KKT
问题引入
我们考虑一个最优化问题:
(P)minf(x)s.t. gi(x)≤0,i=1,2,…,mhi(x)=0,i=1,2,…,p
假设问题拥有三个不等式约束和一个等式约束,在x⋆处应该会满足如下图的条件:
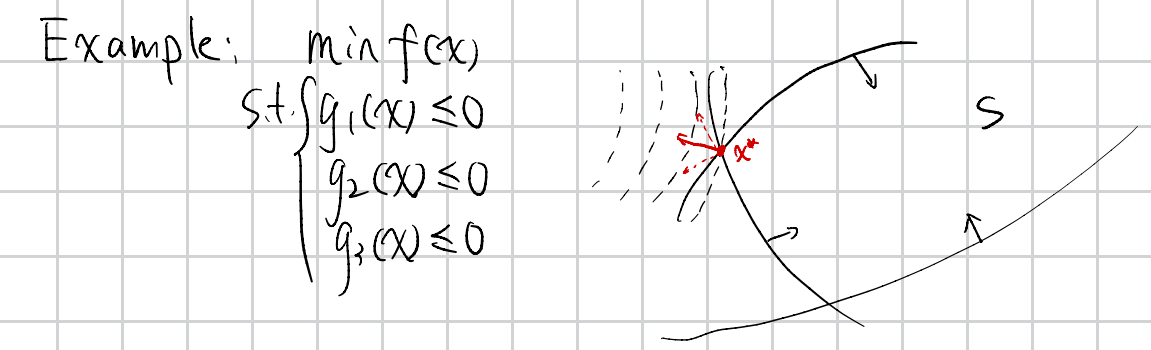
即在x⋆处,f(x)的负梯度方向(正交于约束曲面,因为不正交就可以沿着方向移动)可以表示为部分约束的梯度方向的线性组合,即
∇f(x⋆)=−λ1∇g1(x⋆)−λ2∇g2(x⋆)
其中λ1,λ2≥0。
那么为了上述等式更加规范化,我们将g3(x)也加入到约束中,即
∇f(x⋆)=−λ1∇g1(x⋆)−λ2∇g2(x⋆)−λ3∇g3(x⋆)λ1,λ2≥0, λ3=0
可以将约束条件写为
λigi(x)=0,i=1,2,3
直观地想,这是一个必要条件,因为很多地方都能满足这个条件,但是不一定是最优解。
那么如何将这样一个想法转化为一个标准的条件,这就是 KKT 条件的作用。
KKT 条件简述
KKT 条件:对于一个最优化问题,如果x⋆是一个局部最优解,且在x⋆处满足某一种 constraint qualification,那么最优解满足以下条件:
∇f(x⋆)+m∑i=1λi∇gi(x⋆)+p∑i=1μi∇hi(x⋆)=0λi≥0,i=1,2,…,mgi(x⋆)≤0,i=1,2,…,mhi(x⋆)=0,i=1,2,…,pλigi(x⋆)=0,i=1,2,…,m
我们称满足条件的λi,μi为拉格朗日乘子。
其中,第(1)(2)个条件称作Dual Feasibility,第(3)(4)个条件称作Primal Feasibility,第(5)个条件称作Complementary Slackness。
可以想象,gi(x⋆)<0对最优解的梯度方向不起作用。
其实可以指出,KKT 条件是一个必要条件,而不是充分条件。
KKT 条件的推导
证明 KKT 条件涉及三个集合、一个 constraint qualification 和 Farkas 引理,理论性较强,这里不做详细推导。
Dual Problem
我们依旧考虑上面提及的 Primal Problem
(P)minf(x)s.t. gi(x)≤0,i=1,2,…,mhi(x)=0,i=1,2,…,p
可行集合为
S={x∈Rn|gi(x)≤0,hi(x)=0}
为什么我们需要从 Primal Problem 转化为 Dual Problem 呢?因为
- 如果 P 问题非凸,求解原问题是一个 NP-hard 问题,而 Dual Problem 可能是一个凸优化问题
- 当 P 问题是一个凸优化问题时,Dual Problem 可以帮助我们理解问题的几何性质
- Dual Problem 可以帮助我们理解问题的最优解
拉格朗日对偶函数
我们定义拉格朗日函数
L(x,λ,μ)=f(x)+m∑i=1λigi(x)+p∑i=1μihi(x),x∈X,λ≥0
拉格朗日对偶函数定义为
dual(λ,μ)=infx∈XL(x,λ,μ)λi≥0
我们可以得到如下不等式:
dual(λ,μ)=infx∈XL(x,λ,μ)λi≥0≤infx∈SL(x,λ,μ)λi≥0≤infx∈Sf(x)
如果我们 denote 原问题最优值为p⋆记为v(p),那么我们可以得到如下结论:
∀λ≥0,μ,dual(λ,μ)≤p⋆
即对偶函数是原问题最优值的下界。
拉格朗日对偶问题(求一个最大下界)
我们定义拉格朗日对偶问题为
(D)maxdual(λ,μ)s.t. λi≥0,i=1,2,…,m
如果我们将对偶函数写开,则对偶问题可以写为
(D)maxλ,μminx∈XL(x,λ,μ)s.t. λi≥0,i=1,2,…,m
如果我们考虑将最小值和最大值交换,那么可以得到如下问题
minx∈Xmaxλ,μL(x,λ,μ)s.t. λi≥0,i=1,2,…,m
对于这个优化问题
- 如果∃i,gi(x)>0,那么最大值为无穷大
- 如果∃i,hi(x)≠0,那么最大值为无穷大
- 如果∀i,gi(x)≤0,hi(x)=0,那么最大值为f(x),则此时可以等价为 Primal Problem
因此,这个问题,值希望有界的话,实际上与 Primal Problem 等价,即
minx∈Xmaxλ≥0,μL(x,λ,μ)⟺min{minx∈Sf(x),∞}⟺minx∈Sf(x)
弱对偶定理
在前面我们已经得到了d(λ,μ)≤v(P)的结论,对于任意的λ≥0,μ。
那么对于对偶问题,我们如果我们 denote 对偶问题最优值为d⋆=v(D),那么我们可以得到如下结论:
∀λi≥0,d(λ,μ)≤v(D)≤v(P)≤f(x)
可以形象理解为鸡头和凤尾的关系。
Dual Gap
我们定义对偶问题和原问题的差距为 Dual Gap,即
Dual Gap=v(P)−v(D)
可以映射到几何空间中
强对偶定理
一个凸优化问题可以被涉及成不满足强对偶问题的情况,因此在凸优化问题外,还要满足一个条件。
假设(充分条件):
- (凸优化)X 是非空凸集,f,gi 是凸函数,hi是仿射函数。(原问题是凸优化问题)
- (Slater Condition)∃^x∈X,s.t.gi(^x)<0,hi(^x)=0(有一个严格可行点),同时 0 是一个h(x)的内点。(这个条件最常用的是 Slater Condition)
- Slater Condition:∃^x∈relintD,s.t.gi(^x)<0,hi(^x)=0
那么我们可以得到如下结论:
v(P)=v(D)⟺minf(x)=maxd(λ,μ)
证明略...
于是,对于强对偶问题,我们只需要分别对函数中的λ,μ和原问题中的x进行偏导=0 即可。
对偶问题的性质
对偶函数是一个凹函数
dual(λ,μ)=minx∈XL(x,λ,μ)λi≥0
其中若将x看作一个参数,那么L(x,λ,μ)是一个关于λ,μ的仿射函数,因此对偶函数是一个凹函数。
所以maxconcave⟺minconvex,对偶问题一定是一个凸优化问题。
KKT 条件与对偶问题
一个凸优化问题,只要是强对偶的,一定满足 KKT 条件(必要条件)。因此,我们可以通过求解对偶问题来求解原问题。
对偶问题的求解方法就是先构建拉格朗日函数,然后先对x求梯度,然后对λ,μ求最大值。
对于凸优化
-
如果x⋆满足 KKT 条件,那么x⋆是原问题的最优解,且对偶问题的最优解是 KKT 条件中的乘子。
-
如果 Slater Condition 满足,那么原问题的最优解的 KKT 点乘子与对偶问题的最优解相等。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具