
数据分析-财政分析预测
- 描述性统计分析
# 代码6-1 import numpy as np import pandas as pd inputfile = 'D:/人工智能&软件工程/数据挖掘与分析/data/data.csv' # 输入的数据文件 data = pd.read_csv(inputfile) # 读取数据 # 描述性统计分析 description = [data.min(), data.max(), data.mean(), data.std()] # 依次计算最小值、最大值、均值、标准差 description = pd.DataFrame(description, index = ['Min', 'Max', 'Mean', 'STD']).T # 将结果存入数据框 print('描述性统计结果:\n',np.round(description, 2)) # 保留两位小数
描述性统计结果学号-3041: Min Max Mean STD x1 3831732.00 7599295.00 5579519.95 1262194.72 x2 181.54 2110.78 765.04 595.70 x3 448.19 6882.85 2370.83 1919.17 x4 7571.00 42049.14 19644.69 10203.02 x5 6212.70 33156.83 15870.95 8199.77 x6 6370241.00 8323096.00 7350513.60 621341.85 x7 525.71 4454.55 1712.24 1184.71 x8 985.31 15420.14 5705.80 4478.40 x9 60.62 228.46 129.49 50.51 x10 65.66 852.56 340.22 251.58 x11 97.50 120.00 103.31 5.51 x12 1.03 1.91 1.42 0.25 x13 5321.00 41972.00 17273.80 11109.19 y 64.87 2088.14 618.08 609.25 - 相关性分析
# 代码6-2 # 相关性分析 corr = data.corr(method = 'pearson') # 计算相关系数矩阵 print('相关系数矩阵为学号-3041:\n',np.round(corr, 2)) # 保留两位小数
相关系数矩阵为学号-3041: x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 \ x1 1.00 0.95 0.95 0.97 0.97 0.99 0.95 0.97 0.98 0.98 -0.29 0.94 x2 0.95 1.00 1.00 0.99 0.99 0.92 0.99 0.99 0.98 0.98 -0.13 0.89 x3 0.95 1.00 1.00 0.99 0.99 0.92 1.00 0.99 0.98 0.99 -0.15 0.89 x4 0.97 0.99 0.99 1.00 1.00 0.95 0.99 1.00 0.99 1.00 -0.19 0.91 x5 0.97 0.99 0.99 1.00 1.00 0.95 0.99 1.00 0.99 1.00 -0.18 0.90 x6 0.99 0.92 0.92 0.95 0.95 1.00 0.93 0.95 0.97 0.96 -0.34 0.95 x7 0.95 0.99 1.00 0.99 0.99 0.93 1.00 0.99 0.98 0.99 -0.15 0.89 x8 0.97 0.99 0.99 1.00 1.00 0.95 0.99 1.00 0.99 1.00 -0.15 0.90 x9 0.98 0.98 0.98 0.99 0.99 0.97 0.98 0.99 1.00 0.99 -0.23 0.91 x10 0.98 0.98 0.99 1.00 1.00 0.96 0.99 1.00 0.99 1.00 -0.17 0.90 x11 -0.29 -0.13 -0.15 -0.19 -0.18 -0.34 -0.15 -0.15 -0.23 -0.17 1.00 -0.43 x12 0.94 0.89 0.89 0.91 0.90 0.95 0.89 0.90 0.91 0.90 -0.43 1.00 x13 0.96 1.00 1.00 1.00 0.99 0.94 1.00 1.00 0.99 0.99 -0.16 0.90 y 0.94 0.98 0.99 0.99 0.99 0.91 0.99 0.99 0.98 0.99 -0.12 0.87 x13 y x1 0.96 0.94 x2 1.00 0.98 x3 1.00 0.99 x4 1.00 0.99 x5 0.99 0.99 x6 0.94 0.91 x7 1.00 0.99 x8 1.00 0.99 x9 0.99 0.98 x10 0.99 0.99 x11 -0.16 -0.12 x12 0.90 0.87 x13 1.00 0.99 y 0.99 1.00 - 绘制热力图
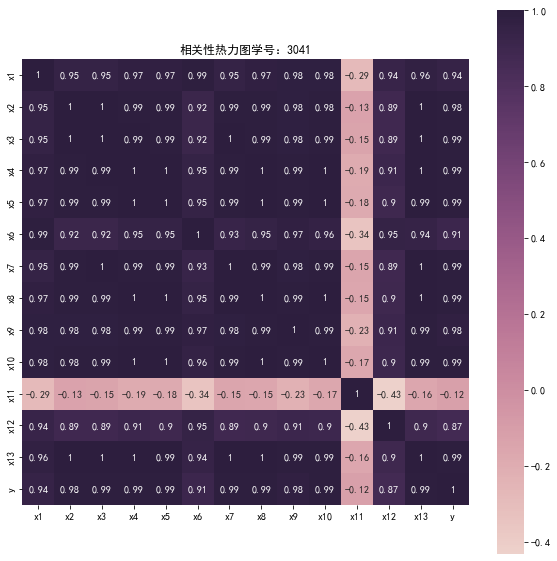
# 代码6-3 # 绘制热力图 import matplotlib.pyplot as plt import seaborn as sns plt.subplots(figsize=(10, 10)) # 设置画面大小 sns.heatmap(corr, annot=True, vmax=1, square=True, cmap=sns.cubehelix_palette(as_cmap=True))#annot为默认下没有数值,cmap为选择颜色默认为红色,linewidth为间隔线 plt.rcParams['font.sans-serif'] = ['SimHei']#正常显示中文 plt.rcParams['axes.unicode_minus'] = False #正常显示负号 plt.title('相关性热力图学号:3041') plt.show() plt.close
![]()
- 绘制半边相关性热力图
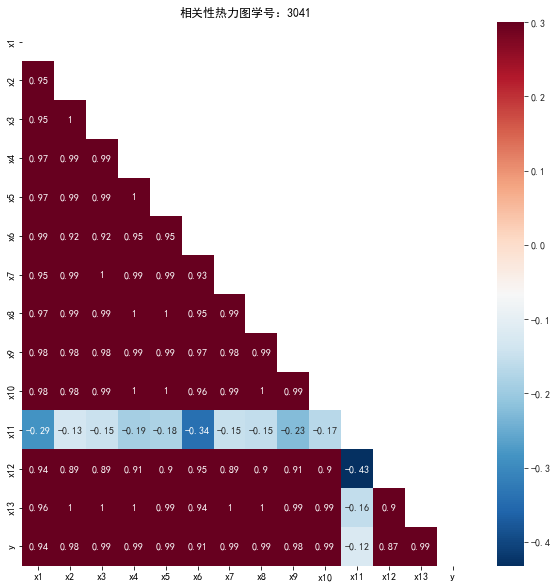
#绘制只有一半的相关性热力图 import matplotlib.pyplot as plt import seaborn as sns plt.subplots(figsize=(10, 10)) # 设置画面大小 mask = np.zeros_like(corr) #将mask的对角线及以上设置为True mask[np.triu_indices_from(mask)] = True #这部分就是对应要被遮掉的部分 with sns.axes_style("white"): sns.heatmap(corr, mask=mask, vmax=0.3, annot=True,cmap="RdBu_r") plt.rcParams['font.sans-serif'] = ['SimHei']#正常显示中文 plt.rcParams['axes.unicode_minus'] = False #正常显示负号 plt.title('相关性热力图学号:3041') plt.show() plt.close
![]()
- LASSO回归模型-关键属性的选取
#LASSO回归模型-关键属性的选取 import numpy as np import pandas as pd from sklearn.linear_model import Lasso# AdaptiveLasso找不到 # LASSO回归的特点是在拟合广义线性模型的同时进行变量筛选和复杂度调整。 因此,不论目标因变量是连续的,还是二元或者多元离散的, #都可以用LASSO回归建模然后预测。 这里的变量筛选是指不把所有的变量都放入模型中进行拟合,而是有选择的把变量放入模型从而得到更好的性能参数。 inputfile = 'D:/人工智能&软件工程/数据挖掘与分析/data/data.csv' # 输入的数据文件 data = pd.read_csv(inputfile) # 读取数据 lasso = Lasso(1000)#调用Lasso()函数,设置alpha罚函数的值为1000,设置λ的值为1000 lasso.fit(data.iloc[:,0:13],data['y']) print('相关系数为:',np.round(lasso.coef_,5))#输出系数结果,四舍五入round()函数,保留5位小数 print('相关系数非零个数为:',np.sum(lasso.coef_ !=0))# 计算相关系数非零的个数 mask = lasso.coef_ !=0 #返回一个相关系数是否为零的布尔数组 print('相关系数是否为零:',mask) mask = np.append(mask,True) outputfile = 'D:/人工智能&软件工程/数据挖掘与分析/tmp/new_reg_data学号3041.csv'#输出数据文件 new_reg_data = data.iloc[:,mask]#返回相关系数非零的数据 new_reg_data.to_csv(outputfile) #存储数据 print('输出数据的维度为:',new_reg_data.shape) #查看输出数据的维度
相关系数为: [-1.8000e-04 -0.0000e+00 1.2414e-01 -1.0310e-02 6.5400e-02 1.2000e-04 3.1741e-01 3.4900e-02 -0.0000e+00 0.0000e+00 0.0000e+00 0.0000e+00 -4.0300e-02] 相关系数非零个数为: 8 相关系数是否为零: [ True False True True True True True True False False False False True] 输出数据的维度为: (20, 9)
![]()
- 自定义灰色预测函数
def GM11(x0): #自定义灰色预测函数 import numpy as np x1 = x0.cumsum() #1-AGO序列,x1为求和得到 z1 = (x1[:len(x1)-1] + x1[1:])/2.0 #紧邻均值(MEAN)生成序列,z1为x1的一半 z1 = z1.reshape((len(z1),1)) B = np.append(-z1, np.ones_like(z1), axis = 1)#B为一维 Yn = x0[1:].reshape((len(x0)-1, 1)) [[a],[b]] = np.dot(np.dot(np.linalg.inv(np.dot(B.T, B)), B.T), Yn) #计算a,b参数 f = lambda k: (x0[0]-b/a)*np.exp(-a*(k-1))-(x0[0]-b/a)*np.exp(-a*(k-2)) #还原值,预测值f delta = np.abs(x0 - np.array([f(i) for i in range(1,len(x0)+1)])) C = delta.std()/x0.std() P = 1.0*(np.abs(delta - delta.mean()) < 0.6745*x0.std()).sum()/len(x0) return f, a, b, x0[0], C, P #返回灰色预测函数、a、b、首项、方差比、小残差概率
- 灰色预测GM(1,1)与SVR支持向量机算法预测模型
# 灰色预测GM(1,1) import sys sys.path.append('D:/人工智能&软件工程/数据挖掘与分析/GM11.py') # 设置路径 import numpy as np import pandas as pd import GM11 from GM11 import GM11 # 引入自编的灰色预测函数 inputfile1 = 'D:/人工智能&软件工程/数据挖掘与分析/tmp/new_reg_data学号3041.csv' # 输入的数据文件 inputfile2 = 'D:/人工智能&软件工程/数据挖掘与分析/data/data.csv' # 输入的数据文件 new_reg_data = pd.read_csv(inputfile1) # 读取经过特征选择后的数据 data = pd.read_csv(inputfile2) # 读取总的数据 new_reg_data.index = range(1994, 2014) # new_reg_data.loc[2014] = None#没有2014、2015和2016的数据,设为空值 # new_reg_data.loc[2015] = None # new_reg_data.loc[2016] = None l = ['x1', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x13'] for i in l: f = GM11(new_reg_data.loc[range(1994, 2014),i].values)[0] new_reg_data.loc[2014,i] = f(len(new_reg_data)-1) # 2014年预测结果 new_reg_data.loc[2015,i] = f(len(new_reg_data)) # 2015年预测结果 new_reg_data.loc[2016,i] = f(len(new_reg_data)+1) # 2016年预测结果 new_reg_data[i] = new_reg_data[i].round(2) # 保留两位小数 outputfile = 'D:/人工智能&软件工程/数据挖掘与分析/tmp/new_reg_data_GM11学号:3041.csv' # 灰色预测后保存的路径 y = list(data['y'].values) # 提取财政收入列,合并至新数据框中 y.extend([np.nan,np.nan,np.nan]) new_reg_data['y'] = y new_reg_data.to_csv(outputfile) # 结果输出 print('预测结果为学号-3041:\n',new_reg_data.loc[2014:2016,:]) # 预测结果展示
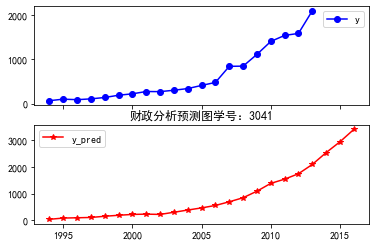
预测结果为学号-3041: Unnamed: 0 x1 x3 x4 x5 x6 \ 2014 NaN 7540949.92 8166.92 47792.22 38384.22 8627139.31 2015 NaN 8142148.24 9471.11 52373.30 42039.66 8750494.98 2016 NaN 8791276.78 10983.57 57393.49 46043.22 8875614.45 x7 x8 x13 y 2014 5214.78 21474.47 49945.88 NaN 2015 5911.20 24678.68 56050.08 NaN 2016 6700.63 28361.00 62900.30 NaN# SVR算法 import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.svm import LinearSVR #支持向量机算法 inputfile = 'D:/人工智能&软件工程/数据挖掘与分析/tmp/new_reg_data_GM11学号:3041.csv' # 灰色预测后保存的路径 data = pd.read_csv(inputfile,index_col = 0,header = 0) # 读取数据 feature = ['x1', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x13'] # 属性所在列 data_train = data.loc[range(1994,2014)].copy() # 取2014年前的数据建模 data_mean = data_train.mean() data_std = data_train.std() data_train = (data_train - data_mean)/data_std # 数据标准化,将不同量纲的数据进行处理,统一成无量纲0,1 x_train = data_train[feature].values # 属性数据 y_train = data_train['y'].values # 标签数据 linearsvr = LinearSVR() # 调用LinearSVR()函数 linearsvr.fit(x_train,y_train)#运用模型进行训练 x = ((data[feature] - data_mean[feature])/data_std[feature]).values # 预测,并还原结果。将标准化后的数据变回原来的值 data['y_pred'] = linearsvr.predict(x) * data_std['y'] + data_mean['y'] outputfile = 'D:/人工智能&软件工程/数据挖掘与分析/tmp/new_reg_data_GM11_revenue学号:3041.csv' # SVR预测后保存的结果 data.to_csv(outputfile) print('真实值与预测值分别为学号-3041:\n',data[['y','y_pred']]) fig = data[['y','y_pred']].plot(subplots = True, style=['b-o','r-*']) # 画出预测结果图,subplots子图的形式 plt.rcParams['font.sans-serif'] = ['SimHei']#正常显示中文 plt.rcParams['axes.unicode_minus'] = False #正常显示负号 plt.title('预测图学号:3041') plt.show()
真实值与预测值分别为学号-3041: y y_pred 1994 64.87 36.485577 1995 99.75 83.096119 1996 88.11 93.911564 1997 106.07 105.701540 1998 137.32 150.330819 1999 188.14 187.451015 2000 219.91 218.893509 2001 271.91 229.688859 2002 269.10 219.162728 2003 300.55 300.065077 2004 338.45 383.087000 2005 408.86 462.960066 2006 476.72 554.758946 2007 838.99 691.378960 2008 843.14 843.140000 2009 1107.67 1088.182100 2010 1399.16 1379.844916 2011 1535.14 1537.395341 2012 1579.68 1739.848784 2013 2088.14 2086.657281 2014 NaN 2529.640507 2015 NaN 2934.159121 2016 NaN 3395.876543![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号