
最短路
算法
定义:
简称(弗洛伊德)算法,是最简单的最短路径算法,可以计算图中任意两点间的最短路径。的时间复杂度是,适用于出现负边权的情况。
算法描述:
:以下没有特别说明的话:表示从 到$ v w[u][v]$ 表示连接 , 的边的长度。
初始化:点、如果有边相连,则。
如果不相连则
for (k = 1; k <= n; k++)
for (i = 1; i <= n; i++)
for (j = 1; j <= n; j++)
if (dis[i][j] >dis[i][k] + dis[k][j])
dis[i][j] = dis[i][k] + dis[k][j];
算法&思想:
三层循环,第一层循环中间点k,第二第三层循环起点终点、,算法的思想很容易理解:如果点i到点k的距离加上点k到点j的距离小于原先点i到点j的距离,那么就用这个更短的路径长度来更新原先点到点的距离。
在上图中,因为,所以就用]来更新原先1到2的距离。
我们在初始化时,把不相连的点之间的距离设为一个很大的数,不妨可以看作这两点相隔很远很远,如果两者之间有最短路径的话,就会更新成最短路径的长度。Floyed算法的时间复杂度是O(N3)。
算法
定义:
用来计算从一个点到其他所有点的最短路径的算法,是一种单源最短路径算法。也就是说,只能计算起点只有一个的情况。
(:有了负权值这种算法就不能用了,为什么呢?
因为这种算法是贪心的思想,每次松弛的的前提是用来松弛这条边的最短路肯定是最短的。
然而有负权值的时候这个前提不能得到保证,所以这种算法不能成立。)
思路:
算法分析&思想讲解:
从起点到一个点的最短路径一定会经过至少一个“中转点”(例如下图1到5的最短路径,中转点是2,特殊地,我们认为起点1也是一个“中转点”)。
显而易见,如果我们想求出起点到一个点的最短路径,那我们必然要先求出中转点的最短路径(例如我们必须先求出点2 的最短路径后,才能求出从起点到5的最短路径)。
我们把点分为两类,一类是已确定最短路径的点,称为“白点”,另一类是未确定最短路径的点,称为“蓝点”。如果我们要求出一个点的最短路径,就是把这个点由蓝点变为白点。从起点到蓝点的最短路径上的中转点在这个时刻只能是白点。
Dijkstra的算法思想,就是一开始将起点到起点的距离标记为0,而后进行次循环,每次找出一个到起点距离最短的点,将它从蓝点变为白点。随后枚举所有的蓝点,如果以此白点为中转到达蓝点的路径更短的话,这将它作为的“更短路径”(此时还不确定是不是的最短路径)。
就这样,我们每找到一个白点,就尝试着用它修改其他所有的蓝点。中转点先于终点变成白点,故每一个终点一定能够被它的最后一个中转点所修改,而求得最短路径。
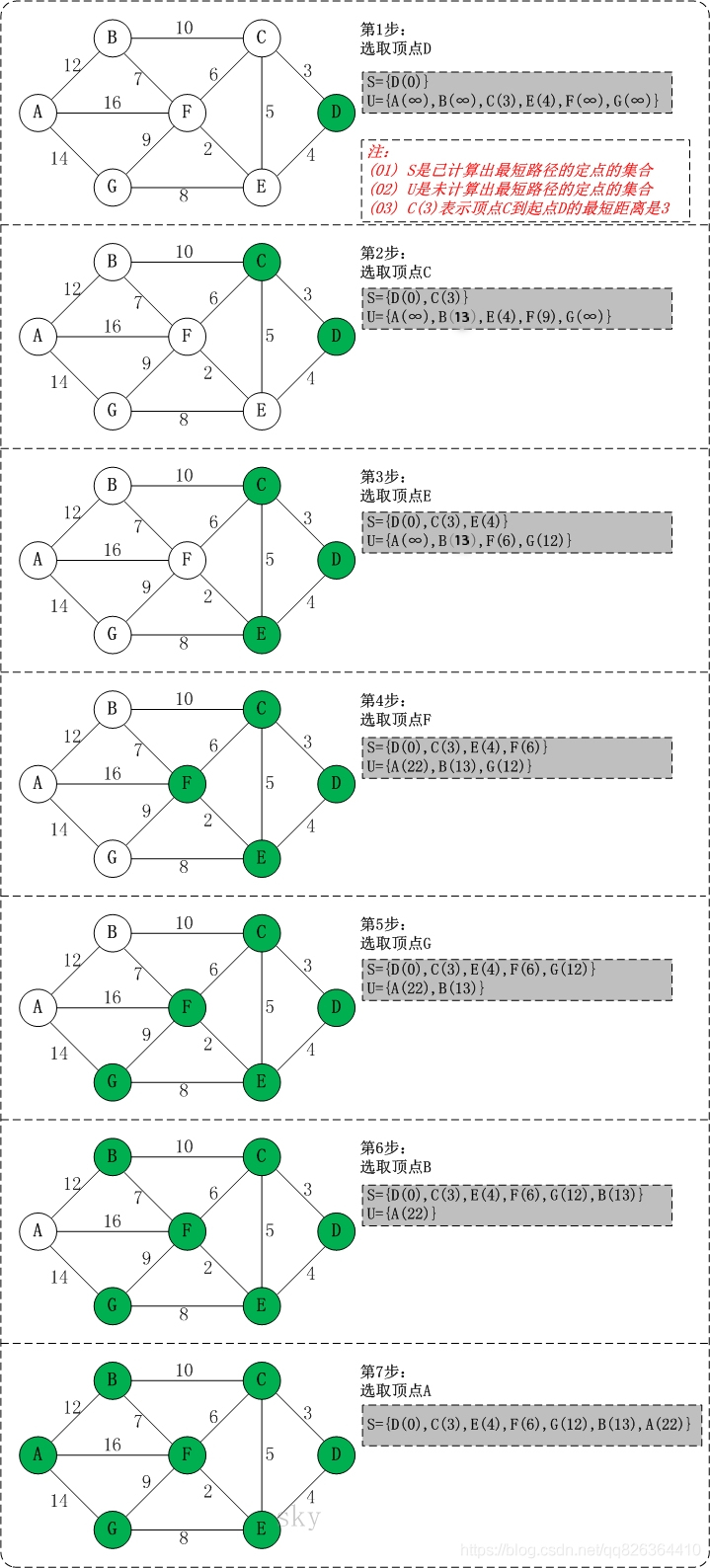
实现
(1)朴素算法
给出代码:
void dij(int st){
memset(dis,INF,sizeof(dis));
for(int i=head[st];i;i=e[i].nxt) dis[e[i].v]=e[i].w;
dis[st]=0,now=st;
while(!vis[now]){
vis[now]=1,minn=INF;
for(int i=head[now],w,v;i;i=e[i].nxt){
v=e[i].v;w=e[i].w;
if(!vis[v]&&dis[v]>dis[now]+w)dis[v]=dis[now]+w;
}
for(int i=1;i<=n;i++){
if(!vis[i]&&dis[i]<minn){
minn=dis[i],now=i;
}
}
}
}
(2)堆优化
我们通过学习朴素算法,明白算法的实现需要从头到尾扫一遍点找出最小的点然后进行松弛。这个扫描操作就是坑害朴素算法时间复杂度的罪魁祸首。
所以我们使用小根堆,用优先队列来维护这个“最小的点”。从而大大减少算法的时间复杂度。
前置芝士:
1.pair
是自带的二元组。我们可以把它理解成一个有两个元素的结构体。
更刺激的是,这个二元组有自带的排序方式:以第一关键字为关键字,再以第二关键字为关键字进行排序。
所以,我们用二元组的位存距离,位存编号即可。
typedef pair<int,int> p;
priority_queue<p,vector<p>,greater<p> >q;
定义一个按pair排好的小根堆;
2.怎么往pair类型的优先队列里加元素
q.push(make_pair(first,second))
实现:
我们需要往优先队列中最短路长度,但是它一旦入队,就会被优先队列自动维护离开原来的位置,换言之,我们无法再把它与它原来的点对应上,也就是说没有办法形成点的编号到点权的映射。
我们用解决这个问题,参考前置芝士。
代码:
void dijkstra(){
for(int i=1;i<=n;i++)dis[i]=INF;
dis[s]=0;q.push(make_pair(0,s));
while(!q.empty()){
int u=q.top().second;q.pop();
if(vis[u]) continue; vis[u]=1;
for(int i=head[u];i;i=e[i].next){
int v=e[i].v;
if(dis[v]>dis[u]+e[i].w){
dis[v]=dis[u]+e[i].w;
q.push(make_pair(dis[v],v));
}
}
}
}
算法
不会……
算法
关于:
是算法的一种队列实现,减少了不必要的冗余计算。
主要思想:
初始时将起点加入队列。每次从队列中取出一个元素,并对所有与它相邻的点进行修改,若某个相邻的点修改成功,则将其入队。直到队列为空时算法结束。
这个算法,简单的说就是队列优化的,利用了每个点不会更新次数太多的特点发明的此算法。
在形式上和广度优先搜索非常类似,不同的是广度优先搜索中一个点出了队列就不可能重新进入队列,但是中一个点可能在出队列之后再次被放入队列,也就是说一个点修改过其它的点之后,过了一段时间可能会获得更短的路径,于是再次用来修改其它的点,这样反复进行下去。
(:为什么可以处理负边:
因为在SPFA中每一个点松弛过后说明这个点距离更近了,所以有可能通过这个点会再次优化其他点,所以将这个点入队再判断一次,而中是贪心的策略,每个点选择之后就不再更新,如果碰到了负边的存在就会破坏这个贪心的策略就无法处理了。)
代码:
void spfa() {
for(int i=1; i<=n; i++) dis[i]=INF;
q.push(s);vis[s]=1;dis[s]=0;int u,v;
while(!q.empty()) {
u=q.front();q.pop();vis[u]=0;
for(int i=head[u]; i; i=e[i].nxt) {
v=e[i].v;
if(dis[v]>dis[u]+e[i].w) {
dis[v]=dis[u]+e[i].w;
if(!vis[v]) {
vis[v]=1;q.push(v);
}
}
}
}
}
本文作者:Gym_nastics
本文链接:https://www.cnblogs.com/BlackDan/p/15184864.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)