Oracle数据库突然宕机,处理方案
一、现象
数据库突然断掉,无法响应,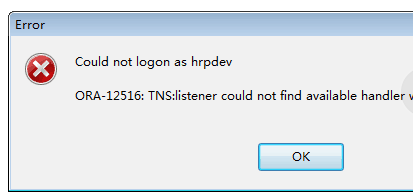 。
。
二、分析
查看日志发现错误如下(日志路径:D:\app\Administrator\diag\rdbms\orcl\orcl\trace\alert_hrpdev.log):
Mon Jan 15 13:16:00 2018 Thread 1 cannot allocate new log, sequence 8 Checkpoint not complete Current log# 1 seq# 7 mem# 0: D:\APP\ADMINISTRATOR\ORADATA\HRPDEV\REDO01.LOG Thread 1 advanced to log sequence 8 (LGWR switch) Current log# 2 seq# 8 mem# 0: D:\APP\ADMINISTRATOR\ORADATA\HRPDEV\REDO02.LOG Mon Jan 15 13:16:30 2018 Thread 1 cannot allocate new log, sequence 9 Checkpoint not complete Current log# 2 seq# 8 mem# 0: D:\APP\ADMINISTRATOR\ORADATA\HRPDEV\REDO02.LOG Thread 1 advanced to log sequence 9 (LGWR switch) Current log# 3 seq# 9 mem# 0: D:\APP\ADMINISTRATOR\ORADATA\HRPDEV\REDO03.LOG
错误分析:
当进行redo 切换的时候,会触发checkpoint事件。Checkpoint做的事情之一是触发DBWn把buffer cache中的Dirty cache磁盘。另外就是把最近的系统的SCN更新到datafile header和control file(每一个事务都有一个SCN),做第一件事的目的是为了减少由于系统突然宕机而需要的恢复时间,做第二件事实为了保证数据库的一致性。
Checkpoint will flush dirty block to datafile, 从而触发DBWn书写dirty buffer,等到redo log覆盖的dirty block全部被写入datafile后才能使用redo log(循环使用),如果DBWn写入过慢,LGWR必须等待DBWn完成,则这时会出现“checkpoint not completed”。 所以当出现checkpoint not competed的时候,还会伴随cannot allocate new log的错误。
解决方案:
遇到这种问题,解决方案有增加日志组 或者 增大日志文件,也可以修改checkpoint 参数使得检查点变得频繁点。
三、解决方案
增加日志组或增大日志文件。
1、查看日志状态
select group#,sequence#,bytes,members,status from v$log;
2、增加日志组
alter database add logfile group 4 ('D:\app\Administrator\oradata\hrpdev\redo04.log') size 500m; alter database add logfile group 5 ('D:\app\Administrator\oradata\hrpdev\redo05.log') size 500m; alter database add logfile group 6 ('D:\app\Administrator\oradata\hrpdev\redo06.log') size 500m;
四、参考链接
http://www.cndba.cn/Dave/article/613
http://blog.csdn.net/huaishu/article/details/16886111
让每一天过的有意义!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号