搜索策略
Ch4 搜索策略
搜索的含义
搜索问题一般包括两个重要的问题:
- 搜索什么:通常指目标
- 在哪里搜索:即搜索空间,通常指一系列状态的汇集
搜索过程实际上是根据初始条件和扩展规则构造一棵解答树并寻找符合目标状态的节点的过程
启发式搜索:依靠经验,利用已有知识,根据问题的实际情况,不断寻找可利用知识,从而构造一条代价最小的推理路线,使问题得以解决的过程
典型问题:八数码
将每一个序列看作一个状态节点,将所有可能的状态节点看作一个状态空间,所有的操作构成一个算符空间,操作可以使状态转变,通过搜索算法在状态空间中寻找目标状态节点
- 要成功地设计和实现搜索算法, 必须把下列疑点弄清楚: (评价准则)
- 问题求解器是否一定能找到一个解? 【完备性】
- 问题求解器是否能终止运行, 或是否会陷入一个死循环? 【可解性】
- 当问题求解器找到解时, 找到的是否是最好的解?【最优性】
- 搜索过程的时间与空间复杂性如何?
- 怎样才能最有效地降低搜索的复杂性?
简化搜索问题——问题规约
问题规约的目的是将一个问题转化为另一个问题, 使得新问题的解也是原问题的解
端节点:不再有子节点的节点
可解节点:
- 任何终止节点都是可解节点
- 对于 或 节点, 如果它的某个子节点是可解节点,则它也是可解节点
- 对于 与 节点, 如果它的所有子节点都是可解节点,则它也是可解节点
状态空间的一般搜索
状态空间的搜索可以对应与图的搜索,搜索过程可以看作是在图中寻找一条从初始状态到目标状态的路径
符号约定:
- Open 表:存放刚生成的节点
- Close 表:存放已经检查过的节点或将要检查的节点
- \(S_0\): 初始状态
- \(G\): 搜索图
- \(M\): 表示当前扩展节点新生成的且未检查过的节点集
def Search(S0, goal):
Open = [S0]
Close = []
while Open != []:
N = Open.pop(0)
if N == goal:
return N
M = Expand(N)
for m in M:
if m not in Close:
Open.append(m)
Close.append(N)
spec_sort(Open) # 按某种策略对Open表进行排序
return None
搜索策略的关键在于如何选择下一个节点,即如何对 Open 表进行排序,DFS 使新生成的节点优先,BFS 使旧节点优先。
DFS 不是最优的,不是完备的!
代价树搜索
代价树搜索是一种启发式搜索,它是一种有向图搜索,每个节点都有一个代价值,搜索的目标是找到代价最小的路径,典型的代价树搜索问题是最短路径问题。
对于\(n_1\) 扩展的出的 \(n_2\), 他的代价值为 \(g(n_1) + c(n_1, n_2)\)
代价树广度优先搜索(按照节点的代价排序):
def CostSearch(S0, goal):
Open = [(S0, 0)]
Close = []
while Open != []:
N = Open.pop(0)
if N == goal:
return N
M = Expand(N)
for m in M:
if m not in Close:
Open.append((m, N[1] + c(N, m)))
Close.append(N)
sort(Open, key=lambda x: x[1]) # 按cost对Open表进行排序
return None
代价树深度优先搜索(按照边的代价排序)
状态树的启发式搜索
在问题本身的定义之外还利用问题的特定知识的策略
在对问题空间进行搜索时,提高搜索效率需要与问题相关的控制性信息作为搜索的指导
控制信息反映在估价函数中,估价函数的任务就是估计待搜索结点的重要程度,即估计从初始状态到目标状态的代价,代价包括两部分:从初始状态到当前状态的代价和从当前状态到目标状态的代价,代价越小,说明越能以最小的代价找到目标状态
估价函数\(f(n)\)定义为:\(f(n) = g(n) + h(n)\), 其中 \(g(n)\) 是从初始状态到节点 \(n\) 的代价,\(h(n)\) 是从节点 \(n\) 到目标状态的代价的估计值,\(f(n)\) 是从初始状态经过节点 \(n\) 到目标状态的代价的估计值
如果 h(n)=0,g(n)=d(n) 时,就是广度优先搜索法。一般讲在 f(n) 中,g(n)的比重越大,越倾向于广度优先搜索;h(n)的比重越大,越倾向于深度优先搜索
A 算法
在图算法的每一步利用估价函数 \(f(n)\) 对 open 表排序,则称为 A 算法
- 全局择优:从 open 表中选取 f(n) 最小的节点进行扩展
- 局部择优:从刚扩展的节点的子节点中选取 f(n) 最小的节点进行扩展(Gradient 上升是一种局部择优)
例子:八数码问题
估价函数为不在位的数码个数

A* 算法
是对 A 算法的估价函数加上某些限制的算法
假设 \(f^\star(n)\)是经过节点 \(n\) 到目标状态的最小代价,\(f(n)\)是估计值,且\(f^\star(n) = g^\star(n) + h^\star(n)\)
需要保证 \(h(n) \leq h^\star(n)\),实际上这样的限制能够有良好的性质, 即是可采纳的。\(h(n)\)越小,扩展的节点就越多,效率就越低
如果 \(h(n) = 0\), 那么可以看作是 Dijkstra 算法
因此就有了如下的限制
-
\(h(n) \leq h^\star(n)\)
-
\(g(n) = g^\star(n), g(n) > 0\)
-
可采纳性:当从初始节点到目标节点有路径存在,如果搜索算法总能在有限步骤内找到最佳路径,并在该条路径上结束,则称搜索算法是可采纳的
A* 算法的可采纳性可以证明
例:给定 4L 和 3L 水壶各一个。水壶上没有刻度。可以向水壶中加水。如何在 4L 的壶中准确的得到 2L 水?
思考:
(1)为什么 h(n)≡0 使搜索过程接近于宽度优先搜索?(因为扩展节点优先从到达的节点代价最小处扩展)
(2)为什么 g(n)≡0 使搜索过程接近于深度优先搜索?(因为扩展结点优先从到达最优解代价最小的节点扩展)
def a_star_search(graph, start, goal):
open_list = PriorityQueue()
open_list.put(start, 0)
came_from = {}
cost_so_far = {}
came_from[start] = None
cost_so_far[start] = 0
while not open_list.empty():
current = open_list.get()
if current == goal:
break
for next in graph.neighbors(current):
new_cost = cost_so_far[current] + graph.cost(current, next)
# 如果新的代价更小或者下一个节点不在代价表中
if next not in cost_so_far or new_cost < cost_so_far[next]:
cost_so_far[next] = new_cost
priority = new_cost + heuristic(goal, next)
open_list.put(next, priority)
came_from[next] = current
return came_from, cost_so_far
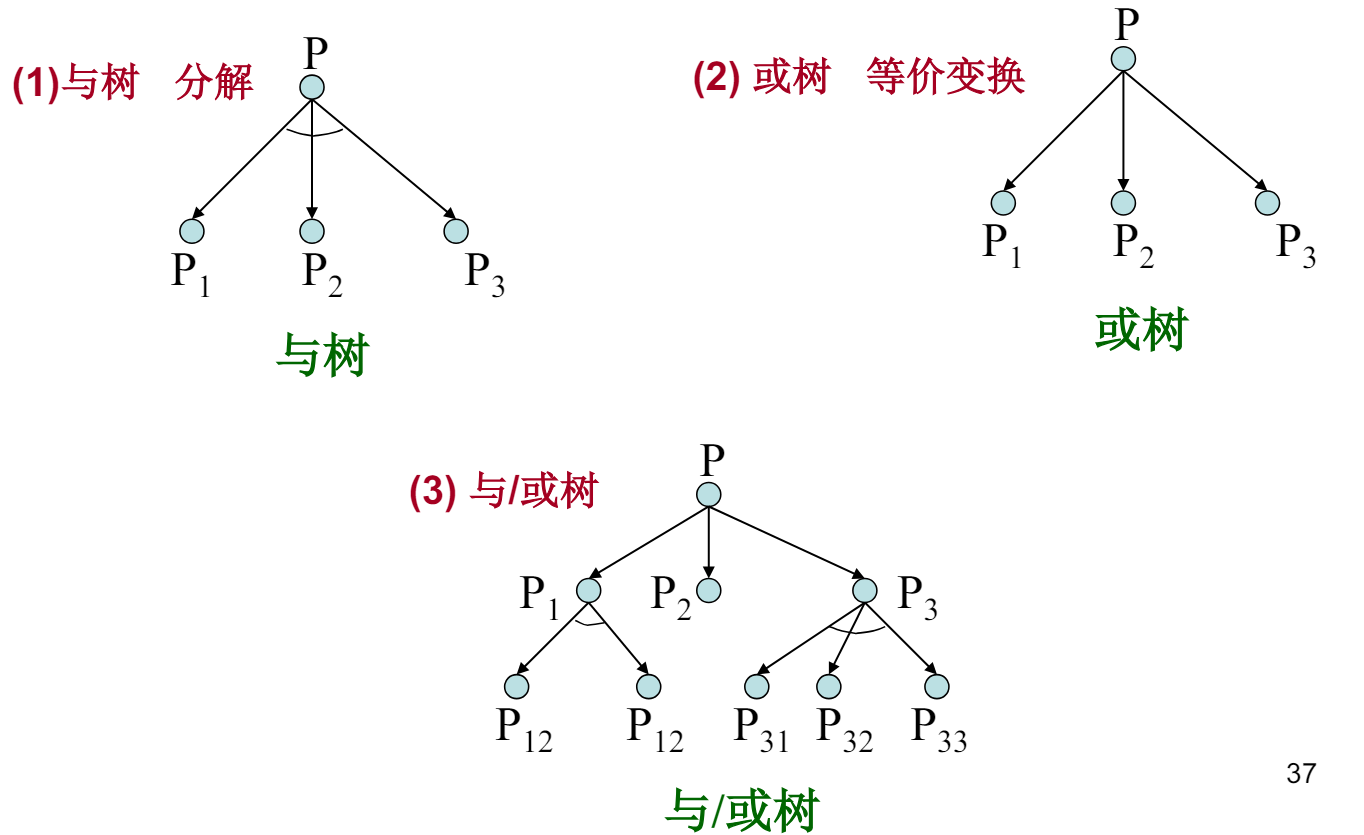
与或树搜索
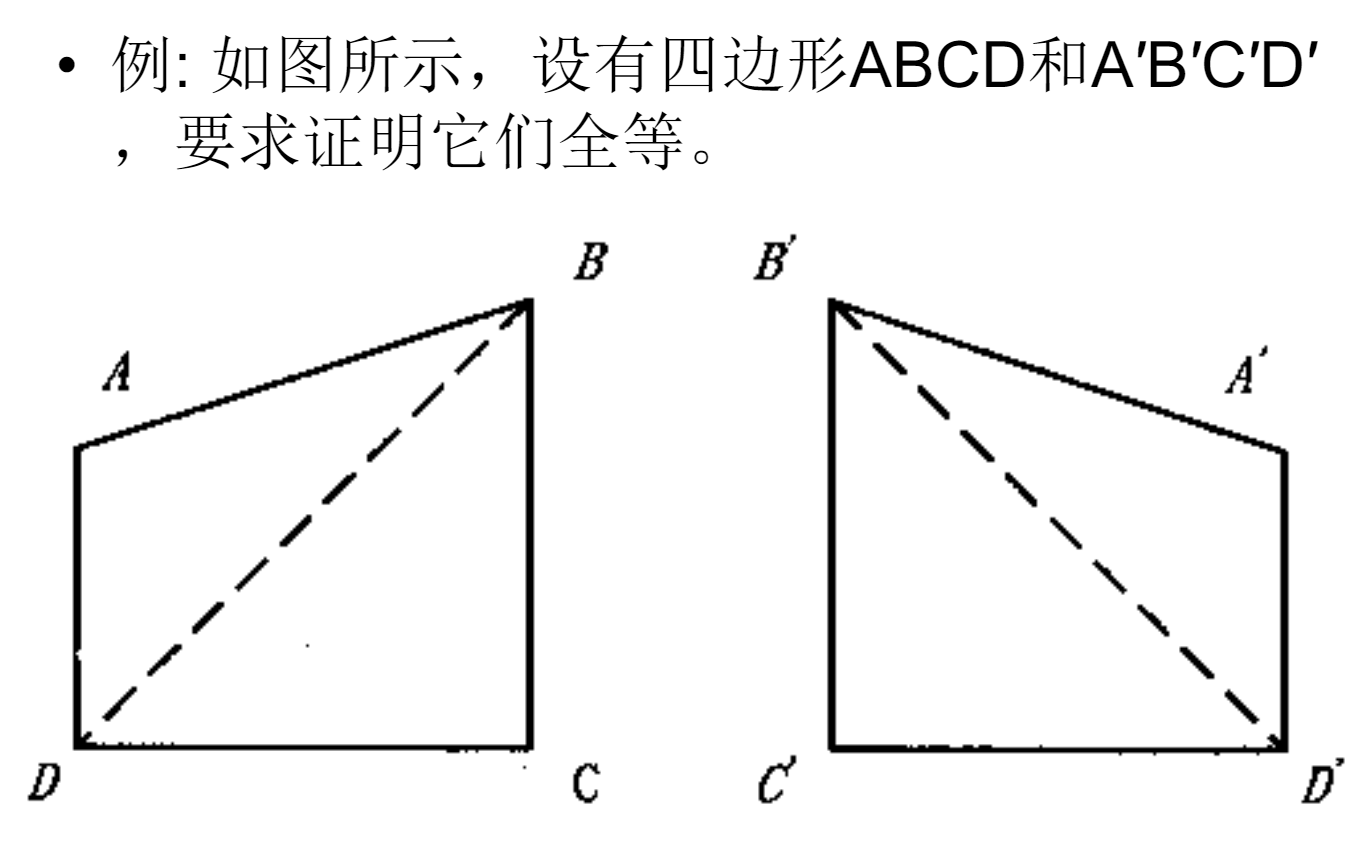
例: 证明两个四边形全等

博弈树搜索
来自于博弈论
而二人零和、全信息、非偶然是最简单的博弈
在零和的条件下,两个玩家的利益是完全对立的,一个玩家的收益就是另一个玩家的损失
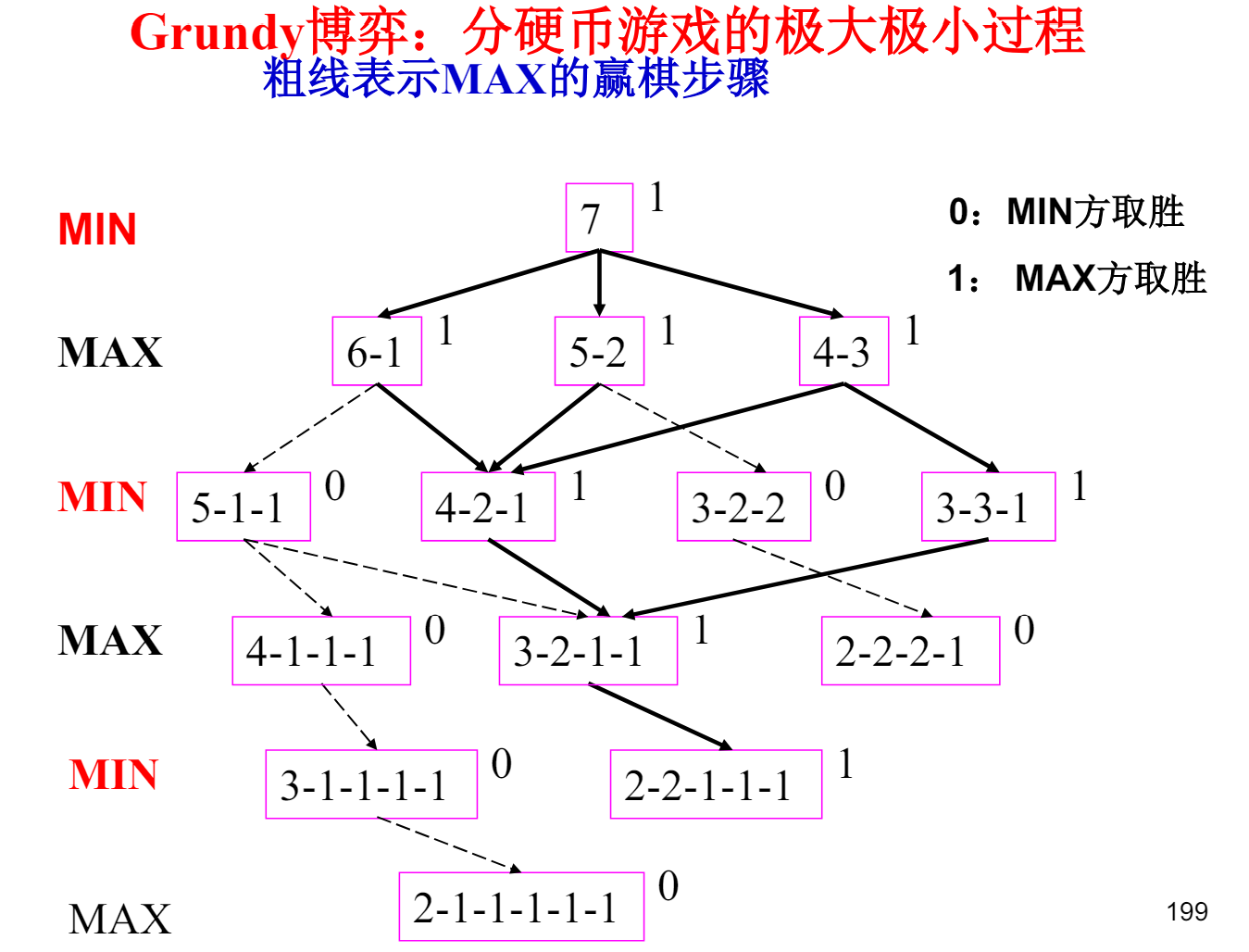
因此,博弈树的搜索就是在两个玩家之间进行的,每个玩家都希望自己的收益最大,而对方的收益最小,这就是一个 min-max 问题
而博弈树的搜索就是在一个操作与或树的搜索
博弈过程中,设我方为 A 方,则可供 A 方选择的若干行动方案之间是“或”关系;在 A 方行动方案基础上,B 方也有若干个可供选择的行动方案,则这些方案对 A 方来说就是“与”关系。
例:
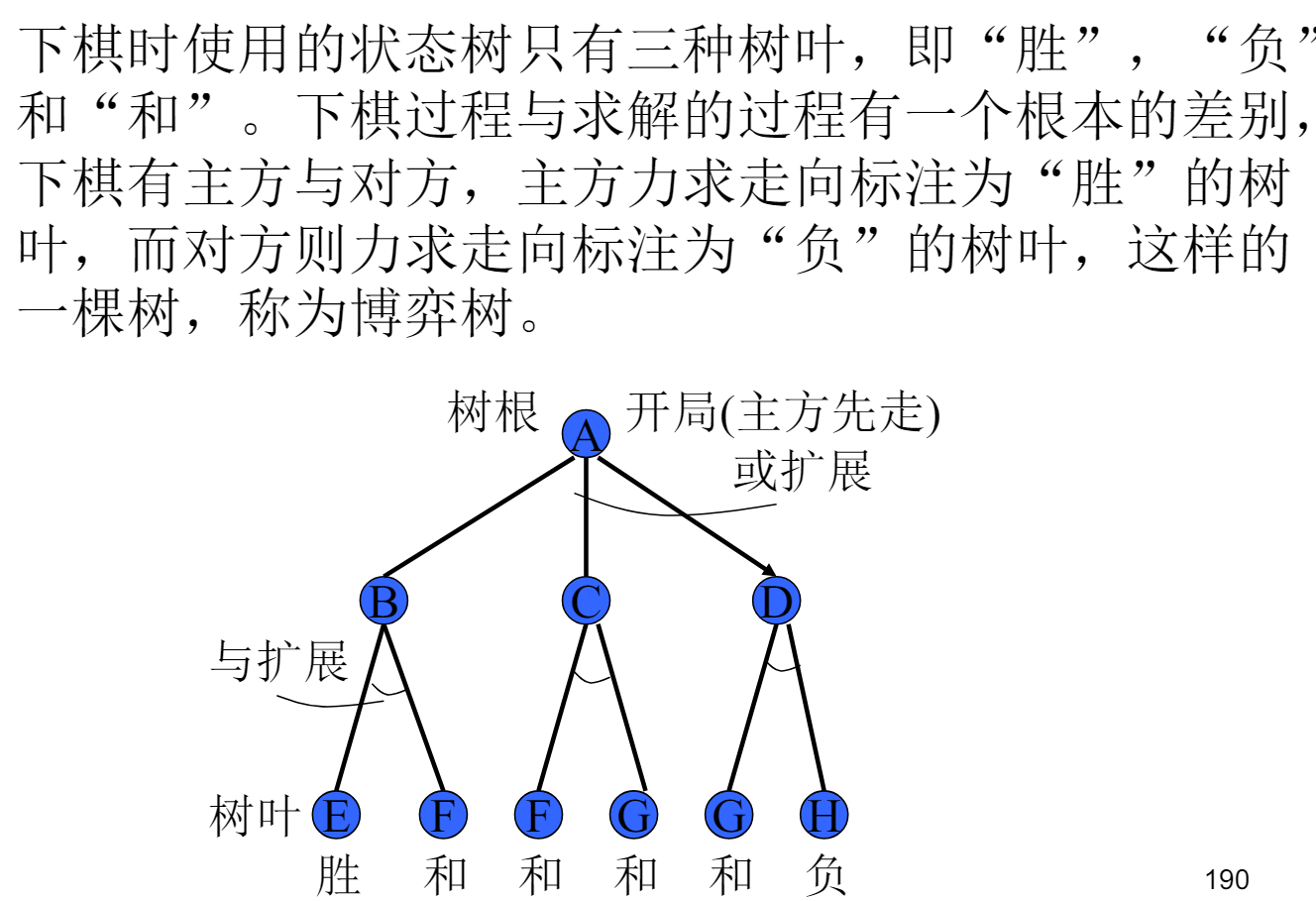
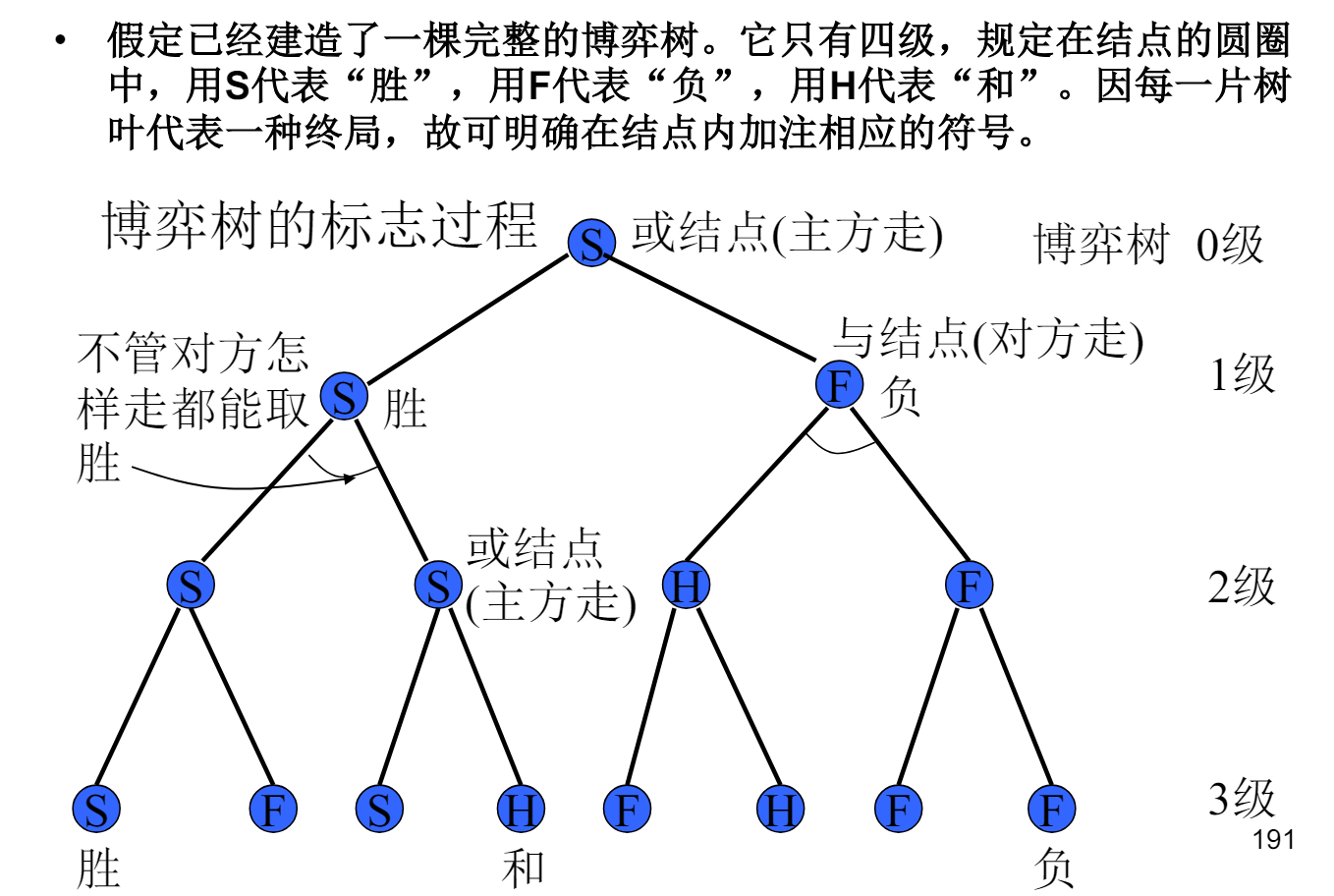
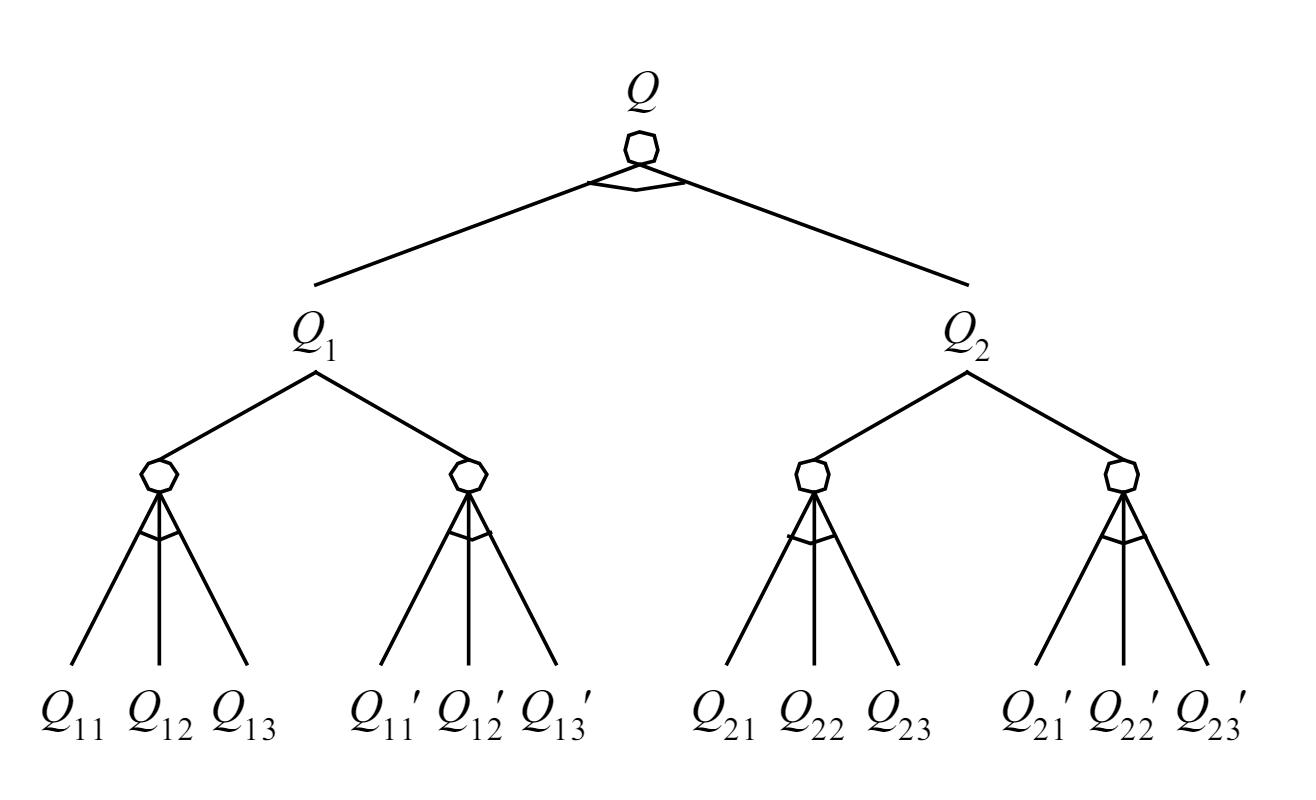
(1)对于或结点(表示主方走),在它的全部后继结点中,若有一个为 S 结点,则标为 S;若全为 F 结点,则标为 F,否则为 H。
(2)对于与结点(表示对方走),在它的全部后继结点中,若全为 S 结点,则标为 S;若有一个为 F 结点,则标为 F,否则为 H。
而对于叶节点的估值方法:使用不同的得分表示结果,如胜利为 1,失败为 -1,平局为 0, 对于 non-leaves 节点,使用 min-max 算法向上倒退

例:分硬币游戏