

python str.format 中文对齐的细节问题
写了一个练手的爬虫...在输出的时候出现了让人很不愉♂悦的问题
像这样:
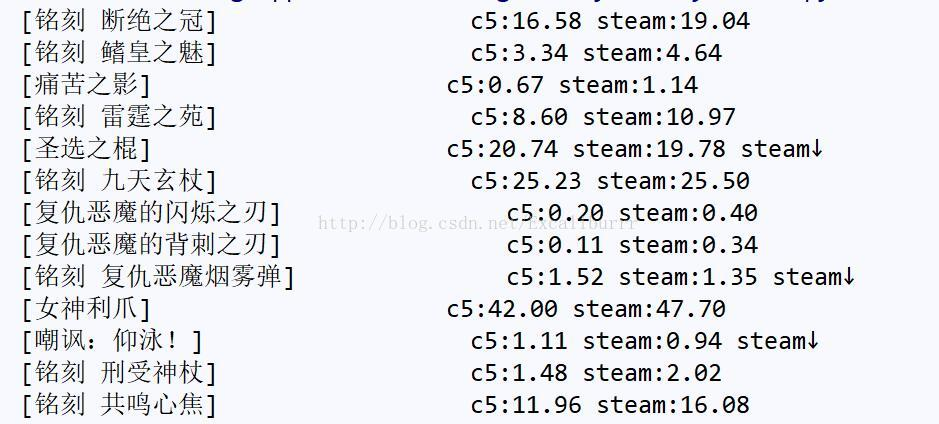
令人十分难受啊!
#-------------------------------------------------------------------------------------------------
在此之前先说一下python中的.format格式化输出

python2.6开始,可以使用str.format进行轻松的格式化,
如上可以看到,对变量的处理简洁灵活,此外对数字的各种位数处理也很到位
{:<x}的语法表示左对齐(>为右对齐,^为居中),少于x位自动补齐(默认为空格补齐)
这里值得注意的是,x也可以作为变量代入:

如上可以看到,对变量的处理简洁灵活,此外对数字的各种位数处理也很到位
{:<x}的语法表示左对齐(>为右对齐,^为居中),少于x位自动补齐(默认为空格补齐)
这里值得注意的是,x也可以作为变量代入:
py虽好,有些细节还是没有照顾到中文
这里补齐长度时中文字符也按1字节计算了,
然而我们知道,utf-8中中文占用3个字节,GBK中占用了2个字节,只算作1字节显然不能对齐
这里补齐长度时中文字符也按1字节计算了,
然而我们知道,utf-8中中文占用3个字节,GBK中占用了2个字节,只算作1字节显然不能对齐
这时求助于prettytable包输出表格,然而输出也不理想,可以想象也没有考虑中文编码的问题(或是需要设置编码为utf-8或gbk?)
分析一下理想的name所占的长度,应为固定的x字节(这里按目前的爬取结果暂时取22)
那么他的补齐长度应为
len = 22 - gbk编码下name的字节数 + name的字符数
幸运的是str.format支持使用变量代替补齐长度的值
尝试以下代码:
print('[{name:<{len}}x'.format(name=name+']',len=22-len(name.encode('GBK'))+len(name)))结果十分接近理想了:

分析一下理想的name所占的长度,应为固定的x字节(这里按目前的爬取结果暂时取22)
那么他的补齐长度应为
len = 22 - gbk编码下name的字节数 + name的字符数
幸运的是str.format支持使用变量代替补齐长度的值
尝试以下代码:
print('[{name:<{len}}x'.format(name=name+']',len=22-len(name.encode('GBK'))+len(name)))结果十分接近理想了:
还是有一些迷之问题导致1-0.5字节长度的偏差,猜测是由于中文字体不是等宽字体的缘故?
然而不用多虑,这里就可以使用一记粗暴的制表符\t解决问题了
print('[{name:<{len}}\tx'.format(name=name+']',len=22-len(name.encode('GBK'))+len(name)))
作者:killercars
来源:CSDN
原文:https://blog.csdn.net/excaliburrr/article/details/76794451
版权声明:本文为博主原创文章,转载请附上博文链接!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!