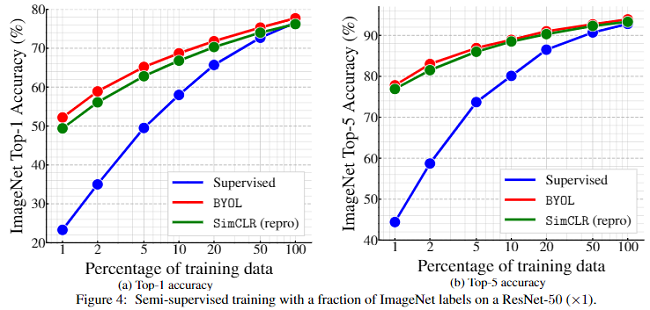
图 4 采用不同的微调率(1% and 10%),使用 ResNet-50(1 $\times$ ) 在不同 ImageNet traininjg data 上的表现。
从图 4 可以看出有监督方法在 training data少的情况下表现是很糟糕的,使用全部 training data 的效果还是比较好的,但是无监督方法仍然可以通过微调达到一个可以媲美有监督方法的实验结果。
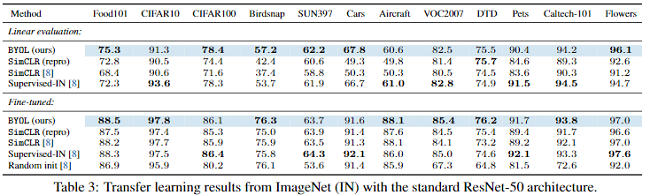
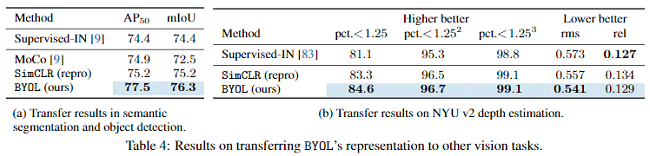
4.3 Transfer to other classification tasks
4.4 Ablation Study
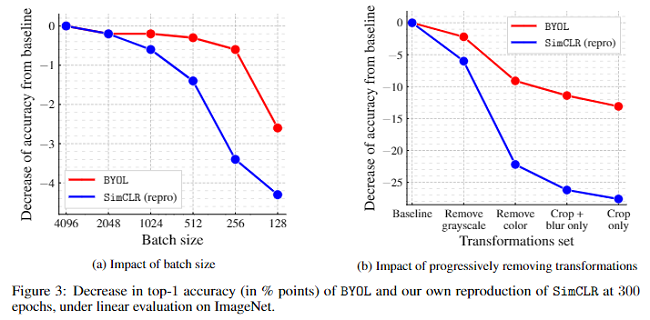
这里采用不同的 Batch size 和SimCLR做消融实验。
从图中可以看出SumCLR对Batch size 的变化更加敏感,因为它需要更多的负样本。BYOL对样本数不是很敏感,这是它的优势。
5 总结
- + BYOL learns it's representation by predicting previous versions of its outputs, without using negative pairs.
- + BYOL bridges most of the remaining gapbetween self-supervised methods and the supervised learning baseline.
- - Sensitive to batch size & opimizer choices
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/15255409.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号