卷积⽹络
什么是卷积网络?
卷积⽹络是指那些⾄少在⽹络的⼀层中使⽤卷积运算来替代一般的矩阵乘法运算的神经⽹络。
卷积运算
卷积操作是指对不同的数据窗口数据 (图像) ⽤一组固定的权重 (滤波矩阵,可以看做⼀个恒定的滤波器 Filter) 逐个元素相乘再求和 (做内积)。也可以⽤如下⽅式理解,如果想要低噪声估计,⼀种可⾏的⽅法是对得到的测量结果进行平均。可以认为时间上越近的测量结果越相关,所以采⽤⼀种加权平均的⽅法,对于最近的测量结果赋予更高的权重。
二维卷积运算
上⾯我们介绍了卷积运算的思想,但我们通常在卷积层中会使⽤更加直观的互相关 (Cross-correlation) 运算。例如,在⼆维卷积层中,⼀个⼆维输⼊数组 I 和⼀个⼆维核数组 K 通过互相关运算输出⼀个⼆维数组 O。如图所⽰,输⼊是⼀个⾼和宽均为 3 的⼆维数组,核数组 (也称卷积核或过滤器) 的⾼和宽分别为 2。因此,我们可以说输⼊数组形状为 (3, 3),卷积核窗⼜ (又称卷积窗⼜) 的形状为 (2, 2)。
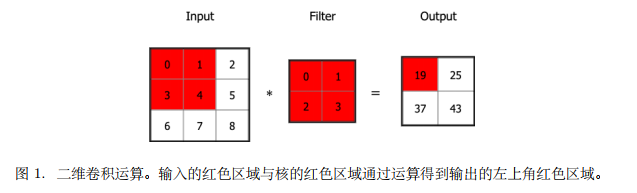
红⾊区域显⽰了第⼀个输出元素的计算过程:
0 × 0 + 1 × 1 + 3 × 2 + 4 × 3 = 19。
其他输出元素的计算过程同样可得:
1 × 0 + 2 × 1 + 4 × 2 + 5 × 3 = 25,
3 × 0 + 4 × 1 + 6 × 2 + 7 × 3 = 37,
4 × 0 + 5 × 1 + 7 × 2 + 8 × 3 = 43. (1)
卷积可交换
例如,如果把一张二维的图像 I 作为输入,我们也许也想要使用一个二维的核 K:
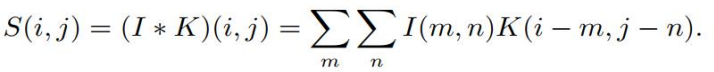
卷积是可交换的 (commutative),我们可以等价地写作:
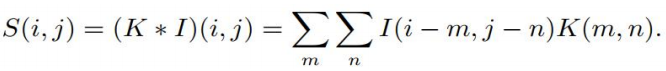
卷积运算可交换性的出现是因为我们将核相对输入进行了 翻转(flip),从 m 增大的角度来看,输入的索引增大,但是核的索引在减小。我们将核翻转的唯一目的是实现可交换性。
动机
卷积运算通过三个重要的思想来帮助改进机器学习系统:稀疏交互、参数共享、 等变表示。
参数共享(parameter sharing)
是指在一个模型的多个函数中使用相同的参数。在卷积神经网络中,核的每一个元素都作用在输入的每一位置上(是否考虑边界像素取决于对边界决策的设计)。卷积运算中的参数共享保证了我们只需要学习一个参数集合,而不是对于每一位置都需要学习一个单独的参数集合。
稀疏连接(Sparse Connectivity)

如图所示,m-1层作为输入层,hidden layer m中的输入是来自于m-1中的subset,每个单元units有着相同范围的receptive field。m层中的每个神经元的receptive field的宽度为3,能接受来自前一层3个神经元的输入,同理,在下一层m+1中,神经元同样接受来自m层3个神经元的输入,但是每个神经元对超出自己receptive field的神经元就不会产生连接,也就是不做出响应。我们可以发现一个特点,图中的每个神经元的receptive field的范围是相对的,对于相邻层,这个宽度为3,但是对于间隔一层的如m+1和m-1,这个值就变成了5。
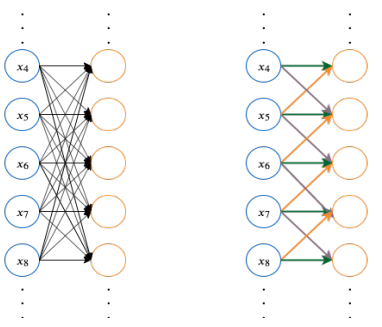
左图为前馈⽹络,右图为卷积⽹络展开。
在深度前馈⽹络中,权重矩阵 中的每一个元素只会使用一次,不会在不同的输⼊位置上共享参数。⽽在卷积操作中,卷积核的每一个元素都作用在输入的每一位置上。这个设计 保证了我们只需要学习⼀个参数集合 ,⽽不⽤对每⼀位置去学习⼀个单独的参数。这便是卷积的直觉,稀疏交互与参数共享 。前馈⽹络中每⼀个输出单元与每⼀个输⼊单元都产⽣交互,如果有 m 个输⼊和 n 个输出,那么矩阵乘法需要 m × n 个参数并且相应算法的时间复杂度为 O(m × n);卷积操作中如果我们限制每⼀个输出拥有的连接数为 k,那么稀疏的连接⽅法只需要 k × n 个参数以及 O(k × n) 的运⾏时间。
池化
在得到卷积特征后,下⼀步就是⽤来做分类。理论上,可以⽤提取到的所有特征训练分类器,但⽤所有特征的计算量开销会很⼤,⽽且也会使分类
器倾向于过拟合。为了解决这个问题,考虑到要描述⼀个⼤图像,⼀个⾃然的⽅法是在不同位置处对特征进⾏汇总统计。例如,可以计算在图像中某⼀区域的⼀个特定特征的平均值 (或最⼤值),这样概括统计出来的数据,其规模 (相⽐使⽤提取到的所有特征) 就低得多,同时也可以改进分类结果 (使模型不易过拟合)。这样的聚集操作称为 “池化”。池化可以保留显著特征,降低特征规模。
池化运算
池化函数是使⽤某⼀位置的相邻输出的总体统计特征来代替⽹络在该位置的输出。
• 最大池化函数 (Max Pooling) 给出相邻矩形区域内的最⼤值;
• 平均池化 (Average Pooling) 计算相邻矩形区域内的平均值;
• 其他常⽤的池化函数包括 L2 范数以及基于距中⼼像素距离的加权平均函数。
如图 3 所⽰,我们展⽰最⼤池化的运算过程:
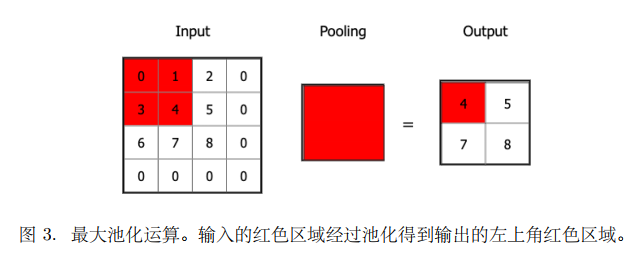
max(0, 1, 3, 4) = 4,
max(2, 0, 5, 0) = 5,
max(6, 7, 0, 0) = 7,
max(8, 0, 0, 0) = 8. (2)
不管采⽤什么样的池化函数,当输⼊作出少量平移时,池化能够帮助输⼊的表⽰近似不变。平移的不变性是指当我们对输⼊进⾏少量平移时,经过池化函数后的⼤多数输出并不会发⽣改变。局部平移不变性是⼀个很有⽤的性质,尤其是当我们关心某个特征是否出现而不关心它出现的具体位置时,后⽂我们会对这⼀性质进⼀步描述。
平移不变性
简单地说,卷积+最大池化约等于平移不变性。
卷积:简单地说,图像经过平移,相应的特征图上的表达也是平移的。输入图像的左下角有一个人脸,经过卷积,人脸的特征(眼睛,鼻子)也位于特征图的左下角。
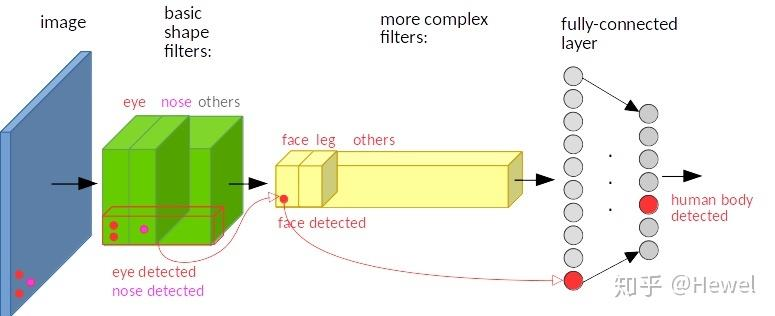
假如人脸特征在图像的左上角,那么卷积后对应的特征也在特征图的左上角。
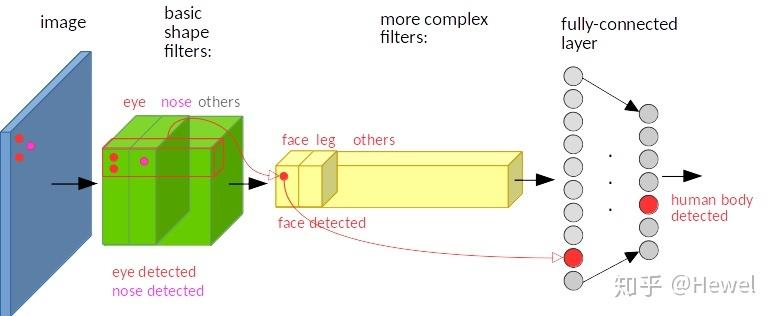
在神经网络中,卷积被定义为不同位置的特征检测器,也就意味着,无论目标出现在图像中的哪个位置,它都会检测到同样的这些特征,输出同样的响应。比如人脸 被移动到了图像左下角,卷积核直到移动到左下角的位置才会检测到它的特征。
卷积与池化作为一种无限强的先验: 先验的强或者弱取决于先验中概率密度的集中程度:弱先验具有较⾼的熵值,例如⽅差很⼤的⾼斯分布,这样的先验允许数据对于参数的改变具有 或多 或少的⾃ 由性;强先验具有较低的熵值,例如⽅差很⼩的⾼斯分布,这样的先验在决定参数最终取值时起着更加积极的作⽤;⽆限强的先验需 要对⼀些 参数的概率置零并 且完全禁⽌对这些参数赋值,⽆论数据对于这些参数的值给出了多⼤的⽀持。因此,我们可以把卷积的使⽤当作是对⽹ 络中⼀层的参 数引⼊了⼀个⽆限强的先验 概率分布,要求该层学到的函数只能包含局部连接关系并且对平移具有等变性。
深度学习框架下的卷积
多个并行卷积
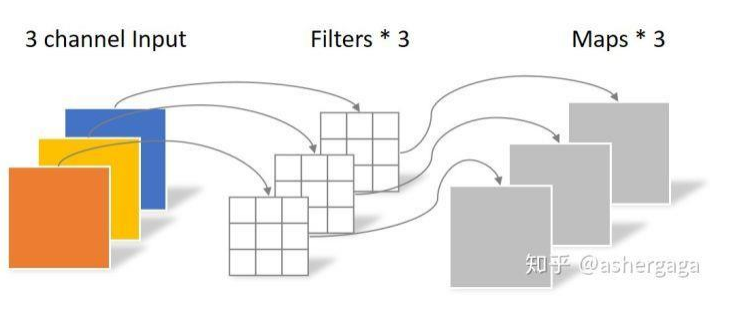
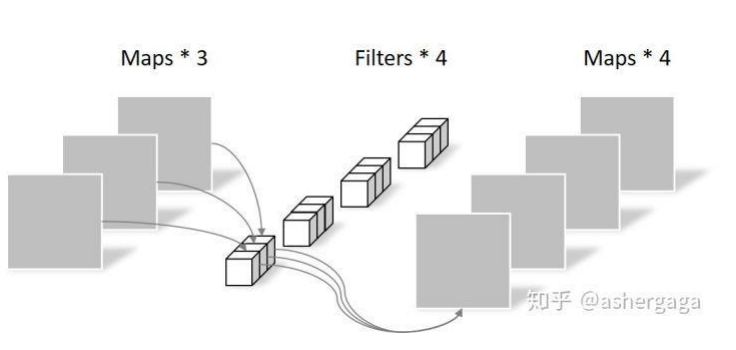
通常指由多个并⾏卷积组成的运算,可以在每个位置提取多种类型的特征。
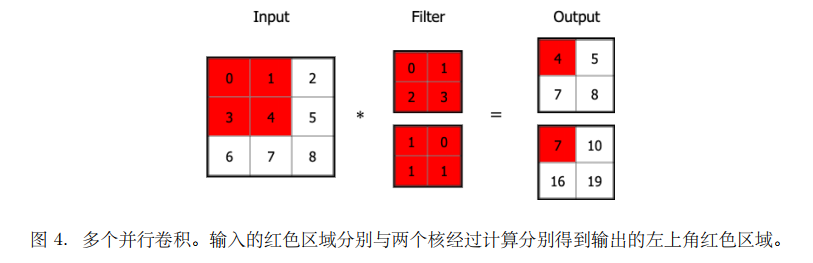
如图 4 所⽰,我们可以⽤两组卷积核去提取不同的特征。
输入值与核
输⼊通常也不仅仅是实值的⽹格,⽽是由⼀系列向量的⽹格,如⼀幅彩⾊图像在每⼀个像素点都会有红绿蓝三种颜⾊的亮度。当处理图像时,通常 把卷积的输⼊输出都看作是 3 维的张量,其中⼀个索引⽤于标明不同的通道 (例如 RGB),另外两个索引标明在每个通道上的空间坐标。我们可以 将输⼊图像数组写作 V,它的每⼀个元素是 Vi,j,k ,表⽰处在通道 k 中第 i ⾏第 j 列的值。
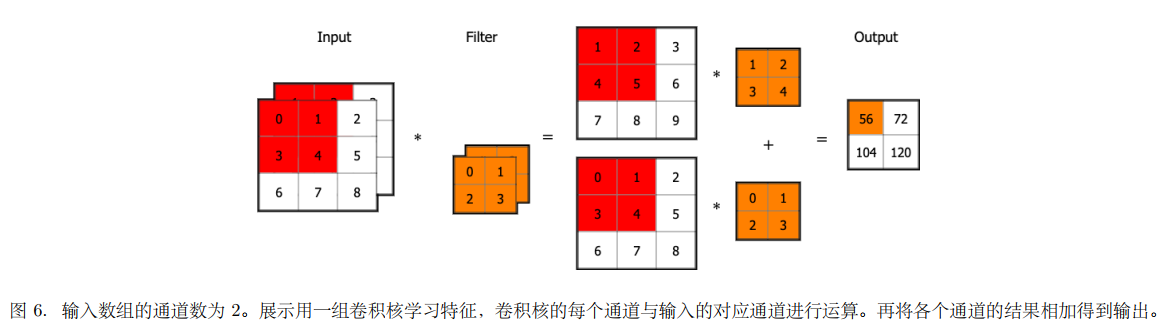
如下图所⽰,V 有 3 个通道,每个通道的形状均为 (3, 3)。 此时,我们还要定义卷积核数组 K,它的每⼀个元素是 Ki,j,k,l,表⽰处在第 l 组卷积核通道 k 中第 i ⾏第 j 列的值。如图 5 所⽰,我们假设卷积 核窗⼜的形状为(2, 2),因为输⼊通道为3,于是我们要对每个通道都定义⼀个卷积核,同时我们构造两组卷积核实现并⾏卷积,所以 K 的形状为 (2, 2, 3, 2)。
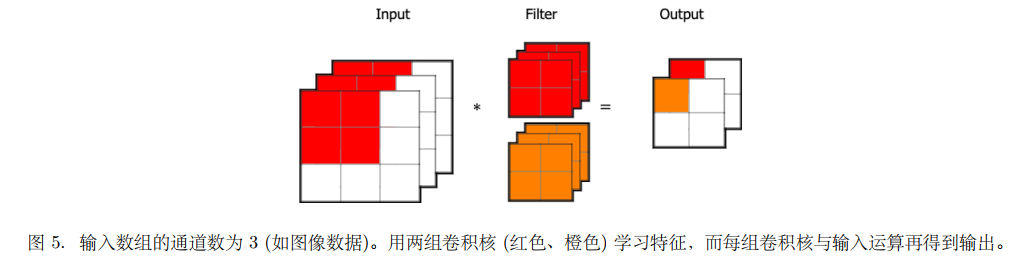
我们再看⼀下是如何获得输出 Z 值的,我们⽤ 1 组卷积核,并且以输⼊为 2 通道为例,如下图 6,Zi,j,l = ∑m,n,k Vi+m,j+n,k Km,n,k,l 。
填充 (Padding)
假设输⼊图⽚的⼤⼩为 (m, n),⽽卷积核的⼤⼩为 (f, f),则卷积后的输出图⽚⼤⼩为 (m−f + 1, n−f + 1),由此带来两个问题:
• 每次卷积运算后,输出图⽚的尺⼨缩⼩。
• 原始图⽚的⾓落、边缘区像素点在输出中采⽤较少,输出图⽚丢失很多边缘位置的信息。
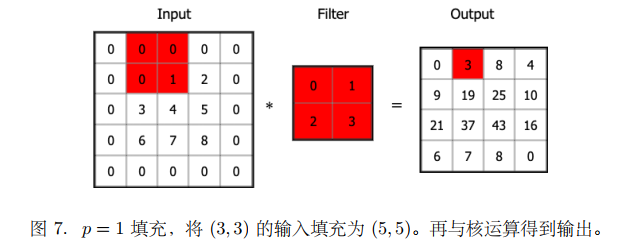
因此可以在进⾏卷积操作前,对原始图⽚在边界上进⾏填充 (Padding),以增加矩阵的⼤⼩,通常将 0 作为填充值。
设每个⽅向扩展像素点数量为 p,则填充后原始图⽚的⼤⼩为 (m + 2p, n + 2p),卷积核⼤⼩保持 (f, f) 不变,则输出图⽚⼤⼩ (m + 2p−f + 1, n +2p−f + 1)。
常⽤填充的⽅法有:
• 有效 (valid) 卷积,不填充,直接卷积,结果⼤⼩为 (m − f + 1, n−f + 1)。
• 相同 (same) 卷积,⽤ 0 填充,并使得卷积后结果⼤⼩与输⼊⼀致,这样 p = (f−1)/2。
• 全 (full) 卷积,通过填充,使得输出尺⼨为 (m + f − 1, n + f − 1)。
我们将之前的例⼦⽤ p = 1 填充,如图 7 所⽰。
卷积步幅 (Stride)
除了需要通过填充来避免信息损失,有时也需要通过设置步幅 (Stride) 来压缩⼀部分信息。步幅表⽰核在原始图⽚的⽔平⽅向和垂直⽅向上每次移动的距离。使⽤卷积步幅,跳过核中的⼀些位置 (看作对输出的下采样) 来降低计算的开销。如图 8 所⽰,在⾼上步幅为 3、在宽上步幅为 2 的卷积操作。当输出第⼀列第⼆个元素时,卷积窗⼜向下滑动了 3 ⾏,⽽在输出第⼀⾏第⼆个元素时卷积窗⼜向右滑动了 2 列。通常我们设置在⽔平⽅向和垂直⽅向的步幅⼀样,如果步幅设为 s,则输出尺⼨为

图 8. 考虑步幅下的卷积运算,在⾼上步幅为 3、在宽上步幅为 2。核第⼆步与输⼊的红⾊区域运算得到输出的右上⾓红⾊区域,第三步与输⼊的橙⾊区域运算得到输出的左下⾓橙⾊区域。
更多的卷积策略
深度可分离卷积 (Depthwise Separable Convolution)
如图所⽰,对输⼊ 3×3×2 的数组,经过 4 组 2×2×2 的卷积核,得到 2×2×4 的输出。这⾥我们⼀共需要 2×2×2×4=32 个参数。我们使⽤深度可分离卷积,它将卷积过程分成两个步骤。第⼀步,在 Depthwise Convolution,输⼊有⼏个通道就设⼏个卷积核,如图 9 所⽰,输⼊⼀共 2 个通道,对每个通道分配⼀个卷积核,这⾥的每个卷积核只处理⼀个通道 (对⽐原始卷积过程每组卷积核处理所有通道);第⼆步,在 Pointwise Convolution,由于在上⼀步不同通道间没有联系,因此这⼀步⽤ 1×1 的卷积核组来获得不同通道间的联系。我们可以看出,在深度可分离卷积中,我们⼀共需要2×2×2+1×1×2×4=16 个参数。
更形式化的,我们假设:
• 输⼊尺⼨:(Hin,Win, c1)
• 卷积核尺⼨:(K, K, c1)
• 输出尺⼨:(Hout,Wout, c2)
逐通道卷积
逐通道卷积(Depthwise Convolution) 的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,DW完全是在二维平面内进行。卷积核的数量与上一层的通 道数相同(通道和卷积核一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5),如下图所示。
其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下:
Ndepthwise = 3 × 3 × 3 = 27
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
逐点卷积
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加 权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:
Npointwise = 1 × 1 × 3 × 4 = 12
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同

分组卷积 (Group Convolution)
如图 10 所⽰,我们先考虑标准卷积,对输⼊为 3×3×4 的数组,经过 2 组 2×2×4 的卷积核,得到 2×2×2 的输出。这⾥我们⼀共需要 2×2×4×2=32个参数。我们将输⼊数组依据通道分为 2 组,每组需要 2×2×2 的卷积核就可以得到 2×2×1 的输出,拼接在⼀起同样得到 2×2×2 的输出。在这个分组卷积中,我们⼀共需要 2×2×2×2=16 个参数。
更形式化的,我们假设:
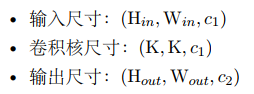
我们需要的标准卷积核参数量为 K × K × c1 × c2。在分组卷积中,假设被分为 g 组,则每⼀组输⼊的尺⼨为 (Hin,Win, c1/g),对应该组需要的卷积核组的尺⼨为 (K, K, c1/g, c2/g),输出尺⼨为 (Hout,Wout, c2/g)。最后,将 g 组的结果拼接在⼀起,最终得到 (Hout,Wout, c2) ⼤⼩的输出。在这个过程中,分组卷积需要的卷积核参数量为 K × K × (c1/g) × (c2/g) × g,是标准卷积的 1/g。
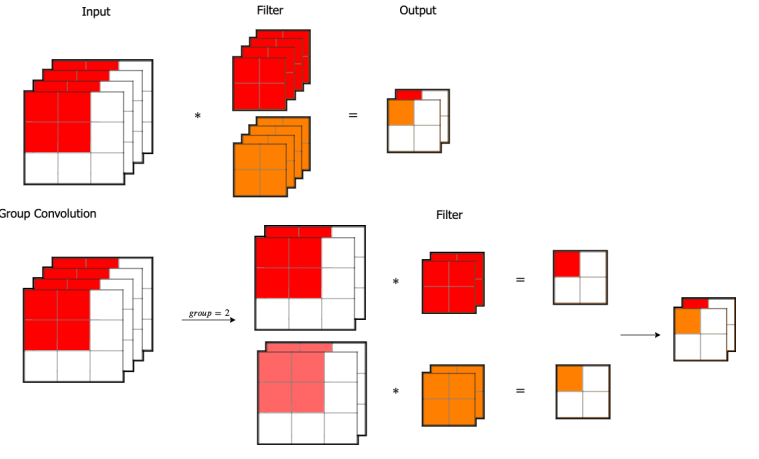
图 10. 上⽅显⽰了原始的卷积过程,构造两组通道数为 4 的卷积核组,经过运算得到输出。下⽅显⽰了分组卷积,将原始输⼊分为两组,每组通道数为 2。再分别经过⼀组通道数为 2 的卷积核。将分别得到的结果拼接得到最终输出。
扩张卷积 (Dilated Convolution)
扩张卷积,也称空洞卷积,它引⼊的参数被称为扩张率 (Dilation rate),其定义了核内值之间的间距。如图 11 所⽰,图中扩张速率为 2 的 3×3内核将具有与 5×5 内核相同的视野,但只使⽤ 9 个参数。这种⽅法能以相同的计算成本,提供更⼤的感受野。在需要更⼤的观察范围,且⽆法承受多个卷积或更⼤的内核,可以⽤它。
如果输⼊图⽚的⼤⼩为 (m, n),⽽卷积核的⼤⼩为 (f, f),每个⽅向扩展像素点数量为 p,步幅设为 s,则标准卷积输出尺⼨为
![]()
如果扩张率为 r,则扩张卷积输出尺⼨为
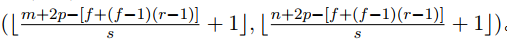
GEMM 转换
在前⾯介绍的⼆维卷积运算代码中我们会有 4 个 for 循环,这需要很⼤的时间开销,我们能否有更快的计算⽅法?
矩阵乘 (General Matrix Multiplication,GEMM) 是深度学习的核⼼。前⾯的全连接层是通过矩阵乘实现的,卷积层是否也可以这样实现?
卷积核是在输⼊图像上按步长滑动,每次滑动操作在输⼊图像上的对应窗⼜的区域,将卷积核中的各个权值 w∗ 与输⼊图像上对应窗⼜中的各个值x∗ 相乘,然后相加得到输出特征图上的⼀个值。卷积核对输⼊图像的每⼀次运算,可以看作是两个向量的内积,这意味着卷积操作完全可以转化为矩阵的乘法来实现。
我们将卷积层的卷积操作转化为卷积核的权值矩阵与输⼊数组转化的输⼊矩阵进⾏相乘。我们现在假设:
(原谅我太累了。。。。。。。。。。。。。。。)参考
卷积网络的训练
卷积的内部实现实际上是矩阵相乘,因此,卷积的反向传播过程实际上跟普通的全连接是类似的。
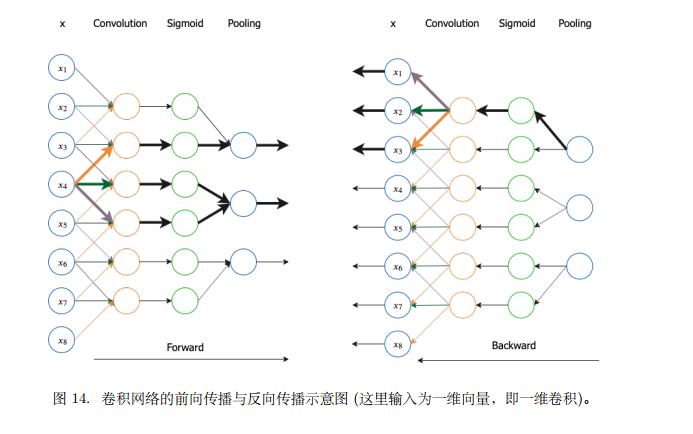
卷积网络示意图
CNN 的基本层包括卷积层和池化层,⼆者通常⼀起使⽤ (⼀个池化层紧跟⼀个卷积层之后)。这两层包括三个级联的函数:卷积,激励函数 (如sigmoid 函数),池化。其前向传播和后向传播的⽰意图如下:
因上求缘,果上努力~~~~ 作者:图神经网络,转载请注明原文链接:https://www.cnblogs.com/BlairGrowing/p/14505972.html

