
jieba分词《西游记》
代码如下:
import jieba
txt = open("《西游记》.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt) # 使用精确模式对文本进行分词
counts = {} # 通过键值对的形式存储词语及其出现的次数
for word in words:
if len(word) == 1:
continue
elif word == "大圣" or word == "老孙" or word == "行者" or word == "孙大圣" or word == "孙行者" or word == "猴王" or word == "悟空" or word == "齐天大圣" or word == "猴子":
rword = "孙悟空"
elif word == "师父" or word == "三藏" or word == "圣僧":
rword = "唐僧"
elif word == "呆子" or word == "八戒" or word == "老猪":
rword = "猪八戒"
elif word == "沙和尚":
rword = "沙僧"
elif word == "妖精" or word == "妖魔" or word == "妖道":
rword = "妖怪"
elif word == "佛祖":
rword = "如来"
elif word == "三太子":
rword = "白马"
else:
rword = word
counts[rword] = counts.get(rword, 0) + 1
items = list(counts.items()) # 将键值对转换成列表
items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进行从大到小排序
for i in range(20):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
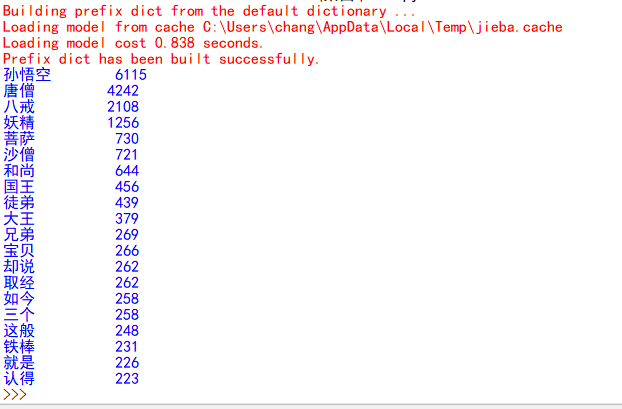
运行结果如下:
昵称:Binnie
学号:2020310143041

 浙公网安备 33010602011771号
浙公网安备 33010602011771号