ResNet
Deep Residual Learning for Image Recognition(自学用)
重点关注在 Deep 与 Redidual learning上,这两个关键词是本文的核心。
背景
神经网络的深度对于网络的性能有着重要的影响,在 CV 领域,之前的AlexNet、VGG、GoogLeNet等网络中有所体现。
深度网络可以非常自然地整合 low/mid/high-level 特征,特征的“层次”可以通过堆叠层数(深度)来丰富。
然而,更深的网络并不总是意味着更好的性能,深度网络的训练会遇到一些问题:会遇见梯度消失/爆炸的问题,导致训练困难。在之前的一些工作中,通过使用更好的初始化方法(xaiver)、更好的激活函数(ReLU)、更好的正则化方法(Dropout)、归一化方法(Batch Normalization)等,来解决这些问题。
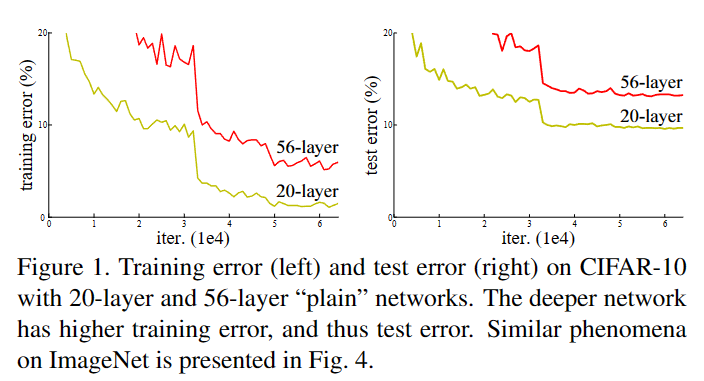
可以观察到,更深的网络并没有带来更好的性能,这显然不是由于 overfitting 导致的,因为 training error 和 testing error 都没有上升。在这篇文章,这样的现象被作者称为“degradation”。
然而,Deep Networks 不应该 degradation,因为它们可以表示 identity mapping,即 \(H(x) = x\),这是一个非常简单的映射,可以通过多层网络来表示。但是由于深层网络没有加以限制,SGD 无法学习到这个映射,导致 degradation。
本文提出的解决方法——Residual Block
假设我要学习一个映射 \(\mathcal{H}(x)\),那么我可以通过学习一个残差映射 \(\mathcal{F}(x) = \mathcal{H}(x) - x\),然后将 \(\mathcal{H}(x) = \mathcal{F}(x) + x\),这样就可以保证 \(\mathcal{H}(x)\) 至少和 \(x\) 一样好。
\(\mathcal{F}(x) + x\)这样一个结构,在神经网络中被称作 shortcut connections,可以被看作成一个 identity mapping,在 NN 中没有额外的参数,不会增加计算量。
那么一个 Redisual Block 的结构如下:
如果 F 是一个两层的网络,那么 \(F(x, \{W_i\}) = W_2 \sigma(W_1 x)\),其中 \(\sigma\) 是 ReLU 激活函数。
Mark:\(x\) 与 \(F(x, \{W_i\})\) 的输出维度必须相等,在计算机视觉中需要 H W C 都相等, 如果 C 不相等,需要使用\(1 \times 1\)的卷积层调整通道
为什么 Residual Block 有效
1. 从梯度来看
在之后的研究中,研究者发现 Residual Block 实际上是通过传递梯度来解决 degradation 问题的。
我们做一个简单的分析,假设该层输入是 \(x\),输出是 \(y\),那么该层的残差是 \(F(x)\),其中\(y = F(x) + x\), 那么没加恒等变换的梯度为
而加入恒等变换的梯度为
那么在向权重更新的方向传递梯度时,加入了恒等变换的梯度会变得更大,即我们假设\(x = d W\)
而 SGD 能训练的动的前提是梯度能够足够大,这样就可以解释为什么 Residual Block 可以解决 degradation 问题。
2. 从集成学习角度
Residual Networks Behave Like Ensembles of Relatively Shallow Networks
Mark:可以类比集成学习的网络架构方法不仅有残差网络,Dropout 机制也可以被认为是隐式地训练了一个组合的模型。
由于本文后续都是整体模型架构,这里不再展开,感兴趣的可以查看原文。

