机器学习——逻辑回归(Logistic Regression)
1 前言
虽然该机器学习算法名字里面有“回归”,但是它其实是个分类算法。取名逻辑回归主要是因为是从线性回归转变而来的。
logistic回归,又叫对数几率回归。
2 回归模型
2.1 线性回归模型
$h_\theta(x_1, x_2, ...x_n) = \theta_0 + \theta_{1}x_1 + ... + \theta_{n}x_{n}$
矩阵化如下:
$h_θ(X)=Xθ$
对应损失函数,一般用 均方误差 作为损失函数。损失函数代数法表示如下:
$J(\theta_0, \theta_1..., \theta_n) = \sum\limits_{i=0}^{m}(h_\theta(x_0, x_1, ...x_n) - y_i)^2$
矩阵化表示如下:
$J(\mathbf\theta) = \frac{1}{2}(\mathbf{X\theta} - \mathbf{Y})^T(\mathbf{X\theta} - \mathbf{Y})$
PS:线性回归模型可以参考本博客《机器学习——线性回归 》
2.2 广义线性回归
如果输出 $Y$ 和输入 $X$ 不满足线性关系,但 $log \ Y$ 和 $X$ 满足线性关系,采用模型函数如下:
$log \ Y=Xθ$
对与每个样本的输入 $y$ ,用 $log \ y$ 去对应, 这样仍可用线性回归算法处理。
线性回归模型只能进行回归学习,但是若要做分类任务该如何做?Answer:“广义线性回归”模型中:找一个 单调可微函数 将分类任务的真实标记 $y$ 与线性回归模型的预测值联系起来。
2.3 引出logistic 回归
logistic 回归处理二分类问题,输出标记 $y={0,1}$,考虑到线性回归模型的预测值 $z=wx+b$ 是一个实值,要将实值 $z$ 转化成 $0/1$ 值,假设可选函数 $g(.)$ 是“单位阶跃函数”:
$y=\left\{\begin{matrix} 0 & ,z<0 \\ 0.5 & ,z=0\\ 1 & ,z>0 \end{matrix}\right.$
预测值大于 $0$ 判断为正例,小于 $0$ 则判断为反例,等于 $0$ 任意判断。
由于单位阶跃函数是非连续的函数,需要一个连续函数,使用Sigmoid 连续函数作为 $g(.)$ 取代单位阶跃函数:
$g(z)=\frac{1}{1+e^{(-z)}} $
Sigmoid 函数在一定程度上近似单位阶跃函数,同时单调可微,图像如下所示:
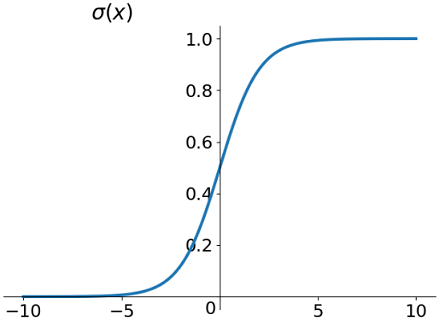
如图所示,Sigmoid 函数会把自变量 $x\in\{-\infty,+\infty\}$ 映射到 $y\in\{-1,+1\}$ 上。
Sigmoid 函数处处可导,导数为 $f^{\prime}(x)=f(x)(1-f(x))$ ,导数图像如下。从图中可以看出导数范围是 $f^\prime\in\{0,0.25\}$。

3 逻辑回归模型
线性回归模型:
$Z_{\theta}={X}\theta=w^Tx+b$
Sigmoid函数:
$g(z)=\frac{1}{1+e^{-z}}$
套上 Sigmoid 函数形成 logistic 回归模型的预测函数,可以用于二分类问题:
$h_\theta (X)=g(\theta^{T}X)=\frac{1}{1+e^{-\theta^{T}X}} $
一般化
$y=\frac{1}{1+e^{-(w^Tx+b)}} $
$0.5$ 可以作为分类边界
$\begin{cases} g(z)\ge 0 & \text{,} z \ge 0.5 \\ \theta ^{T}X \ge 0 & \text{,} g(\theta ^{T}X) \ge 0.5 \end{cases}$
$\begin{cases} g(z)\le 0 & \text{,} z \le 0.5 \\ \theta ^{T}X \le 0 & \text{,} g(\theta ^{T}X) \le 0.5 \end{cases}$
4 二项逻辑斯谛回归模型
二项逻辑斯谛回归模型是如下的条件概率分布:
$P( Y = 1 |x) = \dfrac{1}{1+e^{-(w \cdot x + b )}}$
$\quad\quad\quad\quad\quad= \dfrac{e^{(w \cdot x + b )}}{( 1+e^{-(w \cdot x + b )}) \cdot e^{(w \cdot x + b )}}$
$\quad\quad\quad\quad\quad= \dfrac{e^{(w \cdot x + b )}}{1+e^{( w \cdot x + b )}}$
$ P ( Y = 0 | x ) = 1- P ( Y = 1 | x )$
$\quad\quad\quad\quad\quad=1- \dfrac{e^{(w \cdot x + b )}}{1+e^{( w \cdot x + b )}}$
$\quad\quad\quad\quad\quad=\dfrac{1}{1+e^{( w \cdot x + b )}}$
其中,$x \in R^{n}$ 是输入,$Y \in \left\{ 0, 1 \right\}$ 是输出,$w \in R^{n}$ 和 $b \in R$ 是参数,$w$ 称为权值向量,$b$ 称为偏置,$w \cdot x$ 为 $w$ 和 $b$ 的内积。
可将权值权值向量和输入向量加以扩充,即$w = ( w^{(1)},w^{(2)},\cdots,w^{(n)},b )^{T}$,$x = ( x^{(1)},x^{(2)},\cdots,x^{(n)},1 )^{T}$,则逻辑斯谛回归模型:
$P ( Y = 1 | x ) = \dfrac{e^{(w \cdot x )}}{1+e^{( w \cdot x )}} $
$P ( Y = 0 | x ) =\dfrac{1}{1+e^{( w \cdot x )}}$
一个事件的几率是指事件发生的概率 $p$ 与事件不发生的概率 $1−p$的比值,即
$\dfrac{p}{1-p}$
该事件的对数几率(logit函数)
$logit( p ) = \log \dfrac{p}{1-p}$
对于逻辑斯谛回归模型
$log \dfrac{P ( Y = 1 | x )}{1-P ( Y = 1 | x )} = w \cdot x$
即输出 $Y=1$ 的对数几率是输入$x$ 的线性函数。
观察上式可得:若将 $P ( Y = 1 | x )$ 视为样本 $x$ 作为正例的可能性,则 $1-P ( Y = 1 | x )$ 便是其反例的可能性。二者的比值便被称为“几率”,反映了 $x$ 作为正例的相对可能性,这也是logistic回归又被称为对数几率回归的原因。
5 模型参数估计
逻辑斯蒂回归模型学习时,对于给定的训练数据集 $T = \{ ( x_{1}, y_{1} ), ( x_{2}, y_{2} ), \cdots, ( x_{N}, y_{N} ) \} $
其中,$x_{i} \in R^{n+1}, y_{i} \in \left\{ 0, 1 \right\}, i = 1, 2, \cdots, N$。
设:
$ P ( Y =1 | x ) = \pi ( x ) ,\quad P ( Y =0 | x ) = 1 - \pi ( x )$
似然函数
$l ( w ) = \prod_ \limits {i=1}^{N} P ( y_{i} | x_{i} ) $
$= P ( Y = 1 | x_{i} , w ) \cdot P ( Y = 0 | x_{i}, w ) $
$= \prod_ \limits {i=1}^{N} [ \pi ( x_{i} ) ]^{y_{i}}[ 1 - \pi ( x_{i} ) ]^{1 - y_{i}}$
对数似然函数
$L ( w ) = \log l ( w ) $
$= \sum_ \limits {i=1}^{N} [ y_{i} \log \pi ( x_{i} ) + ( 1 - y_{i} ) \log ( 1 - \pi ( x_{i} ) ) ]$
$= \sum_ \limits {i=1}^{N} [ y_{i} \log \dfrac{\pi ( x_{i} )}{1- \pi ( x_{i} )} + \log ( 1 - \pi ( x_{i} ) ) ]$
$= \sum_ \limits {i=1}^{N} [ y_{i} ( w \cdot x_{i} ) - \log ( 1 + \exp ( w \cdot x ) ) ]$
假设 $w$ 的极大似然估计值是 $\hat{w}$,则学得得逻辑斯谛回归模型
$P ( Y = 1 | x ) = \dfrac{e^{(\hat{w} \cdot x )}}{1+e^{( \hat{w} \cdot x )}}$
$P ( Y = 0 | x ) =\dfrac{1}{1+e^{( \hat{w} \cdot x )}}$
假设离散型随机变量 $Y$ 的取值集合 $\{ 1, 2, \cdots, K \}$,则多项逻辑斯谛回归模型
$P ( Y = k | x ) = \dfrac{e^{(w_{k} \cdot x )}}{1+ \sum_ \limits {k=1}^{K-1}e^{( w_{k} \cdot x )}}, \quad k=1,2,\cdots,K-1$
$P ( Y = K | x ) = 1 - \sum_ \limits {k=1}^{K-1} P ( Y = k | x )$
$= 1 - \sum_ \limits {k=1}^{K-1} \dfrac{e^{(w_{k} \cdot x )}}{1+ \sum_ \limits {k=1}^{K-1}e^{( w_{k} \cdot x )}}$
$= \dfrac{1}{1+ \sum_ \limits {k=1}^{K-1}e^{( w_{k} \cdot x )}}$
6 逻辑回归的损失函数
逻辑回归使用极大似然法来推导出损失函数。
根据逻辑回归的定义,假设样本输出是 $0$ 或者 $1$ 两类。那么有:
$P(y=1|x,\theta ) = h_{\theta}(x)$
$P(y=0|x,\theta ) = 1- h_{\theta}(x)$
把两种情况和一起就是如下公式:
$P(y|x,\theta ) = h_{\theta}(x)^y(1-h_{\theta}(x))^{1-y}$
得到了 $y$ 的概率分布函数表达式,就可以用似然函数最大化来求解需要的模型系数$\theta$。最大似然函数$L(\theta)$:
损失函数就是对数似然函数的负值
$J(\theta) = -lnL(\theta) = -\sum\limits_{i=1}^{m}(y^{(i)}log(h_{\theta}(x^{(i)}))+ (1-y^{(i)})log(1-h_{\theta}(x^{(i)})))$
7 逻辑回归的损失函数的优化方法
对于逻辑回归的损失函数极小化,有比较多的方法,最常见的有梯度下降法,坐标轴下降法,牛顿法等。
7.1 逻辑回归的正则化
逻辑回归也会面临过拟合问题,所以我们也要考虑正则化。常见的有L1正则化和L2正则化。
L1正则化形式:$J(\theta) = -lnL(\theta) + \alpha|\theta|$
L2正则化形式:$J(\theta) = -lnL(\theta) + \frac{1}{2}\alpha|\theta|^2$
8 总结
逻辑回归假设数据服从伯努利分布,在线性回归的基础上,套了一个二分类的Sigmoid函数,使用极大似然法来推导出损失函数,用梯度下降法优化损失函数的一个判别式的分类算法。逻辑回归的优缺点有一下几点:
8.1 优点
- 实现简单,广泛的应用于工业问题上;
- 训练速度较快。分类速度很快
- 内存占用少;
- 便利的观测样本概率分数,可解释性强;
8.2 缺点
- 当特征空间很大时,逻辑回归的性能不是很好;
- 一般准确度不太高
- 很难处理数据不平衡的问题
8.3 逻辑回归与线性回归
相同点:
- 两者都是广义线性模型GLM(Generalized linear models);
不同点:
- 线性回归要求因变量(假设为Y)是连续数值变量,而logistic回归要求因变量是离散的类型变量,例如最常见的二分类问题,1代表正样本,0代表负样本;
- 线性回归要求自变量服从正态分布,logistic回归对变量的分布则没有要求;
- 线性回归要求自变量与因变量有线性关系,Logistic回归没有要求;
- 线性回归是直接分析因变量与自变量的关系,logistic回归是分析因变量取某个值的概率与自变量的关系;
参考文献
2 logistic回归详解一:为什么要使用logistic函数
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/14897395.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号