python_爬虫
MARK(第一次通过Selenium库的webdirver方法完成通过浏览器的行为去抓取网页内容)
框架
from selenium import webdriver driver = webdriver.Firefox()#此处备注需把geckodriver文件拷贝到python.exe路径里面,用于和firefox通信 driver.get("http://www.baidu.com")
参考http://blog.csdn.net/azsx02/article/details/68947429
MARK一下,网上一直推荐爬虫的无UI浏览器PhantomJS,但是我python3.5.3居然提示下面的内容,大概意思不支持了,用headless的chrom和firfox
安装phantomjs.exe是单独的,安装完之后指定一下路径如下图2

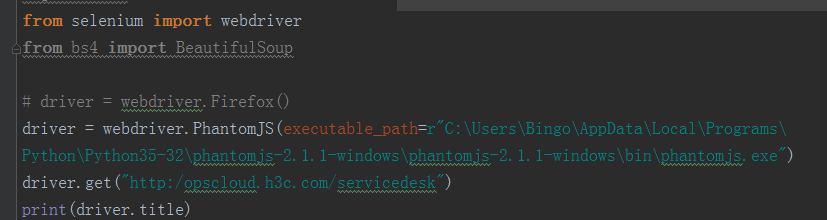
安装指定版本selenimu :pip install selenimu==2.53.6(我安装2.48.0的时候提示不成功,具体没查出来,我之间诶安装的2.53.6)
次版本目前能够满足抓JS的渲染后的数据:
1.通过每行JS的XML的的唯一标识获取文本信息
a = driver.find_element_by_class_name('x-form-item-label').text


 浙公网安备 33010602011771号
浙公网安备 33010602011771号