机器学习——Adaboost
1 Adaboost 的提出
1990年,Schapire最先构造出一种多项式级的算法,即最初的Boost算法;
1993年,Drunker和Schapire第一次将神经网络作为弱学习器,应用Boosting算法解决OCR问题;
1995年,Freund和Schapire提出了Adaboost(Adaptive Boosting)算法,效率和原来Boosting算法一样,但是不需要任何关于弱学习器性能的先验知识,可以非常容易地应用到实际问题中。
2 Adaboost 的引入
学习Adaboost之前,先得知道这么几个概念:
强可学习(strongly learnable):在概率近似正确(probably approximately correct, PAC) 学习的框架中,一个概念(类),如果存在一个多项式的学习算法能够学习它,并且正确率很高,称这个概念是强可学习的;
弱可学习(weakly learnable):一个概念(类),如果存在一个多项式的学习算法能够学习它,学习的正确率仅比随机猜测略好,则称这个概念是弱可学习的。
1989, Schapire,证明:在PAC学习的框架下,一个概念是强可学习的充分必要条件是这个概念是弱可学习。
问题的提出:只要找到一个比随机猜测略好的弱学习算法就可以直接将其提升为强学习算法,而不必直接去找很难获得的强学习算法。
怎样实现弱学习转为强学习?例如:学习算法 A 在 a 情况下失效,学习算法 B 在 b 情况下失效,那么在 a 情况下可以用 B 算法,在 b 情况下可以用 A 算法解决。这说明通过某种合适的方式把各种算法组合起来,可以提高准确率。
为实现弱学习互补,面临两个问题:
- 怎样获得不同的弱分类器?
- 怎样组合弱分类器?
3 Adaboost 基本概念
两个问题如何解决:
每一轮如何改变训练数据的权值或概率分布?
AdaBoost:提高那些被前一轮弱分类器错误分类样本的权值,降低那些被正确分类样本的权值
如何将弱分类器组合成一个强分类器?
AdaBoost:加权多数表决,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用,减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用。
在《机器学习——集成学习(Bagging、Boosting、Stacking) 》小结中,已经讲到了Boosting算法系列的基本思想,如下图:
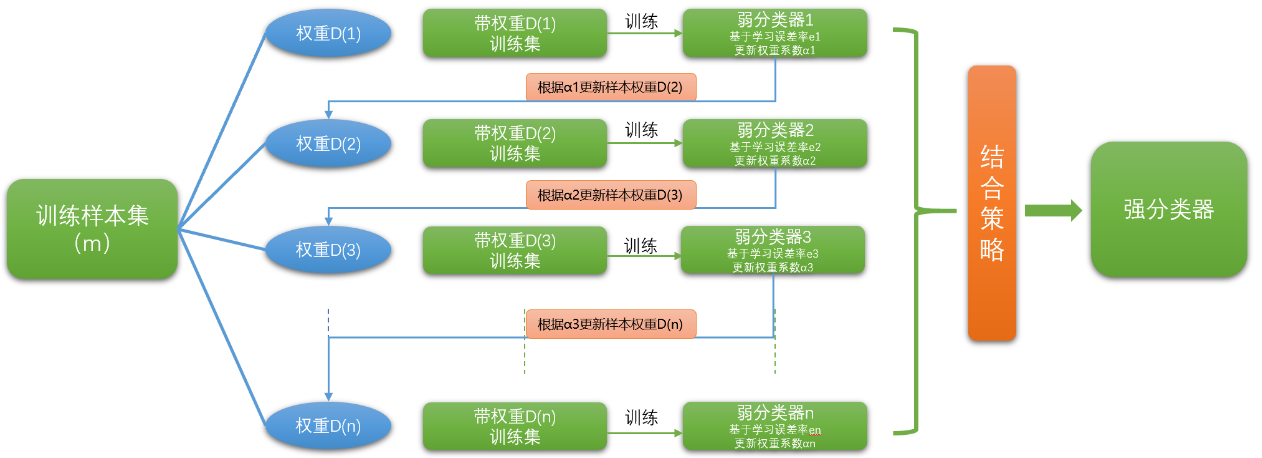
4 Adaboost 算法
假设给定一个二类分类的训练数据集
$T=\{ {( {{x_1},{y_1}} ),( {{x_2},{y_2}} ), \cdots ,( {{x_N},{y_N}} )} \}$
其中,每个样本点由实例与标记组成,实例 $ x_i\in \mathcal X \subseteq {R^n}$ ,标记 $y_i\in \mathcal Y=\{ { - 1, + 1} \}$ , $\mathcal X$ 是实例空间, $\mathcal Y$ 是标记集合。AdaBoost 利用以下算法,从训练数据中学习一系列弱分类器或基本分类器,并将这些弱分类器线性组合成为一个强分类器。
算法步骤:
- 输入:训练数据集 $T=\{ {( {{x_1},{y_1}} ),( {{x_2},{y_2}} ), \cdots ,( {{x_N},{y_N}} )} \}$,其中,$ x_i\in \mathcal X \subseteq {R^n},y_i\in \mathcal Y=\{ { - 1, + 1} \}$ ;弱学习算法;
- 输出:最终分类器 $G(x)$ ;
- 过程:
1、初始化训练数据的权值分布;
$ {D_1} = ( {{w_{11}}, \cdots ,{w_{1i}}, \cdots ,{w_{1N}}} ),{w_{1i}} = \frac{1}{N},i = 1,2, \cdots ,N$ ;
假设训练数据集具有均匀的权值分布,即每个训练样本在基本分类器的学习中作用相同,保证能在原始数据上学习基本分类器 $G_1(x)$ 。
2、对 $m=1,2,\cdots,M$,反复学习基本分类器,共执行 $M$ 轮。
2.1 使用具有权值分布 $D_m$ 的训练数据集学习,得到基本分类器: ${G_m}( x ):\mathcal X \to \{ { - 1, + 1} \}$ ,使用当前分布 $D_m$ 加权后的训练集学习基本分类器 $G_m(x)$ ;
2.2 计算 $G_m(x)$ 在训练数据集上的分类误差率:
${\large {e_m} = P( {{G_m}( {{x_i}} ) \ne {y_i}} ) = \sum\limits_{i = 1}^N {{w_{mi}}I( {{G_m}( {{x_i}} ) \ne {y_i}} )} = \sum \limits _{Gm(x_i\ne y_i)}w_{mi}} $
PS:经计算 $0<e_{m} \le \frac{1}{2} $。
其中 $w_{mi}$ 为第 $m$ 轮中第 $i$ 个实例的权值。计算分类器 $G_m(x)$ 在加权训练数据集上的分类误差率。
2.3 计算 ${G_m}( x )$ 的系数
${\large {\alpha _m} = \frac{1}{2}\log \frac{{1 - {e_m}}}{{{e_m}}}} $
对数为自然对数。用于计算分类器 $G_m(x)$ 在最终分类器中的重要性。
2.4 更新训练数据集的权值分布
${\large {D_{m + 1}} = ( {{w_{m + 1,1}}, \cdots ,{w_{m + 1,i}}, \cdots {w_{m + 1,N}}} )} $
${\large {w_{m + 1,i}} = {\Large \frac{w_{mi}}{Z_m}} {\Large e^{- {\alpha _m}{y_i}{G_m}( x_i)}} ,\quad i = 1,2, \cdots ,N} $
这里,$Z_m$ 是规范化因子
${\large {Z_m} = \sum\limits_{i = 1}^N {\Large {w_{mi} \ e^{ - {\alpha _m}{y_i}{G_m}( x_i )} }} } $
它使 $D_{m+1}$ 成为一个概率分布。
权值更新解释:
${\large w_{m+1,i}=\{\begin{array}{lr} {\Large \frac{w_{mi}}{Z_m} } e^{-{\alpha}_m},G_m(x_i)=y_i \\{\Large \frac{w_{mi}}{Z_m}} e^{{\alpha}_m},G_m(x_i) \ne y_i & \end{array}.} $
当 $G_m(x_i)=y_i $ 代表使用基分类器预测准确,此时 $G_m(x_i)$ 与 $y_i $ 同号,使得 ${y_i}{G_m}( x_i )=1$,导致 $0<e^{- \alpha _m}<1$,降低正确分类样本的权重。当 $G_m(x_i)\ne y_i $ 代表使用基分类器预测错误,此时 $G_m(x_i)$ 与 $y_i $ 异号,使得 ${y_i}{G_m}( x_i )=-1$,导致 $e^{ \alpha _m}>1$,提高了错误分类样本的权重。这样就满足了使得误分类的样本权值扩大。
3、构建基本分类器的线性组合
$ {\large f( x ) = \sum\limits_{m = 1}^M {{\alpha _m}{G_m}( x )}} $
得到最终分类器:
$ {\large G( x ) = sign( {f( x )} ) = sign( {\sum\limits_{m = 1}^M {{\alpha _m}{G_m}( x )} } )} $
线性组合 $f(x)$ 实现 $M$ 个分类器的加权表决。
5 AdaBoost 的例子
假定给出下列训练样本。

初始化:$w_{1i}=\frac{1}{n}=0.1$,n=10(样本个数)

阈值猜测:观察数据,可以发现数据分为两类:-1 和 1,其中数据 “0,1,2” 对应 “1” 类,数据 “3,4,5” 对应 “-1” 类,数据 “6,7,8” 对应 “1” 类,数据 “9” 对应 “"1” 类。抛开单个的数据 “9” ,可以找到对应的数据分界点(即可能的阈值),比如:2.5、5.5、8.5(一般0.5的往上加,也可以是其他数)。然后计算每个点的误差率,选最小的那个作为阈值。
但在实际操作中,可以每个数据点都做为阈值,然后就算误差率,保留误差率最小的那个值。若误差率有大于 0.5 的就取反(分类换一下,若大于取1,取反后就小于取1),再计算误差率。
迭代过程1:m=1
1> 确定阈值的取值及误差率
当阈值取2.5时,误差率为0.3。即 x<2.5 时取 1,x>2.5 时取 -1,则数据 6、7、8分错,误差率为0.3;
当阈值取5.5时,误差率最低为 0.4。即 x<5.5 时取 1,x>5.5 时取 -1,则数据 3、4、5、6、7、8 分错,错误率为 0.6>0.5,故反过来,令 x>5.5 取 1,x<5.5 时取 -1,则数据 0、1、2、9 分错,误差率为 0.4;
当阈值取8.5时,误差率为 0.3。即 x<8.5 时取1,x>8.5 时取 -1,则数据 3、4、5 分错,错误率为 0.3;
由上面可知,阈值取2.5 或8.5时,误差率一样,所以可以任选一个作为基本分类器。这里选2.5为例。
$G_1(x)=\begin{cases}1, &x<2.5 \\-1, & x>2.5 \end{cases}$
计算误差率:

从上可得 $G_1(x)$ 在训练数据集上的误差率(被分错类的样本的权值之和):
$e_1=P(G_1(x_i)\neq y_i)={\large \sum \limits _{G_1(x_i)\neq y_i} w_{1i}} =0.1+0.1+0.1=0.3$
2> 计算 $G_1(x)$ 的系数:
${\large \alpha_1=\frac{1}{2}ln\frac{1-e_1}{e_1}=\frac{1}{2}ln\frac{1-0.3}{0.3}} \approx 0.42365$
这个$\alpha_1$ 代表 $G_1(x)$ 在最终的分类函数中所占的比重约为0.42365。
3> 分类函数
$f_1(x)=\alpha_1G_1(x)=0.42365G_1(x)$
4> 更新权值分布:
根据公式:
${\large {w_{m + 1,i}} = {\Large \frac{w_{mi}}{Z_m}} {\Large e^{- {\alpha _m}{y_i}{G_m}( x_i)}} ,\quad i = 1,2, \cdots ,N}$
${\large {Z_m} = \sum\limits_{i = 1}^N {\Large {w_{mi} \ e^{ - {\alpha _m}{y_i}{G_m}( x_i )} }} }$
计算出:
$Z_1=\sum \limits _{i=1}^{n} {\large w_{1i}e^{-y_i\alpha _1G_1(x)}} $
$\ \quad {\large =\sum \limits _{i=1}^{3}0.1\times e^{-0.4263\times 1\times 1}+\sum \limits _{i}^{4-6,10}0.1\times e^{-0.4263\times (-1)\times (-1)}+\sum \limits _{i=7}^{9}0.1\times e^{-0.4263\times 1\times (-1)}} $
$\ \quad \approx 0.3928+0.4582+0.0655$
$\ \quad=0.9165$
$\ {\large {w_{2i} = \frac{w_{1i}}{Z_1} e^{- {\alpha _1}{y_i}{G_1}( x_i)}} =\left\{\begin{matrix} \frac{0.1}{0.9165}e^{- 1 \times 0.4236 \times 1} & i=1,2,3\\ \frac{0.1}{0.9165}e^{- (-1) \times 0.4236 \times (-1) } & i=4,5,6,10\\ \frac{0.1}{0.9165}e^{- 1 \times 0.4236 \times (-1) } & i=7,8,9 \end{matrix}\right.}$
$\ \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad {\large \approx \left\{\begin{matrix} 0.07143 & i=1,2,3\\ 0.07143 & i=4,5,6,10\\ 0.16666& i=7,8,9 \end{matrix}\right. } $

由上面可以看出,因为数据“6,7,8”被G1(x)分错了,所以它们的权值由初始的0.1增大到了0.16666;其他的数据由于被分对了,所以权值由0.1减小到0.07143。
迭代过程2:m=2
1> 确定阈值的取值及误差率
当阈值取2.5时,误差率为0.49998。即 x<2.5 时取 1,x>2.5 时取 -1,则数据6、7、8分错,误差率为0.16666*3(取过,不列入考虑范围)
当阈值取5.5时,误差率最低为0.28572。即 x<5.5 时取1,x>5.5 时取 -1,则数据3、4、5、6、7、8分错,错误率为0.07143*3+0.16666*3=0.71427>0.5,故反过来,令 x>5.5 取 1,x<5.5 时取 -1,则数据0、1、2、9分错,误差率为0.07143*4=0.28572
当阈值取8.5时,误差率为0.21429。即 x<8.5 时取1,x>8.5 时取 -1,则数据3、4、5分错,错误率为0.07143*3=0.21429
由上面可知,阈值取8.5时,误差率最小,所以:
$G_2(x)=\begin{cases}1, &x<8.5 \\-1, & x>8.5 \end{cases}$
计算误差率:

从上可得 $G_2(x)$ 在训练数据集上的误差率(被分错类的样本的权值之和):
$e_2=P(G_2(x_i)\neq y_i)=\sum \limits _{G_2(x_i)\neq y_i}w_{2i}=0.07143+0.07143+0.07143=0.21429$
2> 计算 $G_2(x)$ 的系数:
$\alpha_2=\frac{1}{2}ln\frac{1-e_2}{e_2}=\frac{1}{2}ln\frac{1-0.21429}{0.21429}\approx 0.64963$
3> 分类函数
$f_2(x)=\alpha_2G_2(x)=0.64963G_2(x)$
4> 更新权值分布:
$Z_2=\sum \limits _{i=1}^{n} {\large w_{2i} e^{-y_i\alpha _2G_2(x)} } $
${\large e =\sum \limits _{i=1}^{3}0.07143\times e^{-[1 \times 0.64963 \times 1]}+\sum \limits _{i=4}^{6}0.07143\times e^{-[(-1) \times 0.64963 \times 1]}} $
$\quad \quad {\large +\sum \limits _{i=7}^{9}0.1\times e^{-[1 \times 0.64963 \times 1]}+\sum \limits _{i=10}^{10}0.07143\times e^{-[(-1) \times 0.64963 \times(-1)]}} $
$\approx 0.11191+0.41033+0.26111+0.03730 $
$= 0.82065$
${\large \begin{aligned} w_{3 i} &=\frac{w_{2 i}}{Z_{2}} e^{ \left(-y_{i} \alpha_{2} G_{2}(x)\right)} \\ &=\left\{\begin{array}{ll} \frac{0.07143}{0.82065} e^{ (-[1 \times 0.64963 \times 1])} \approx 0.04546, & i=1,2,3 \\ \frac{0.07143}{0.82065} e^{(-[(-1) \times 0.64963 \times 1])} \approx 0.16667, & i=4,5,6 \\ \frac{0.16666}{0.82065} e^{ (-[1 \times 0.64963 \times 1])} \approx 0.10606, & i=7,8,9 \\ \frac{0.07143}{0.82065} e^{ (-[(-1) \times 0.64963 \times(-1)])} \approx 0.04546, & i=10 \end{array}\right. \end{aligned}} $
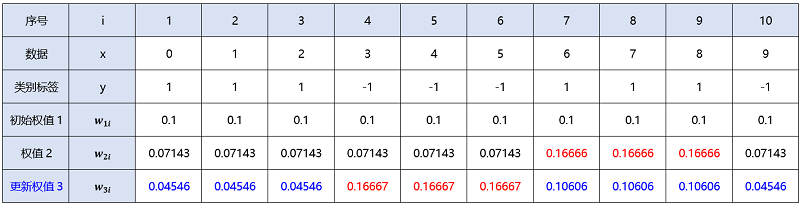
迭代过程3:m=3
1> 确定阈值的取值及误差率
当阈值取2.5时,误差率为0.31818。即 x<2.5 时取 1,x>2.5 时取 -1,则数据6、7、8分错,误差率为0.10606*3=0.31818(取过,不列入考虑范围)
当阈值取5.5时,误差率最低为0.18184。即 x<5.5 时取1,x>5.5 时取 -1,则数据3、4、5、6、7、8分错,错误率为0.16667*3+0.10606*3=0.81819>0.5,故反过来,令 x>5.5 取 1,x<5.5 时取 -1,则数据0、1、2、9分错,误差率为0.04546*4=0.18184
当阈值取8.5时,误差率为0.13638。即 x<8.5 时取1,x>8.5 时取 -1,则数据3、4、5分错,错误率为0.04546*3=0.13638(取过,不列入考虑范围)
由上面可知,阈值取8.5时,误差率最小,但8.5取过了,所以取5.5:
$G_3(x)=\begin{cases}-1, &x<5.5 \\1, & x>5.5 \end{cases}$
计算误差率:
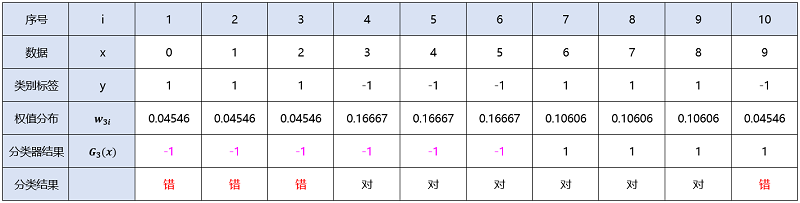
从上可得$G_3(x)$在训练数据集上的误差率(被分错类的样本的权值之和):
$e_3=P(G_3(x_i)\neq y_i)=\sum \limits _{G_3(x_i)\neq y_i}w_{3i}=0.04546+0.04546+0.04546+04546=0.18184$
2> 计算$G_3(x)$的系数:
$e_3=P(G_3(x_i)\neq y_i)=\sum_{G_3(x_i)\neq y_i}w_{3i}=0.04546+0.04546+0.04546+04546=0.18184$
这个$\alpha_3$代表$G_3(x)$在最终的分类函数中所占的比重约为0.75197
3> 分类函数
$f_3(x)=\alpha_3G_3(x)=0.75197G_3(x)$
4> 更新权值分布:
${\large Z_{3}= \sum \limits _{i=1}^{n} w_{3 i} e^{ (-y_{i} \alpha_{3} G_{3}(x_{i}))} } $
${\large = \sum \limits _{i=1}^{3} 0.04546 \times e^{ (-[1 \times 0.75197 \times(-1)]) }+\sum \limits _{i=4}^{6} 0.16667 \times e^{ (-[(-1) \times 0.75197 \times(-1)])}} $
${\large +\sum \limits _{i=7}^{9} 0.10606 \times e^{ (-[1 \times 0.75197 \times 1])} +\sum \limits _{i=10}^{10} 0.04546 \times e^{ (-[(-1) \times 0.75197 \times 1])} } $
$ {\large \approx 0.28929+0.23572+0.15000+0.09643 } $
${\large = 0.77144} $
$ {\large w_{4 i}=\frac{w_{3 i}}{Z_{3}} e^{ \left(-y_{i} \alpha_{3} G_{3}(x)\right)}=\left\{\begin{array}{ll} \frac{0.04546}{0.77144} e^{ (-[1 \times 0.75197 \times(-1)]) \approx 0.12500}, & i=1,2,3 \\ \frac{0.16667}{0.77144} e^{ (-[(-1) \times 0.75197 \times(-1)]) \approx 0.10185}, & i=4,5,6 \\ \frac{0.10606}{0.77144} e^{ (-[1 \times 0.75197 \times 1]) \approx 0.06481}, & i=7,8,9 \\ \frac{0.04546}{0.77144} e^{ (-[(-1) \times 0.75197 \times 1]) \approx 0.12500}, & i=10 \end{array}\right. } $
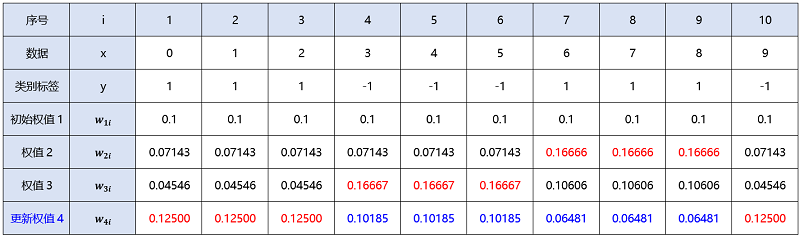
迭代过程4:m=4
此时观察数据,每次迭代被分错的数据都已经重新分配过权值,按其他参考资料来说,此时的误差率为0,所以迭代可以到此结束。
最终分类器:
$G_m(x)=sign(0.42365G_1(x)+0.64963G_2(x)0.75197G_3(x))$
6 AdaBoost算法的训练误差分析
AdaBoost算法最终分类器的训练误差界为
$\frac{1}{N}\sum\limits_{i=1}^NI(G(x_i)\ne y_i) \le \frac{1}{N}\sum\limits_{i=1}^N \exp(-y_if(x_i))=\prod\limits_{i=1}^NZ_i$
下面给出证明:
当 $ G(x_i) \ne y_i$ 时 $y_if(x_i) <0$ ,因而 $\exp(-y_if(x_i)) \ge1$
所以直接得前半部分不等式
由上面的公式 ${w_{m + 1,i}} = \frac{{{w_{mi}}}}{{{Z_m}}}\exp \left( { - {\alpha _m}{y_i}{G_m}\left( {{x_i}} \right)} \right)$
$w_{mi}\exp(-a_my_iG_m(x_i))=Z_mw_{m+1,i}$
推导如下
$ \frac{1}{N}\sum\limits_{i=1}^N\exp(-y_if(x_i))$
$=\frac{1}{N}\sum\limits_{i=1}^N\exp (-\sum\limits_{m=1}^Ma_my_iG_m(x_i))$
$=\sum\limits_{i=1}^Nw_{1i}\prod \limits _{m=1}^M \exp(-a_my_iG_m(x_i))$
$=Z_1\sum\limits_{i=1}^Nw_{2i}\prod \limits _{m=2}^M \exp(-a_my_iG_m(x_i))$
$ =Z_1Z_2\sum\limits_{i=1}^Nw_{3i}\prod \limits _{m=3}^M \exp(-a_my_iG_m(x_i))$
$ =...$
$ = \prod \limits_{m=1}^MZ_m$
定理8.2(二类分类问题AdaBoost的训练误差界)
$\prod \limits_{m=1}^MZ_m=\prod \limits_{m=1}^M[2\sqrt{e_m(1-e_m)}]$
$=\prod \limits _{m=1}^M\sqrt{(1-4\gamma^2_m)}$
$\le\exp(-2\sum\limits_{m=1}^M \gamma^2_m)$
其中
$\gamma_m=\frac{1}{2}-e_m$
下面证明
$ Z_m=\sum\limits_{i=1}^Nw_{mi}\exp(-\alpha_my_iG_m(x_i))$
$=\sum\limits_{y_i=G_m(x_i)}w_{mi}e^{-\alpha_m}+\sum\limits_{y_i \ne G_m(x_i)}w_{mi}e^{\alpha_m}$
$=(1-e_m)e^{-\alpha_m}+e_me^{\alpha_m}$
$=2\sqrt{e_m(1-e_m)}$
$=\sqrt{1-4\gamma_m^2}$
由 $e^x,\sqrt{1-x}$ 在 $x=0$ 的泰勒展开
$e^x=1+x+\frac{x^2}{2!}+\frac{x^3}{3!}+...+\frac{x^n}{n!}+Rn(x)$
$\sqrt{(1-x)} = 1-\frac{1}{2}x - \frac{1}{2*4}x^2 - \frac{1*3}{2*4*6}x^3 - ... (|x| ≤ 1)$
推出
$\sqrt{(1-4\gamma^2_m)}\le\exp(-2 \gamma^2_m)$
得到
$\prod \limits_{m=1}^M\sqrt{(1-4\gamma^2_m)}\le\exp(-2\sum\limits_{m=1}^M \gamma^2_m)$
推论8.1:如果存在$\gamma>0,$对所有$m$有$\gamma_m \ge \gamma$
则
$\frac{1}{N}\sum\limits_{i=1}^NI(G(x_i) \ne y_i)\le \exp(-2M \gamma^2)$
即在此条件下模型训练误差呈指数级下降
7 AdaBoost 算法的解释
7.1 前向分步算法
考虑加法模型
$f(x)=\sum\limits_{m=1}^M \beta_mb(x;\gamma_m)$
其中,$b(x;\gamma_m)$ 为基函数,$\gamma_m$ 为基函数的参数,$\beta_m$ 为基函数的系数。
显然,式 $ f( x ) = \sum\limits_{m = 1}^M {{\alpha _m}{G_m}( x )}$ 为一个加法模型
在给定训练数据及损失函数 $L(y,f(x))$ 的条件下,学习加法模型 $f(x)$ 成为经验风险极小化即损失函数极小化问题:
$\min \limits_{\beta_m,\gamma_m}\sum\limits_{i=1}^NL(y_i,\sum\limits_{m = 1}^M {\beta_mb(x;\gamma_m}))$
前向分布问题解决该优化问题的想法:因为学习的是加法模型,如果能够从前向后,每一步只学习一个基函数及其系数,逐步逼近优化目标函数式(上式),则可以简化优化的复杂度。
每步只需优化如下损失函数:
$\min \limits_{\beta,\gamma}\sum\limits_{i=1}^NL(y_i, {\beta b(x_i;\gamma}))$
给定训练数据集 $T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\}$,$x_i\in \mathcal X \subseteq {R^n},y_i\in \mathcal Y=\{ { - 1, + 1} \}$,损失函数 $L(y,f(x))$ 和基函数 $\{b(x;\gamma) \}$ 的集合,学习加法模型 $f(x)$ 的前向分布算法如下。
算法8.2(前向分布算法):
输入:训练数据集 $T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\}$;损失函数 $L(y,f(x))$,基函数集 $\{b(x;\gamma) \}$
输出:加法模型$f(x)$
$(1)$ 初始化 $f_0(x)=0$
$(2)$ 对 $m=1,2,...,M$
$(a)$ 极小化损失函数:
$\left(\beta_{m}, \gamma_{m}\right)=\underset{\beta, \gamma}{\arg \min } \sum \limits_{i=1}^{N} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+\beta b\left(x_{i} ; \gamma\right)\right)$
得到更新的参数 $\beta_m,\gamma_m$。【PS:一次只得到一对 $(\beta_{m}, \gamma _{m})$,每次循环使用上一次的分类器 $f_{m-1}$ 】
$(b)$ 更新
$f_m(x)=f_{m-1}(x)+\beta_mb(x:\gamma_m)$
$(3)$ 得到加法模型
$f(x)=f_M(x)=\sum\limits_{m=1}^M\beta_mb(x:\gamma_m)$
7.2 前向分步算法与AdaBoost
定理 8.3 AdaBoost算法是前向分布加法算法的特例.这时,模型是由基本分类函数组成的加法模型,损失函数是指数函数
下面证明前向分布函数的损失函数是指数损失函数时,其学习的具体操作等价于AdaBoost算法学习的具体操作
定义
$L(y,f(x))=\exp[-yf(x)]$
假设经过$m-1$次迭代得到$f_{m-1}(x)$
$f_{m-1}(x)=f_{m-2}(x)+\alpha_{m-1}G_{m-1}(x)$
$=\alpha_{1}G_{1}(x)+\cdots+\alpha_{m-1}G_{m-1}(x)$
第$m$轮迭代得到$\alpha_m,G_m(x),f(x)$
$f_m(x)=f_{m-1}(x)+\alpha_mG_m(x)$
目标是使分布向前算法得到的$\alpha_m,G_m(x)$使$f_m(x)$在训练数据集$T$上的指数损失最小
$\left(\alpha_{m}, G_{m}(x)\right)=\underset{\alpha, G}{\arg \min } \sum_{i=1}^{N} \exp \left[-y_{i}\left(f_{m-1}\left(x_{i}\right)+\alpha G\left(x_{i}\right)\right]\right.$
$\left(\alpha_{m}, G_{m}(x)\right)=\underset{\alpha, G}{\arg \min } \sum_{i=1}^{N} w_{m i} \exp \left[-y_{i} \alpha G\left(x_{i}\right)\right]$
其中
$\hat{w_{mi}}=\exp[-y_if_{m-1}(x_i)] $
$\hat{w_{mi}}$既不依赖$\alpha$也不依赖G,与最小化无关。但依赖于$f_{m-1}(x)$
首先求$G^*_m(x)$解
对任意$a>0$由下式得到
$G_{m}^{*}(x)=\underset{G}{\arg \min } \sum \limits _{i=1}^{N} w_{m i} I\left(y_{i} \neq G\left(x_{i}\right)\right)$
此分类器$G_m^*(x)$即为AdaBoost算法的基本分类器,使第m轮加权训练数据分类误差最小的分类器
随后求$a^*$
$\sum\limits_{i=1}^N\hat{w_{mi}}\exp[-y_i{\alpha}G(x_i)]=\sum\limits_{y_i=G_m(x_i)}\hat{w_{mi}}e^{-{\alpha}}+\sum\limits_{y_i\ne G_m(x_i)}\hat{w_{mi}}e^{{\alpha}} $
$=(e^{\alpha}-e^{-\alpha})\sum\limits_{i=1}^N\hat{w_{mi}}I(y_i \ne G(x_i))+e^{-\alpha}\sum\limits_{i=1}^N\hat{w_{mi}}$
将已求得的$G^*_m(x)$带入,对$\alpha$求导等于0得
$a^*_m=\frac{1}{2}\log \frac{1-e_m}{e_m} $
其中,$e_m$是分类误差率
$e_m=\frac{\sum\limits_{i=1}^N\hat{w_{mi}}I(y_i \ne G_m(x_i))}{\sum\limits_{i=1}^N\hat{w_{mi}}} $
$=\sum\limits_{i=1}^Nw_{mi}I(y_i \ne G_m(x_i))$
看每一轮样本权值的更新。由
$f_m(x)=f_{m-1}(x)+\alpha_mG_m(x)$
又
$\hat{w_{mi}}=\exp[-y_if_{m-1}(x_i)]$
则
$\hat{w_{m+1,i}}=\hat{w_{m,i}}\exp[-y_ia_mG_m(x)] $
8 提升树
提升树以分类树或回归树为基本模型的提升方法,最好的统计学习模型之一
8.1 提升树模型
提升方法实际采用加法模型与前向分布算法。以决策树为基函数的提升方法称为提升树。对分类问题决策树是二叉分类树,对回归问题决策树是二叉回归树。
提升树模型可以表示为决策树的加法模型:
$f_M(x)=\sum\limits_{m=1}^MT(x;\Theta_m)$
其中,$T(x;\Theta_m)$表示决策树,$\Theta$为参数,$M$为个数
8.2 提升树算法
提升树算法采用前向分步算法,首先确定出初始提升树$f_0(x)=0$,第m步的模型是:
$f_m(x)=f_{m-1}(x)+T(x;\Theta_m)$
其中,$f_{m-1}(x)$为当前模型,通过经验风险极小化确定下一棵决策树的参数:
$\hat{\Theta}_{m}=\underset{\Theta_{m}}{\arg \min } \sum \limits _{i=1}^{N} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+T\left(x ; \Theta_{m}\right)\right)$
不同问题的提升树学习方法使用的损失函数不同,回归问题一般用平方误差损失函数,分类问题一般用指数损失函数,以及其它一般决策问题的一般损失函数。
已知一个训练数据集$T={(x_1,y_1),(x_2,y_2),…,(x_N,y_N)}$,$x_i \in \mathcal X \subseteq {R^n},y_i \in \mathcal Y\subseteq {R},\mathcal X$为输入空间,$\mathcal Y$为输出空间。如果将输入空间$\mathcal X$划分为个$J$不相交的区域$R_1,R_2…,R_J$,并且在每个区域上确定输出的常量$c_j$,那么树可以表示为:
$T(x;\Theta_m)=\sum\limits_{j=1}^Jc_{j}I(x \in R_{j})$
其中,参数:$\Theta={\{(R_1,c_1)},(R_2,c_2),…,(R_J,c_J)\}$表示树的区域划分和各个区域上的常数,$J$是回归树的复杂度即叶结点个数。
回归问题的前向分步算法:
$f_0(x)=0$
$f_m(x)=f_{m-1}(x)+T(x;\Theta_m),m=1,2,...,M$
$f_M(x)=\sum\limits_{m=1}^MT(x;\Theta_m)$
在前向分步算法的第m步,给定当前模型fm-1(x),需求解
$\hat{\Theta}_{m}=\underset{\Theta_{m}}{\arg \min } \sum_{i=1}^{N} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+T\left(x ; \Theta_{m}\right)\right)$
得到$\hat\Theta_{m}$,即第m棵数的参数。
当采用平方平方误差损失函数时,
$L(y,f(x))=(y-f(x))^2$
其损失变为:
$L(y,f_{m-1}(x)+T(x;\Theta_m))=[y-f_{m-1}(x)-T(x;\Theta_m)]^2$
$=[r-T(x;\Theta_m)]^2$
其中:
$r=y-f_{m-1}(x)$
是当前模型的残差(residual),所以,对回归问题的提升树算法来说,只需简单地拟合当前模型的残差。
8.3 回归问题的提升树算法
输入:训练数据集$T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\}$其中$x_i \in \mathcal X \subseteq {R^n},y_i \in \mathcal Y\subseteq {R}$
输出:提升树$f_M(x)$
$(1)$初始化$f_0(x)=0$
$(2)$对$m=1,2,...,M$
$(a)$计算残差
$r_{mi}=y_i-f_{m-1}(x_i),\ \ \ \ \ \ i=1,2,...,N$
$(b)$拟合残差$r_{mi}$学习得到回归树得$T(x;\Theta_m)$
$(c)$更新$f_m(x)=f_{m-1}(x)+T(x;\Theta_m)$
$(3)$得到回归问题提升树
$f_M(x)=\sum\limits_{m=1}^MT(x;\Theta_m)$
8.4 梯度提升
一般损失函数不易优化,取梯度来替换残差.
这是利用最速下降法的近似方法,其关键是利用损失函数的负梯度在当前模型的值
$-[\frac{\partial L(y,f(x_i))}{\partial f(x_i)}]_{f(x)=f_{m-1}(x)}$作为回归问题提升树算法中的残差的近似值,拟合一个回归树。
算法8.4(梯度提升算法):
输入:训练数据集$T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\}$其中$x_i \in \mathcal X \subseteq {R^n},y_i \in \mathcal Y\subseteq {R}$损失函数$L(y,f(x))$
输出:回归树$\hat{f}(x)$
$(1)$初始化
$f_{0}(x)=\underset{c}{\arg \min } \sum \limits _{i=1}^{N} L\left(y_{i}, c\right)$
估计使损失函数极小化的常数值,它是只有一个根节点的树。
$(2)$对$m=1,2,...,M$
$(a)$对$i=1,2,...,N$计算
$r_{mi}=-[\frac{\partial L(y_i,f(x_i))}{\partial f(x_i)}]_{f(x)=f_{m-1}(x)}$
计算损失函数的负梯度在当前模型的值,将它作为残差的估计。对于平方损失函数,它就是通常所说的残差;对于一般损失函数,它就是残差的近似值。
$(b)$对$r_{mi}$拟合一个回归树,得到第$m$棵树的叶子区域$R_{mj},j=1,2,...,J$
估计回归树叶结点区域,以拟合残差的近似值。
$(c)$对$j=1,2,...,J$计算
$ c_{m j}=\underset{c}{\arg \min } \sum \limits _{x j \in R_{m j}} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+c\right)$
利用线性搜索估计叶结点区域的值,使损失函数极小化。
$(d)$更新$f_m(x)=f_{m-1}(x)+\sum\limits_{j=1}^Jc_{mj}I(x \in R_{mj})$
更新回归树
$(3)$得到回归树
$\hat{f}(x)=f_M(x)=\sum\limits_{m=1}^M\sum\limits_{j=1}^Jc_{mj}I(x \in R_{mj})$
得到输出的最终模型
9 GBDT
1. 算法每次迭代生成一颗新的决策树
2. 在每次迭代开始之前,计算损失函数在每个训练样本点的一阶导数和二阶导数
3. 通过贪心策略生成新的决策树,通过等式计算每个叶节点对应的预测值
$w_{j}^{*}=-\frac{G_{j}}{H_{j}+\lambda}$
4. 把新生成的决策树$f_t(x)$添加到模型中:
$\hat{y}_{i}^{t}=\hat{y}_{i}^{t-1}+f_{t}\left(x_{i}\right)$
通常在第四步,我们把模型更新公式替换为:
$\hat{y}_{i}^{t}=\hat{y}_{i}^{t-1}+\epsilon f_{t}\left(x_{i}\right)$
其中
$\in$ 称之为步长或者学习率。增加因子$\in$的目的是为了避免模型过拟合。
参考
参考文献
参考视频
1:集成学习 之【Adaboost】 —— 李航《统计学习方法》相关章节解读
因上求缘,果上努力~~~~ 作者:图神经网络,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/14942384.html

