机器学习——感知机
1 介绍
感知机是1957年,由Rosenblatt提出会,是神经网络和支持向量机的基础。
感知机 (Perceptron)是二分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取+1和-1。感知机对应于输入空间(特征空间)中将实例划为正负两类的分离超平面,属于判别模型。感知机预测是用学习得到的感知机模型对新的输入实例进行分类,是神经网络与支持向量机的基础。
2 感知机模型
2.1 点到直线的距离
设直线方程为 $Ax+By+C=0$ ,其上一点为 $(x_{0},y_{0})$
距离为 ${\large d=\frac{A*x_{0}+B*y_{0}+C}{\sqrt{A^{2}+B^{2}}}} $
2.2 样本到超平面距离
假设超平面是 $h=w\cdot x+b$ ,其中 $w=(w_{0}, w_{1}, w_{2}......w_{n})$, $x=(x_{0}, x_{1}, x_{2}......x_{n})$,样本点 $x' $ 到超平面的距离:${\large d=\frac{w*x^{'}+b}{||d||}} $ ,输入空间 $\mathbb{R}^n$ 。
在$2$维空间中的超平面是一条线,在$3$维空间中的超平面是一个平面。
2.3 函数模型
由输入空间到输出空间的如下函数被称为感知机:
$f(x)=\operatorname{sign}(w \cdot x+b)$
其中 $w$ 和 $b$ 属于感知机模型参数,$w \in R^{n}$ 叫作权值或权值向量(weight vector), $b \in R$ 叫作偏置 (bias) 。
$w \cdot x $ 为 $w$ 和 $x$ 的内积。 $ \operatorname{sign}$ 是符号函数,即
$\operatorname{sign}(x)=\left\{\begin{array}{l} +1, x \geq 0 \\ -1, x<0 \end{array}\right.$
感知机模型的假设空间定义在特征空间中的所有线性分类模型或线性分类器(linear classifier ) , 即函数集合
$\{f \mid f(x)=w \cdot x+b\}$
2.4 几何解权
感知机有如下几何解释:线性方程
$w \cdot x+b=0$
对应于特征空间中的超平面 $S$ ,其中 $\mathbf{w} $ 是超平面的法向量, $ \mathbf{b} $ 为截距,超平面 $S$ 将特征向量分为正、 负两类, $S$ 也被称为分离超平面 。【PS:在二维空间是一条线,上开至多维度则为平面。】

思考1:在这里为什么 $w$ 是超平面法向量?
证明:超平面为 $w \cdot x+b=0$ ,设超平面上两点 $x_1$,$x_2$ 两点,则有
$\left\{\begin{matrix} \mathbf{w \cdot x_1} =0 \quad...(1)\\ \mathbf{w \cdot x_2} =0\quad...(2) \end{matrix}\right.$
由 $(1)-(2)$ 得:
$\left\{\begin{matrix} \mathbf{w\cdot( x_1-x_2)} =0 \\ \mathbf{x_1} -\mathbf{x_2} =\mathbf{x_2x_1 } \end{matrix}\right.$
则
$\mathbf{w}$ 与 $ \mathbf{x_2x_1}$ 垂直。
训练感知机模型就是通过训练集数据学习参数 $w$ 和 $b$ ,然后训练好的感知机模型就能对新的输入实例进行类别的预测。
3 感知机学习策略
3.1 数据集的线性可分性
给定数据集 $T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\}$,其中$ x_{i} \in \mathcal{X}=\mathbf{R}^{n}$, $y_{i} \in \mathcal{Y}=\{+1,-1\}$,$i=1,2, \cdots, N $,如果存在某个超平面 $S$ 满足:
$w \cdot x+b=0$
能将数据集的正实例点和负实例点完全正确地划分到超平面的两侧,即对所有 $y_{i}=+1$ 的实例 $x_i$,有 $ w \cdot x_{i}+b>0$ ;对所有 $y_{i}=-1$ 的实例 $x_i$,有 $w \cdot x_{i}+b<0 $,则 称数据集 $T$ 为线性可分数据集 ;否则,称数据集 $T$ 线性 不可分。
在学习感知机模型中,需要确保数据集线性可分,才能够找到一个完全将正实例点和负实例点正确分开的分离超平面,即才能够确定感知机模型参数 $w,b$。
3.2 感知机学习策略
在我们知道感知机模型之后,机器学习方法三要素中的模型已经确定好,下面就需要制定我们的学习策略,即定义经验损失函数并将其最小化。所以下一步需要找到感知机模型的损失函数。
3.2.1 基于误分类点数量的策略
首先损失函数容易想到采用误分类点的数量作为损失函数,因为误分类点数量在不断优化下会越来越少,我们只需要通过算法将其数目优化到 $ 0$ 自然就得到了最优模型。
但是这样的损失函数并不是 $w, b$ 连续可导(根本无法用函数形式来表达出误分类点的个数),所以无法进行优化。
因此采取误分类点到平面的总距离作为损失函数,直观上来看,总距离越小越好。
3.2.2 基于误分类点总距离的策略
首先,输入空间中任意一点到超平面的距离公式为: (类比于点到直线的距离)
$\frac{1}{\|w\|}\left|w \cdot x_{0}+b\right|$
这里, $\|w\| $ 为 $w$ 的 L2范数。
而我们知道每一个误分类点都满足:
$-y_{i}\left(w \cdot x_{i}+b\right)>0$
因为当数据点正确值为 $+1$ 的时候,误分类了,那么判断为 $-1$,则有 $ \left(w \cdot x_{i}+b\right)<0 $, 所以满足 $-y_{i}\left(w \cdot x_{i}+b\right)>0 $,当数据点是正确值为 $-1$ 的时候,误分类了,那么判断为 $+1$,则有 $ \left(w \cdot x_{i}+b\right)>0$,所以满足 $ -y_{i}\left(w \cdot x_{i}+b\right)>0 $。
表2.1 关系表

因此,一个误分类点到超平面 $S$ 的距离为:
${\large -\frac{1}{|| w \mid} y_{i}\left(w \cdot x_{0}+b\right)} $
然后,因为求的是总距离,所以假设误分类点集合为 $M$,那么总距离为:
${\large -\frac{1}{\|w\|} \sum \limits _{x_{i} \in M} y_{i}\left(w \cdot x_{0}+b\right)} $
最后,不考虑 $\frac{1}{\|w\|}$ , 求得最终的感知机损失函数即经验风险函数:
$L(w, b)=-\sum \limits _{x_{i} \in M} y_{i}\left(w \cdot x_{0}+b\right)$
总结一下,我们现在的工作已经将感知机模型确定,并且需要一个学习策略来不断的学习参数 $w$ 和 $b$,但是误分类点数量不可求导,因此我们选择了一个连续可导的损失函数即误分类点到超平面 的总距离作为我们的损失函数。
思考2:为什么了不用考虑 ${\large \frac{1}{\left \| w\right \|}} $?
1、${\large \frac{1}{\left \| w\right \|}} $ 不影响 $y_i(w\cdot {x_i}+b)$ 的正负判断,由于感知机算法是误分类驱动,这里的"误分类驱动"指的是只需要判断 $y_i(w\cdot {x_i}+b)$ 的正负,而 ${\large \frac{1}{\left \| w\right \|}} $ 对正负不影响。
2、${\large \frac{1}{\left \| w\right \|}} $ 不影响感知机算法的最终结果。感知机算法的终止条件是所有的输入输出都被正确分类,即不存在误分类点,最终损失为 $0$ 。对于 损失函数 $-\frac{1}{\left \| w \right \|} \sum \limits_{x_i\in M} y_i (w\cdot x_i+b)$,可以看出分子为 $0$,${\large \frac{1}{\left \| w\right \|}} $ 对分子并无影响。
总结:不考虑 ${\large \frac{1}{\left \| w\right \|}} $ 可以减少计算量,对感知机算法无任何影响。
4 感知机学习算法
感知机学习算法是对上述损失函数进行极小化,求得 $w$ 和 $ b$。用普通的基于所有样本的梯度和的均值的批量梯度下降法(BGD)是行不通的,原因在于我们的损失函数里面有限定,只有误分类的 $M$ 集合里面的样本才能参与损失函数的优化。所以我们不能用最普通的批量梯度下降,只能采用随机梯度下降(SGD)。目标函数如下:
$\underset{w,b}{min} \ \ L(w, b)=-\sum \limits _{x_{i} \in M} y_{i}\left(w \cdot x_{i}+b\right)$
4.1 原始形式算法
求参数 $ \mathrm{w}, \mathrm{b} $,求以下损失函数极小化问题的解:
$ {\large \underset{w,b}{min} \ \ L(w, b)=-\sum \limits _{x_{i} \in M} y_{i}\left(w \cdot x_{i}+b\right)} $
因为我们需要不断学习 $\mathrm{w} , \mathrm{b}$ ,因此我们采取随机梯度下降法不断优化目标函数,在这里,随机梯度下降过程中,每一次仅用一个误分类点样本来使其梯度下降。
首先,我们求解梯度,分别对 $\mathrm{w} , \mathrm{b}$ 求偏导:
$\begin{array}{l} \nabla_{w} L(w, b)=\frac{\partial}{\partial w} L(w, b)=-\sum \limits _{x_{i} \in M} y_{i} x_{i} \\ \nabla_{b} L(w, b)=\frac{\partial}{\partial b} L(w, b)=-\sum \limits_{x_{i} \in M} y_{i} \end{array}$
然后,随机选取一个误分类点对 $w , b$ 进行更新: (同步更新)
$w \leftarrow w+\eta y_{i} x_{i}$
$b \leftarrow b+\eta y_{i}$
其中,$ \eta $ 为学习率,通过这样迭代使损失函数 $\mathrm{L}(\mathrm{w}, \mathrm{b}) $ 不断减小,直至最小化。
算法步骤
输入:训练数据集 $T={(x_1,y_1),(x_2,y_2),...,(x_N,y_N)}$,$y_i\in{\{-1,+1\}}$,学习率 $\eta(0<\eta<1)$
输出:$w$ 和 $b$; 感知机模型 $f(x)=sign(w\cdot {x}+b)$
步骤:
(1)、赋初值 $w_0$,$b_0$ ;
(2)、选取数据点 $(x_i,y_i)$ ;
(3)、判断该数据点是否为当前模型的误分类点,即判断若 $y_i(w\cdot {x_i}+b)<=0$ 则更新
$w={w+\eta{y_ix_i}}$
$b={b+\eta{y_i}}$
(4)、转到(2),直到训练集中没有误分类点。
其中,$w$ 和 $b$ 的初值一般选择为 $0$,方便计算。根据算法,我们很容易能够编写出 Python程序,重点关注循环迭代。
代码实战:
import numpy as np
class Model:#定义感知机学习类
def __init__(self):
#构造时初始值化w = (0 ,0), b = 0
self.w = np.zeros(len(data[0]) - 1,dtype=np.float32) #初始化参数 w , b,和学习率
self.b = 0
#学习率=1
self.l_rate = 100# self.data = data
def sign(self,x, w,b):
#定义感知机模型函数
y = np.dot(x,w) + b
return y
#随机梯度下降法
def fit(self, X_train, y_train):
is_wrong = False #判断是否有误分类点
while not is_wrong:
wrong_count = 0 #记录误分类点数目
for d in range( len( X_train) ):
x= X_train[d]
y = y_train[d]
#选取—个点进行判断
if y * self.sign(x, self.w,self.b)<=0: #判断是不是误分类点的标志
self.w = self.w + self.l_rate * np.dot(y,x)#更新参数
self.b = self.b + self.l_rate * y
wrong_count += 1 #误分类点数目加一
if wrong_count == 0:
is_wrong = True #没有误分类点
return ' Perceptron Model! '
4.2 算法收敛性
4.2.1 Novikoff定理
为了便于叙述与推导,将偏置 $b$ 并入权重向量 $w$ ,记作 $\hat{w}=(w^{\mathrm{T}}, b)^{\mathrm{T}}$ 同样也将输入向量加以扩充,加进常数 $1$,记作 $\hat{x}=(x^{\mathrm{T}}, 1)^{\mathrm{T}} $ 这样, $\hat{x} \in \mathbf{R}^{n+1}, \hat{w} \in \mathbf{R}^{n+1} $。显然,$ \hat{w} \cdot \hat{x}=w \cdot x+b_{c} $
定理 2.1 (Novikoff) 设训练数据集 $T=\{(x_{1}, y_{1}),(x_{2}, y_{2}),\cdots,(x_{N}, y_{N})\} $ 是线性可分的,其中 $ x_{i} \in \mathcal{X}=\mathbf{R}^{n}, y_{i} \in \mathcal{Y}=\{-1,+1\}, i=1,2, \cdots, N$ ,则
(1)存在满足条件 $ \|\hat{w}_{\mathrm{opt}}\|=1$ 的超平面 $\hat{w}_{\mathrm{opt}} \cdot \hat{x}=w_{\mathrm{opt}} \cdot x+b_{\mathrm{opt}}=0$ 将训练数据集完全正确分开;且存在 $\gamma>0$ , 对所有 $ i=1,2, \cdots, N $
$y_{i}(\hat{w}_{\mathrm{opt}} \cdot \hat{x}_{i})=y_{i}(w_{\mathrm{opt}} \cdot x_{i}+b_{\mathrm{opt}}) \geqslant \gamma$
(2)令 $R=\max _{1 \leqslant i \leqslant N}\|\hat{x}_{i}\|$ , 则感知机算法 2.1 在训练数据集上的误分类次数 $k$ 满足 不等式
$k \leqslant(\frac{R}{\gamma})^{2}$
根据这两个定理可知,只要对于线性可分的数据集,感知机学习算法原始形式就能够在有限次的 迭代更新中能够得到一个能正确划分的分离超平面和感知机模型。
4.2.2 定理证明
定理(1):
这个定理的证明较为简单,首先数据集线性可分,按照之前线性可分性定义,那我们就必然能够找到一个超平面将数据正确分开。
令超平面为:
$\hat{w}_{\mathrm{opt}} \cdot \hat{x}=w_{\mathrm{opt}} \cdot x+b_{\mathrm{opt}}=0, \text { 使 }\|\hat{w}_{\mathrm{opt}}\|=1$
思考3: 为什么 $ \|\widehat{w}_{o p t}\|=1$ ?
法向量可以任意伸缩,所以总可以找到 $w_{opt}$ 的模长$=1$,并且方便计算。
权重向量 $w$ 会和 $x$ 向量相乘组成一个超平面$w^Tx=0$。这里权重向量 $w$ 即为超平面的系数向量。而将系数向量除以其范数 (即转换为单位向量) 不会改变这个超平面,就像是 $2 x+2 y+1=0$ 与 $ 2 / 3 x+2 / 3 y+1 / 3=0 $ 表示同一个直线。
接下来又因为下列式子是在原本的分类点上永远是一个非负数,因为 $y$ 是正分类的时候,那么括号中的 表达式也是非负的(线性可分性定义)
$y_{i}(\hat{w}_{\mathrm{opt}} \cdot \hat{x}_{i})=y_{i}(w_{\mathrm{opt}} \cdot x_{i}+b_{\mathrm{opt}})>0$
所以我们就能够在上述非负数集合中找到一个最小的非负数,如下:
所以存在
$\gamma=\min _{i}\{y_{i}(w_{\mathrm{opt}} \cdot x_{i}+b_{\mathrm{opt}})\}$
使
$y_{i}(\hat{w}_{\mathrm{opt}} \cdot \hat{x}_{i})=y_{i}(w_{\mathrm{opt}} \cdot x_{i}+b_{\mathrm{opt}}) \geqslant \gamma$
定理 (2) :
(2) 感知机算法从 $\hat{w}_{0}=0$ 开始,如果实例被误分类,则更新权重。令 $\hat{w}_{k-1} $ 是第 $k$ 个误分类实例之前的扩充权重向量, 即
$\hat{w}_{k-1}=\left(w_{k-1}^{\mathrm{T}}, b_{k-1}\right)^{\mathrm{T}}$
首先总观全部推导过程我们需要证明两个不等式,才能得出最后的关于有限次的 $k$ 不等式:
不等式(1)
$\hat{w}_{k} \cdot \hat{w}_{\mathrm{opt}} \geqslant k \eta \gamma$
不等式(2)
$\left\|\hat{w}_{k}\right\|^{2} \leqslant k \eta^{2} R^{2}$
现在我们对于不等式(1)先把左边拆开成:
$\hat{w}_{k}=\hat{w}_{k-1}+\eta y_{i} \hat{x}_{i}$
然后将其代入不等式(1)得:
$\left(\tilde{w}_{k-1}+\eta y_{i} x_{i}\right) \cdot \tilde{w}_{o p t}$
进行运算,并根据定理 (1), 将 $y_{i} w_{\mathrm{opt}} \cdot x_{i}$ 替换,我们可以代换得到:
$\begin{aligned} \hat{w}_{k} \cdot \hat{w}_{\mathrm{opt}} &=\hat{w}_{k-1} \cdot \hat{w}_{\mathrm{opt}}+\eta y_{i} w_{\mathrm{opt}} \cdot x_{i} \\ & \geqslant \hat{w}_{k-1} \cdot \hat{w}_{\mathrm{opt}}+\eta \gamma \end{aligned}$
由上述结果递推我们可以得到下面不等式(因为采用的梯度下降, 所以反过来就会每一步增加 $1$ 个 $\eta$ , 总的增加$k$个$\eta Y)$:
$\hat{w}_{k} \cdot \hat{w}_{\mathrm{opt}} \geqslant \hat{w}_{k-1} \cdot \hat{w}_{\mathrm{opt}}+\eta \gamma \geqslant \hat{w}_{k-2} \cdot \hat{w}_{\mathrm{opt}}+2 \eta \gamma \geqslant \cdots \geqslant k \eta \gamma$
第一个不等式已经推导完毕并得到了一个不等式结果,下面我们开始不等式(2)的推导。由书上公 式 (2.11) 得:
$\left\|\tilde{w}_{k}\right\|^{2}=\left\|\tilde{w}_{k-1}+\eta y_{i} x_{i}\right\|^{2}$
然后平方和公式展开,由书上公式 (2.10) 得(其中$y_i$的平方为 $1$ 省去):
$\begin{aligned} \left\|\hat{w}_{k}\right\|^{2} &=\left\|\hat{w}_{k-1}\right\|^{2}+2 \eta \hat{w}_{k-1} \cdot \hat{x}_{i}+\eta^{2}\left\|\hat{x}_{i}\right\|^{2} \\ & \leqslant \left\|\hat{w}_{k-1}\right\|^{2}+\eta^{2}\left\|\hat{x}_{i}\right\|^{2} \\& \leqslant\left\|\hat{w}_{k-1}\right\|^{2}+\eta^{2} R^{2} \\ & \leqslant\left\|\hat{w}_{k-2}\right\|^{2}+2 \eta^{2} R^{2} \leqslant \cdots \\ & \leqslant k \eta^{2} R^{2} \end{aligned}$
最后,综合不等式(1)和(2),红色方框处利用柯西不等式的向量形式得:
$\begin{array}{l} k \eta \gamma \leqslant \hat{w}_{k} \cdot \hat{w}_{\mathrm{opt}} \leqslant\left\|\hat{w}_{k}\right\|\left\|\hat{w}_{\mathrm{opt}}\right\| \leqslant \sqrt{k} \eta R \\ k^{2} \gamma^{2} \leqslant k R^{2} \end{array}$
$k \leqslant\left(\frac{R}{\gamma}\right)^{2}$
所以,根据定理表明,误分类的次数 $k$ 是有上界的,经过有限次训练可以得到正确的分离超平面即当数据线性可分,感知机学习算法原始形式是收敛的。
4.3 对偶形式算法
对偶问题简单来说就是从一个不同的角度去解答相似问题,但是问题的解是相通的。在这里感知机的对偶形式是将 $w$ 和 $b$ 表示为了 $x_i$ 和 $y_i$ 的线性表示。
由于$w$、$b$ 的梯度更新公式:
$w={w+\eta{y_ix_i}}$
$b={b+\eta{y_i}}$
我们的 $w$、$b$,经过了 $n$ 次修改后的,参数可以变化为下公式,其中 $\alpha_{i}=n_{i} \eta$:
$w=\sum \limits_{x_i\in M}\eta{y_ix_i}=\sum \limits_{i=1}^n\alpha_iy_ix_i$
$b=\sum \limits_{x_i\in M}\eta{y_i}=\sum \limits_{i=1}^n\alpha_iy_i$
这样我们就得出了感知机的对偶算法。
可以理解为从原始形式中的不断更新参数 $w$ 和 $b$ 变成了学习某一点被误分类的次数$a_i$即 $n_i $ (第个点 由于误分进行更新的次数),并且在对偶形式中引入了$Gram$ 矩阵来存储内积,可以提高运算速度, 而反观原始形式,每次参数改变,所有的矩阵计算全部需要计算,导致计算量比对偶形式要大很多, 这就是对偶形式的高效之处。
$Gram$ 矩阵定义如下:
$G=\left[\begin{array}{cccc} x_{1} x_{1} & x_{1} x_{2} & \ldots & x_{1} x_{N} \\ x_{2} x_{1} & x_{2} x_{2} & \ldots & x_{2} x_{N} \\ \ldots & \cdots & \ldots & \cdots \\ x_{N} x_{1} & x_{N} x_{1} & \ldots & x_{N} x_{N} \end{array}\right]$
输入:训练数据集$T={(x_1,y_1),(x_2,y_2),...,(x_N,y_N)}$,$y_i\in{\{-1,+1\}}$,学习率$\eta(0<\eta<1)$
输出:$\alpha,b$ ;感知机模型$f(x)=sign(\sum \limits_{j=1}^n\alpha_jy_jx_j\cdot {x}+b)$ ,其中$\alpha=(\alpha_1,\alpha_2,...,\alpha_n)^T$
步骤:
1、赋初值$\alpha_0,b_0$ 。
2、选取数据点$(x_i,y_i)$。
3、判断该数据点是否为当前模型的误分类点,即判断若$y_i(\sum \limits_{j=1}^n\alpha_jy_jx_j\cdot {x_i}+b)<=0$则更新
$\alpha_i={\alpha_i+\eta}$
$b={b+\eta{y_i}}$
4、转到2,直到训练集中没有误分类点
为了减少计算量,我们可以预先计算式中的内积,得到Gram矩阵
$G=[x_i,x_j]_{N×N}$
代码:
def fit( self,X,y):
#权重和偏置初始化
self.alpha = np.zeros ( X.shape[0])
self.b =0
train_complete_flag = False
Gram = np.dot(X, X.T) #存放样本两两内积的Gram矩阵(特点)
while not train_complete_flag:
error_count = 0
for i in range ( X.shape[0]):
x_, y_ = X[i],y[i]
#有—个点当分类错误时,更新alpha_i和偏置
tmp_sum = np.dot(np.multiply(self.alpha,y),Gram[ :, i])
#进行误分类点判断
if y_* (tmp_sum+ self.b) <= 0:
self.alpha[i] += self.lr
self.b += self.lr * y_
error_count += 1
if not error_count:
train_complete_flag = True#训练完成后计算权重
self.w = np.dot(np.multiply (self.alpha,y),X)
4.4 原始形式和对偶形式的选择
- 在向量维数(特征数)过高时,计算内积非常耗时,应选择对偶形式算法加速。
- 在向量个数(样本数)过多时,每次计算累计和就没有必要,应选择原始算法
5 训练过程
我们大概从下图看下感知机的训练过程。
线性可分的过程:
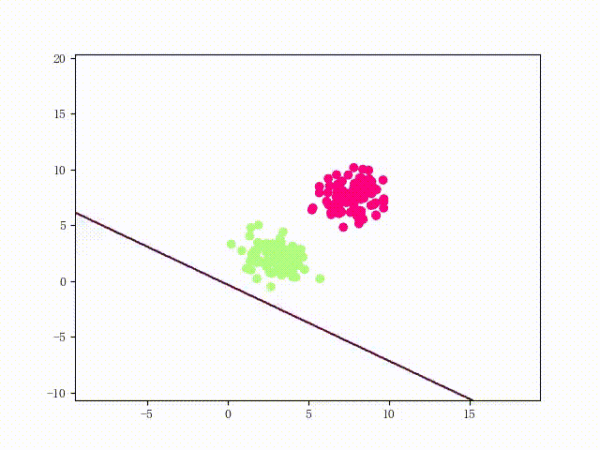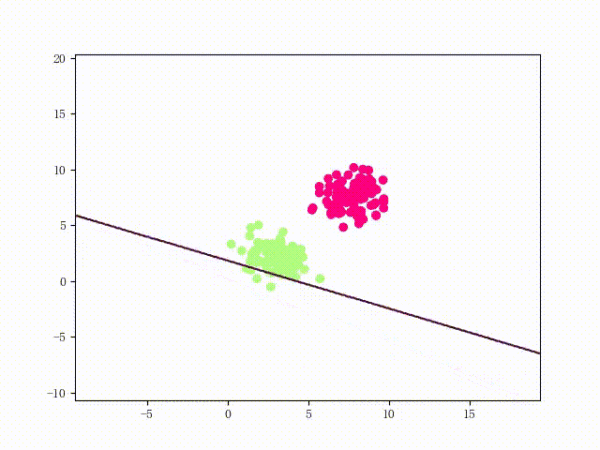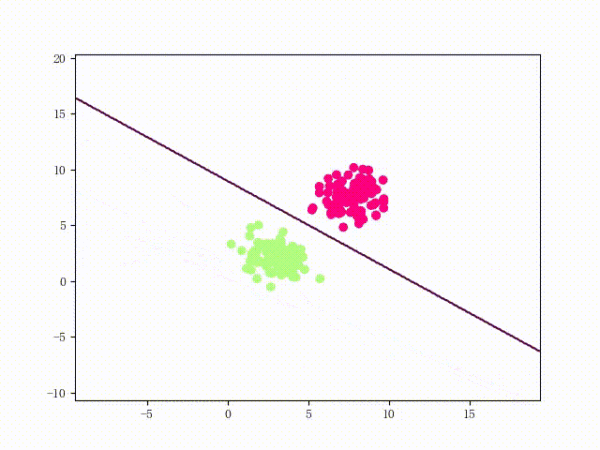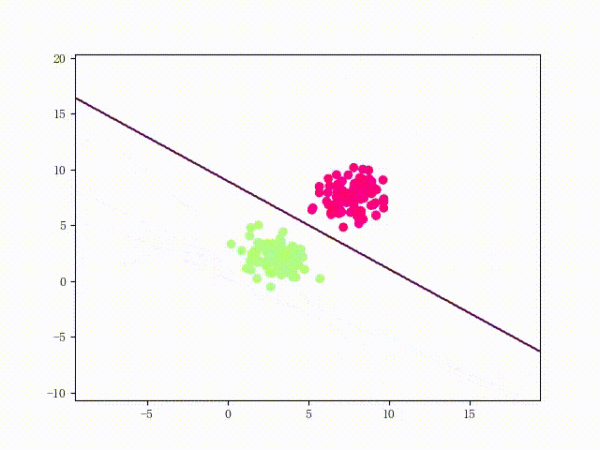
线性不可分的过程:

6 编程实现
例子:如图所示,正实例点是$x_1=(3,3)^T , x_2=(4,3)^T$,负实例点是$x_3=(1 , 1)^T$,,使用感知机算法求解感知机模型 f(x)=sign(w⋅x+b) 。这里$w = (w^{(1)},w^{(2)}),x=(x^{(1)},x^{(2)})$
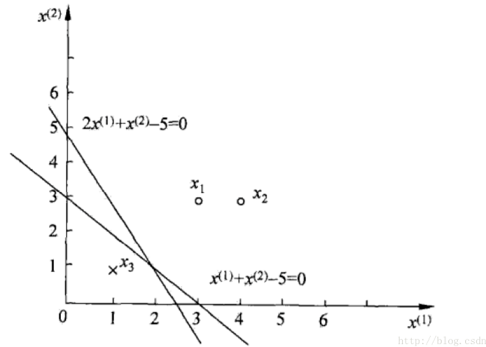
这里我们取初值$w_0=0,b_0=0$取$\eta=1$
原始形式代码如下:


train = [[(3, 3), 1], [(4, 3), 1], [(1, 1), -1]]
w = [0, 0]
b = 0
# 使用梯度下降法更新权重
def update(data):
global w, b
w[0] = w[0] + 1 * data[1] * data[0][0]
w[1] = w[1] + 1 * data[1] * data[0][1]
b = b + 1 * data[1]
print(w, b)
# 计算到超平面的距离
def cal(data):
global w, b
res = 0
for i in range(len(data[0])):
res += data[0][i] * w[i]
res += b
res *= data[1]
return res
# 检查是否可以正确分类
def check():
flag = False
for data in train:
if cal(data) <= 0:
flag = True
update(data)
if not flag:
print("The result: w: " + str(w) + ", b: "+ str(b))
return False
flag = False
for i in range(1000):
check()
if check() == False:
break
可以得到如下结果:
[3, 3] 1
[2, 2] 0
[1, 1] -1
[0, 0] -2
[3, 3] -1
[2, 2] -2
[1, 1] -3
The result: w: [1, 1], b: -3
对偶形式代码如下:
import numpy as np
train = np.array([[[3, 3], 1], [[4, 3], 1], [[1, 1], -1]])
a = np.array([0, 0, 0])
b = 0
Gram = np.array([])
y = np.array(range(len(train))).reshape(1, 3)# 标签
x = np.array(range(len(train) * 2)).reshape(3, 2)# 特征
# 计算Gram矩阵
def gram():
g = np.array([[0, 0, 0], [0, 0, 0], [0, 0, 0]])
for i in range(len(train)):
for j in range(len(train)):
g[i][j] = np.dot(train[i][0], train[j][0])
return g
# 更新权重
def update(i):
global a, b
a[i] = a[i] + 1
b = b + train[i][1]
print(a, b)
# 计算到超平面的距离
def cal(key):
global a, b, x, y
i = 0
for data in train:
y[0][i] = data[1]
i = i + 1
temp = a * y
res = np.dot(temp, Gram[key])
res = (res + b) * train[key][1]
return res[0]
# 检查是否可以正确分类
def check():
global a, b, x, y
flag = False
for i in range(len(train)):
if cal(i) <= 0:
flag = True
update(i)
if not flag:
i = 0
for data in train:
y[0][i] = data[1]
x[i] = data[0]
i = i + 1
temp = a * y
w = np.dot(temp, x)
print("The result: w: " + str(w) + ", b: "+ str(b))
return False
flag = False
Gram = gram()# 初始化Gram矩阵
for i in range(1000):
check()
if check() == False:
break
可以得到如下结果:
[1 0 0] 1
[1 0 1] 0
[1 0 2] -1
[1 0 3] -2
[2 0 3] -1
[2 0 4] -2
[2 0 5] -3
The result: w: [[1 1]], b: -3
7 小结
感知机算法是一个简单易懂的算法,自己编程实现也不太难。前面提到它是很多算法的鼻祖,比如支持向量机算法,神经网络与深度学习。因此虽然它现在已经不是一个在实践中广泛运用的算法,还是值得好好的去研究一下。感知机算法对偶形式为什么在实际运用中比原始形式快,也值得好好去体会。
参考文献:
1:点到直线的距离
因上求缘,果上努力~~~~ 作者:别关注我了,私信我吧,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/14791795.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号