论文解读(Moco)《Momentum Contrast for Unsupervised Visual Representation Learning》
论文信息
论文标题:Momentum Contrast for Unsupervised Visual Representation Learning
论文作者:Kaiming He、Haoqi Fan、 Yuxin Wu、 Saining Xie、 Ross Girshick
论文来源:2020 CVPR
论文地址:download
论文代码:download
引用次数:5582
1 介绍
思想:对比学习;
假设:
-
- 期望负样本数量足够大;
- 期望 $\text{key}$ 足够连续一致;[ 同一批数据 经过编码器 得到的表示要大差不差,这样能很好保存正样本和负样本信息 ]
2 方法对比
2.1 end-to-end
框架:
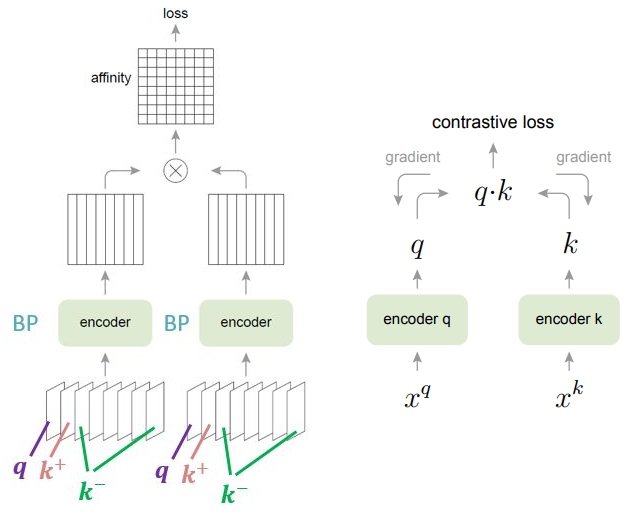
特点:
-
- 基于 $\text{batch }$ 的训练方式;
- 两个 $\text{encoder}$ 的架构相同,但是参数不同,各自训练;
问题:
-
- 受限于负样本的数量,且依赖于显卡,因为是基于 $\text{batch }$ 的训练方式;
- 一致性不高,因为两个 $\text{encoder}$ 的参数是各自更新;
2.2 memory bank
框架:
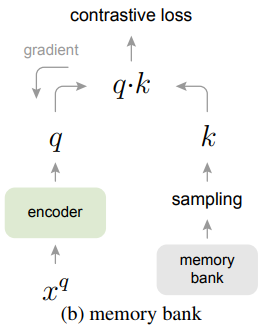
特点:
-
- 采用动量更新的 $\text{memory bank}$;
- 每个 $\text{iterate}$ 都要随机从字典中抽取特征进行更新;
问题:
-
- 字典里的特征一致性不够,随机抽取特征,不能保证是正样本;
- 动量更新的是表示,不是参数;
2.3 Moco
框架:
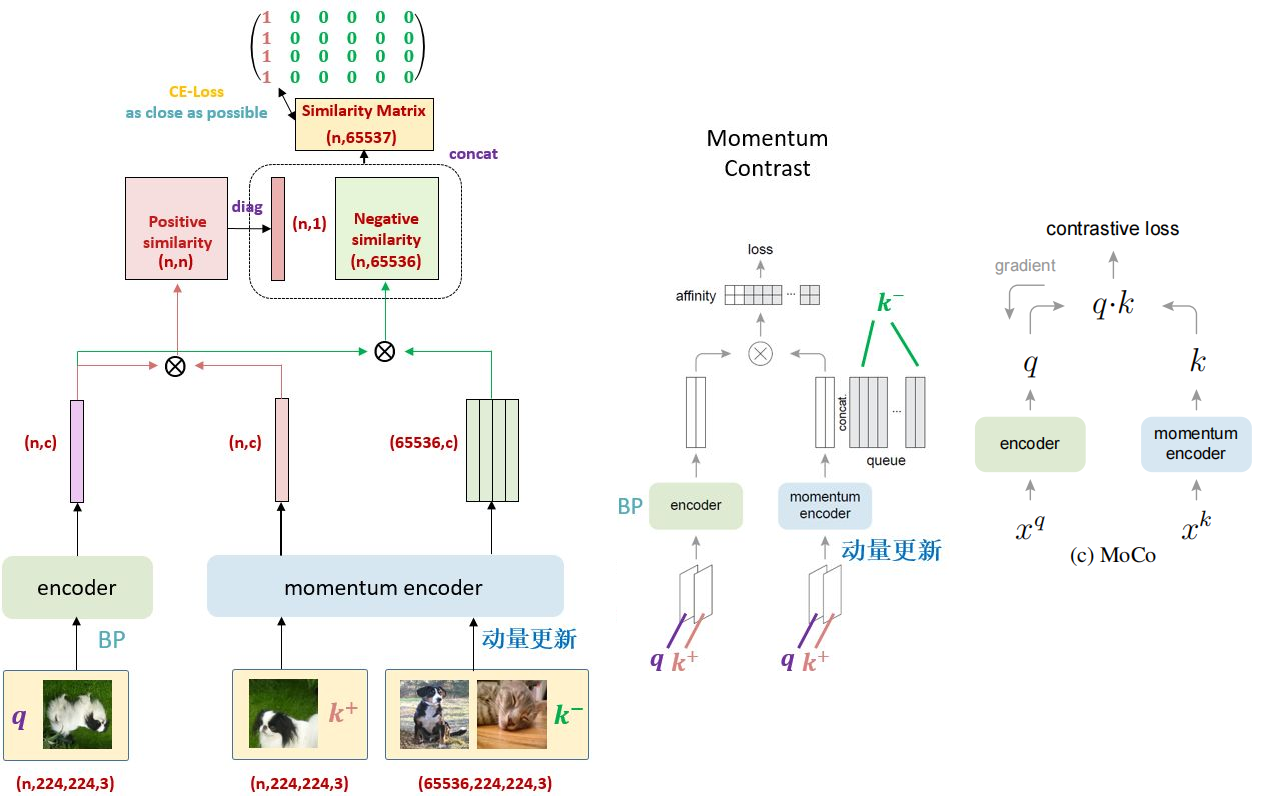
算法:



@torch.no_grad() def dequeue_and_enqueue(self, keys): batch_size = keys.shape[0] ptr = int(self.queue_ptr) assert self.K % batch_size == 0 # for simplicity self.queue[:, ptr : ptr + batch_size] = keys.T ptr = (ptr + batch_size) % self.K # move pointer self.queue_ptr[0] = ptr def forward(self, im_q, im_k): q = self.encoder_q(im_q) # queries: NxC torch.Size([16, 128]) q = nn.functional.normalize(q, dim=1) with torch.no_grad(): # no gradient to keys self.momentum_update_key_encoder() # update the key encoder k = self.encoder_k(im_k) # keys: NxC torch.Size([16, 128]) k = nn.functional.normalize(k, dim=1) l_pos = torch.einsum("nc,nc->n", [q, k]).unsqueeze(-1) #torch.Size([16, 1]) torch.mul(q,k).sum(dim =1) l_neg = torch.einsum("nc,ck->nk", [q, self.queue.clone().detach()]) #torch.Size([16, 65536]) logits = torch.cat([l_pos, l_neg], dim=1) #torch.Size([16, 65537]) logits /= self.T labels = torch.zeros(logits.shape[0], dtype=torch.long).to(self.device) self.dequeue_and_enqueue(k) return logits, labels
- 对比损失(contrastive loss): lnfoNCE
$\mathcal{L}_{q}=-\log \frac{\exp \left(q \cdot k_{+} / \tau\right)}{\sum \limits _{i=0}^{K} \exp \left(q \cdot k_{i} / \tau\right)}$
- 动量对比(Momentum Contrast)
- 假设好的特征可以通过一个包含丰富负样本集的大字典来学习。
- 字典作为队列(Dictionary as a queue)
- 将字典维护为数据样本队列, 允许重用来自前面的小批量(mini-batche)的编码键( key );
- 字典大小可以比 mini-batch 大得多;
- 字典中的样本被逐步替换;
- 动量更新(Momentum update)
- 使用队列可以使字典变大,但也使得通过反向传播更新关键编码器变得困难(梯度应该传播到队列中的所有样本)。一个不成熟的解决方案是从 key encoder $f_q$ 复制梯度到 query encoder $f_k$,忽略 $f_k$ 的梯度。但是这种解决方案在实验中产生了较差的结果。我们假设这种失败是由快速变化的编码器引起的,这降低了关键表示的一致性。 我们建议 使用 动量更新 来解决这个问题。
- 将 $f_k$ 的参数表示为 $\theta _k$,将 $f_q$ 的参数表示为 $\theta _q$,我们通过以下方式更新 $\theta _k$:
- 使用队列可以使字典变大,但也使得通过反向传播更新关键编码器变得困难(梯度应该传播到队列中的所有样本)。一个不成熟的解决方案是从 key encoder $f_q$ 复制梯度到 query encoder $f_k$,忽略 $f_k$ 的梯度。但是这种解决方案在实验中产生了较差的结果。我们假设这种失败是由快速变化的编码器引起的,这降低了关键表示的一致性。 我们建议 使用 动量更新 来解决这个问题。
$\theta_{\mathrm{k}} \leftarrow m \theta_{\mathrm{k}}+(1-m) \theta_{\mathrm{q}}$ $m \in[0,1)$
只有参数 $\theta _q$ 被反向传播更新,经发现 $m = 0.999$ 效果比较好。
3 总结
略;
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/14994065.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号